Τι είναι οι πίνακες ελέγχου και οι αναφορές στο Excel;

Στο Excel, είναι κρίσιμο να κατανοήσουμε τη διαφορά μεταξύ αναφορών και πινάκων εργαλείων για την αποτελεσματική ανάλυση και οπτικοποίηση δεδομένων.
Για να σας βοηθήσει να κατανοήσετε τη στατιστική ανάλυση με το Excel, βοηθάει στην προσομοίωση του Θεωρήματος Κεντρικού ορίου. Σχεδόν δεν ακούγεται σωστά. Πώς μπορεί ένας πληθυσμός που δεν κατανέμεται κανονικά να έχει ως αποτέλεσμα μια κανονικά κατανεμημένη κατανομή δειγματοληψίας;
Για να σας δώσουμε μια ιδέα για το πώς λειτουργεί το Κεντρικό Οριακό Θεώρημα, υπάρχει μια προσομοίωση. Αυτή η προσομοίωση δημιουργεί κάτι σαν μια δειγματοληπτική κατανομή του μέσου όρου για ένα πολύ μικρό δείγμα, με βάση έναν πληθυσμό που δεν κατανέμεται κανονικά. Όπως θα δείτε, παρόλο που ο πληθυσμός δεν είναι μια κανονική κατανομή και παρόλο που το δείγμα είναι μικρό, η δειγματοληπτική κατανομή του μέσου όρου μοιάζει αρκετά με μια κανονική κατανομή.
Φανταστείτε έναν τεράστιο πληθυσμό που αποτελείται από μόλις τρεις βαθμολογίες - 1, 2 και 3 - και το καθένα είναι εξίσου πιθανό να εμφανιστεί σε ένα δείγμα. Φανταστείτε επίσης ότι μπορείτε να επιλέξετε τυχαία ένα δείγμα τριών βαθμολογιών από αυτόν τον πληθυσμό.
Όλα τα πιθανά δείγματα τριών βαθμολογιών (και των μέσων τους) από έναν πληθυσμό που αποτελείται από τις βαθμολογίες 1, 2 και 3
| Δείγμα | Σημαίνω | Δείγμα | Σημαίνω | Δείγμα | Σημαίνω |
| 1,1,1 | 1.00 | 2,1,1 | 1.33 | 3,1,1 | 1,67 |
| 1,1,2 | 1.33 | 2,1,2 | 1,67 | 3,1,2 | 2.00 |
| 1,1,3 | 1,67 | 2,1,3 | 2.00 | 3,1,3 | 2.33 |
| 1,2,1 | 1.33 | 2,2,1 | 1,67 | 3,2,1 | 2.00 |
| 1,2,2 | 1,67 | 2,2,2 | 2.00 | 3,2,2 | 2.33 |
| 1,2,3 | 2.00 | 2,2,3 | 2.33 | 3,2,3 | 2.67 |
| 1,3,1 | 1,67 | 2,3,1 | 2.00 | 3,3,1 | 2.33 |
| 1,3,2 | 2.00 | 2,3,2 | 2.33 | 3,3,2 | 2.67 |
| 1,3,3 | 2.33 | 2,3,3 | 2.67 | 3,3,3 | 3.00 |
Αν κοιτάξετε προσεκτικά τον πίνακα, μπορείτε σχεδόν να δείτε τι πρόκειται να συμβεί στην προσομοίωση. Ο μέσος όρος του δείγματος που εμφανίζεται πιο συχνά είναι 2,00. Τα μέσα του δείγματος που εμφανίζονται λιγότερο συχνά είναι 1,00 και 3,00. Χμμμ. . . .
Στην προσομοίωση, επιλέχθηκε τυχαία μια βαθμολογία από τον πληθυσμό και στη συνέχεια επιλέχθηκαν τυχαία δύο ακόμη. Αυτή η ομάδα των τριών βαθμολογιών είναι ένα δείγμα. Στη συνέχεια υπολογίζετε τον μέσο όρο αυτού του δείγματος. Αυτή η διαδικασία επαναλήφθηκε για συνολικά 60 δείγματα, με αποτέλεσμα 60 μέσα δειγμάτων. Τέλος, γράφετε γραφικά την κατανομή των μέσων του δείγματος.
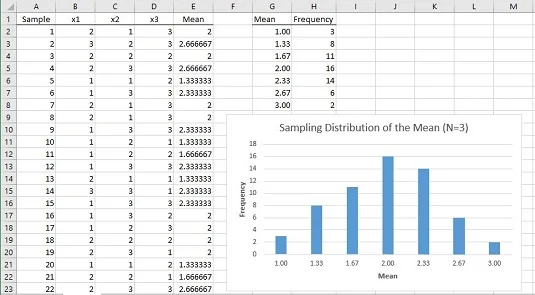
Πώς μοιάζει η προσομοιωμένη δειγματοληπτική κατανομή του μέσου όρου; Η παρακάτω εικόνα δείχνει ένα φύλλο εργασίας που απαντά σε αυτήν την ερώτηση.
Στο φύλλο εργασίας, κάθε σειρά είναι ένα δείγμα. Οι στήλες με τις ετικέτες x1, x2 και x3 δείχνουν τις τρεις βαθμολογίες για κάθε δείγμα. Η στήλη Ε δείχνει τον μέσο όρο για το δείγμα σε κάθε σειρά. Η στήλη G δείχνει όλες τις πιθανές τιμές για τη μέση τιμή του δείγματος και η στήλη Η δείχνει πόσο συχνά εμφανίζεται κάθε μέσος όρος στα 60 δείγματα. Οι στήλες G και H, και το γράφημα, δείχνουν ότι η κατανομή έχει τη μέγιστη συχνότητά της όταν ο μέσος όρος του δείγματος είναι 2,00. Οι συχνότητες μειώνονται καθώς τα μέσα δείγματος απομακρύνονται όλο και περισσότερο από το 2,00.
Το θέμα όλων αυτών είναι ότι ο πληθυσμός δεν μοιάζει σε τίποτα με μια κανονική κατανομή και το μέγεθος του δείγματος είναι πολύ μικρό. Ακόμη και κάτω από αυτούς τους περιορισμούς, η δειγματοληπτική κατανομή του μέσου όρου που βασίζεται σε 60 δείγματα αρχίζει να μοιάζει πολύ με μια κανονική κατανομή.
Τι γίνεται με τις παραμέτρους που προβλέπει το Κεντρικό Οριακό Θεώρημα για τη δειγματοληψία; Ξεκινήστε από τον πληθυσμό. Ο μέσος όρος πληθυσμού είναι 2,00 και η τυπική απόκλιση πληθυσμού είναι 0,67. (Αυτό το είδος πληθυσμού απαιτεί κάποια ελαφρώς φανταχτερά μαθηματικά για τον υπολογισμό των παραμέτρων.)
Στη δειγματοληψία. Ο μέσος όρος των μέσων 60 είναι 1,98 και η τυπική απόκλιση (εκτίμηση του τυπικού σφάλματος του μέσου όρου) είναι 0,48. Αυτοί οι αριθμοί προσεγγίζουν πολύ τις παραμέτρους του Κεντρικού Οριακού Θεωρήματος για τη δειγματοληπτική κατανομή του μέσου όρου, 2,00 (ίσο με τον μέσο όρο του πληθυσμού) και 0,47 (η τυπική απόκλιση, 0,67, διαιρούμενη με την τετραγωνική ρίζα του 3, το μέγεθος του δείγματος) .
Σε περίπτωση που ενδιαφέρεστε να κάνετε αυτήν την προσομοίωση, ακολουθούν τα βήματα:
Επιλέξτε ένα κελί για τον πρώτο σας τυχαία επιλεγμένο αριθμό.
Επιλέξτε το κελί B2.
Χρησιμοποιήστε τη συνάρτηση φύλλου εργασίας RANDBETWEEN για να επιλέξετε 1, 2 ή 3.
Αυτό προσομοιώνει τη σχεδίαση ενός αριθμού από έναν πληθυσμό που αποτελείται από τους αριθμούς 1, 2 και 3 όπου έχετε ίσες πιθανότητες να επιλέξετε κάθε αριθμό. Μπορείτε είτε να επιλέξετε FORMULAS | Math & Trig | RANDBETWEEN και χρησιμοποιήστε το πλαίσιο διαλόγου Function Arguments ή απλώς πληκτρολογήστε =RANDBETWEEN(1,3) στο B2 και πατήστε Enter. Το πρώτο όρισμα είναι ο μικρότερος αριθμός που επιστρέφει το RANDBETWEEN και το δεύτερο όρισμα είναι ο μεγαλύτερος αριθμός.
Επιλέξτε το κελί στα δεξιά του αρχικού κελιού και επιλέξτε έναν άλλο τυχαίο αριθμό μεταξύ 1 και 3. Κάντε αυτό ξανά για έναν τρίτο τυχαίο αριθμό στο κελί στα δεξιά του δεύτερου.
Ο ευκολότερος τρόπος για να γίνει αυτό είναι να συμπληρώσετε αυτόματα τα δύο κελιά στα δεξιά του αρχικού κελιού. Σε αυτό το φύλλο εργασίας, αυτά τα δύο κελιά είναι τα C2 και D2.
Θεωρήστε αυτά τα τρία κελιά ως δείγμα και υπολογίστε τη μέση τιμή τους στο κελί στα δεξιά του τρίτου κελιού.
Ο ευκολότερος τρόπος για να το κάνετε αυτό είναι απλώς πληκτρολογήστε =AVERAGE(B2:D2) στο κελί E2 και πατήστε Enter.
Επαναλάβετε αυτή τη διαδικασία για όσα δείγματα θέλετε να συμπεριλάβετε στην προσομοίωση. Κάθε σειρά να αντιστοιχεί σε ένα δείγμα.
Εδώ χρησιμοποιήθηκαν 60 δείγματα. Ο γρήγορος και εύκολος τρόπος για να το κάνετε αυτό είναι να επιλέξετε την πρώτη σειρά από τρεις τυχαία επιλεγμένους αριθμούς και τον μέσο όρο τους και, στη συνέχεια, να συμπληρώσετε αυτόματα τις υπόλοιπες σειρές. Το σύνολο των μέσων δειγμάτων στη στήλη Ε είναι η προσομοιωμένη κατανομή δειγματοληψίας του μέσου όρου. Χρησιμοποιήστε το AVERAGE και το STDEV.P για να βρείτε τη μέση και τυπική απόκλιση.
Για να δείτε πώς μοιάζει αυτή η προσομοιωμένη κατανομή δειγματοληψίας, χρησιμοποιήστε τη συνάρτηση πίνακα FREQUENCY στο μέσο δείγματος στη στήλη Ε. Ακολουθήστε τα εξής βήματα:
Εισαγάγετε τις πιθανές τιμές του μέσου όρου του δείγματος σε έναν πίνακα.
Μπορείτε να χρησιμοποιήσετε τη στήλη G για αυτό. Μπορείτε να εκφράσετε τις πιθανές τιμές του μέσου όρου του δείγματος σε μορφή κλασμάτων (3/3, 4/3, 5/3, 6/3, 7/3, 8/3 και 9/3) όπως αυτές που εισήχθησαν στα κελιά G2 έως G8. Το Excel τα μετατρέπει σε δεκαδική μορφή. Βεβαιωθείτε ότι αυτά τα κελιά είναι σε μορφή Number.
Επιλέξτε έναν πίνακα για τις συχνότητες των πιθανών τιμών του μέσου όρου του δείγματος.
Μπορείτε να χρησιμοποιήσετε τη στήλη H για να κρατήσετε τις συχνότητες, επιλέγοντας κελιά H2 έως H8.
Από το μενού Στατιστικές Συναρτήσεις, επιλέξτε ΣΥΧΝΟΤΗΤΑ για να ανοίξετε το παράθυρο διαλόγου Επιχειρήματα συνάρτησης για ΣΥΧΝΟΤΗΤΑ
Στο παράθυρο διαλόγου Επιχειρήματα συνάρτησης, εισαγάγετε τις κατάλληλες τιμές για τα ορίσματα.
Στο πλαίσιο Data_array, εισαγάγετε τα κελιά που συγκρατούν τα μέσα δείγματος. Σε αυτό το παράδειγμα, αυτό είναι το E2:E61.
Προσδιορίστε τον πίνακα που κρατά τις πιθανές τιμές του μέσου όρου του δείγματος.
Το FREQUENCY κρατά αυτόν τον πίνακα στο πλαίσιο Bins_array. Για αυτό το φύλλο εργασίας, το G2:G8 πηγαίνει στο πλαίσιο Bins_array. Αφού προσδιορίσετε και τους δύο πίνακες, το πλαίσιο διαλόγου Επιχειρήματα συνάρτησης εμφανίζει τις συχνότητες μέσα σε ένα ζεύγος αγκύλων.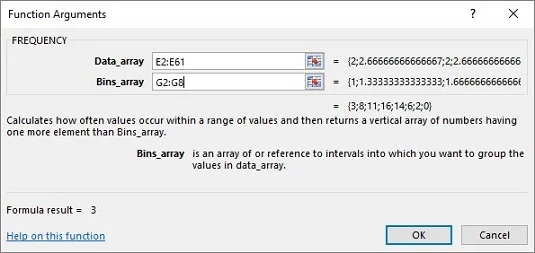
Πατήστε Ctrl+Shift+Enter για να κλείσετε το πλαίσιο διαλόγου Function Arguments και να εμφανίσετε τις συχνότητες.
Χρησιμοποιήστε αυτόν τον συνδυασμό πλήκτρων επειδή η ΣΥΧΝΟΤΗΤΑ είναι μια συνάρτηση πίνακα.
Τέλος, με τονισμένο το H2:H8, επιλέξτε Εισαγωγή | Προτεινόμενα γραφήματα και επιλέξτε τη διάταξη Clustered Column για να δημιουργήσετε το γράφημα των συχνοτήτων. Το γράφημά σας θα φαίνεται πιθανότατα κάπως διαφορετικό από το δικό μου, επειδή πιθανότατα θα καταλήξετε με διαφορετικό τυχαίο αριθμό.
Παρεμπιπτόντως, το Excel επαναλαμβάνει τη διαδικασία τυχαίας επιλογής κάθε φορά που κάνετε κάτι που αναγκάζει το Excel να υπολογίσει ξανά το φύλλο εργασίας. Το αποτέλεσμα είναι ότι οι αριθμοί μπορούν να αλλάξουν καθώς εργάζεστε με αυτό. (Δηλαδή, εκτελείτε ξανά την προσομοίωση.) Για παράδειγμα, εάν επιστρέψετε και συμπληρώσετε ξανά αυτόματα μία από τις σειρές, οι αριθμοί αλλάζουν και το γράφημα αλλάζει.
Στο Excel, είναι κρίσιμο να κατανοήσουμε τη διαφορά μεταξύ αναφορών και πινάκων εργαλείων για την αποτελεσματική ανάλυση και οπτικοποίηση δεδομένων.
Ανακαλύψτε πότε να χρησιμοποιήσετε το OneDrive για επιχειρήσεις και πώς μπορείτε να επωφεληθείτε από τον αποθηκευτικό χώρο των 1 TB.
Ο υπολογισμός του αριθμού ημερών μεταξύ δύο ημερομηνιών είναι κρίσιμος στον επιχειρηματικό κόσμο. Μάθετε πώς να χρησιμοποιείτε τις συναρτήσεις DATEDIF και NETWORKDAYS στο Excel για ακριβείς υπολογισμούς.
Ανακαλύψτε πώς να ανανεώσετε γρήγορα τα δεδομένα του συγκεντρωτικού πίνακα στο Excel με τέσσερις αποτελεσματικές μεθόδους.
Μάθετε πώς μπορείτε να χρησιμοποιήσετε μια μακροεντολή Excel για να αποκρύψετε όλα τα ανενεργά φύλλα εργασίας, βελτιώνοντας την οργάνωση του βιβλίου εργασίας σας.
Ανακαλύψτε τις Ιδιότητες πεδίου MS Access για να μειώσετε τα λάθη κατά την εισαγωγή δεδομένων και να διασφαλίσετε την ακριβή καταχώρηση πληροφοριών.
Ανακαλύψτε πώς να χρησιμοποιήσετε το εργαλείο αυτόματης σύνοψης στο Word 2003 για να συνοψίσετε εγγραφές γρήγορα και αποτελεσματικά.
Η συνάρτηση PROB στο Excel επιτρέπει στους χρήστες να υπολογίζουν πιθανότητες με βάση δεδομένα και πιθανότητες σχέσης, ιδανική για στατιστική ανάλυση.
Ανακαλύψτε τι σημαίνουν τα μηνύματα σφάλματος του Solver στο Excel και πώς να τα επιλύσετε, βελτιστοποιώντας τις εργασίες σας αποτελεσματικά.
Η συνάρτηση FREQUENCY στο Excel μετράει τις τιμές σε έναν πίνακα που εμπίπτουν σε ένα εύρος ή bin. Μάθετε πώς να την χρησιμοποιείτε για την κατανομή συχνότητας.





