Jak používat příkazy Znovu a Opakovat ve Wordu 2016

Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Při provádění sezónního exponenciálního vyhlazování v Excelu si vzpomeňte na to, jak exponenciální vyhlazování funguje. Používá vzorec, jako je tento, k založení příští prognózy částečně na předchozí skutečné a částečně na předchozí prognóze:
Nová předpověď = (0,3 × předchozí skutečná) + (0,7 × předchozí předpověď)
To představuje vážený průměr dvou předchozích čísel – skutečné a prognózy. Tento konkrétní vzorec dává předpovědi mnohem větší váhu než skutečnosti. Musíte experimentovat s některými s konkrétní základní linií, abyste získali správnou konstantu vyhlazování (to je 0,3 ve vzorci) a správný faktor tlumení (to je 0,7 ve vzorci).
Myšlenka je taková, že jedno časové období na základní linii bude úzce souviset s následujícím časovým obdobím. Pokud by dnešní nejvyšší teplota byla 70°F, museli byste ukázat blížící se studenou frontu, abyste někoho přesvědčili, že zítřejší nejvyšší bude 50°F. Bez dalších, protichůdných informací by vsadili na 70°F. Včera má tendenci předpovídat dnes a dnešek má tendenci předpovídat zítra.
Ale přesuňte se na měsíce. Průměrná teplota daného měsíce mnohem více souvisí s historickým průměrem pro daný měsíc než s průměrnou teplotou předchozího měsíce. Pokud by průměrná denní maxima v květnu byla 70 °F, stále byste se přikláněli k 70 °F za červen, ale než na ni vložíte nějaké peníze, chtěli byste vědět, jaká byla průměrná denní maxima z loňského června.
Takže tady je to, co uděláte: Místo použití jedné vyhlazovací konstanty použijete dvě. Namísto použití pouze jedné konstanty ve spojení s bezprostředně předchozí základní hodnotou, použijete jednu pro předchozí hodnotu (vyhlazení květen, aby bylo možné předpovědět červen) a jednu pro sezónu, která je rok zpět od této (vyhlazení od loňského června do pomoci předpověď příští červen).
Obrázek ukazuje sezónní prodejní základnu a související prognózy v praxi.
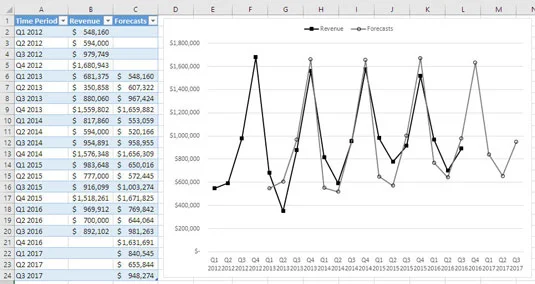
Sezónní předpovědi nemohou začít, dokud neuplyne jedna sekvence základních sezón.
Všimněte si, jak tržby neustále rostou během třetího čtvrtletí každého roku a jak rostou během čtvrtého čtvrtletí. Poté dno vypadne během prvního a druhého čtvrtletí. Obrázek také ukazuje předpovědi, které zachytily sezónní vzorec ve vyhlazovací rovnici, díky čemuž jsou předpovědi mnohem přesnější.
Co kdybyste použili jednoduché exponenciální vyhlazování? Obrázek přináší některé špatné zprávy.
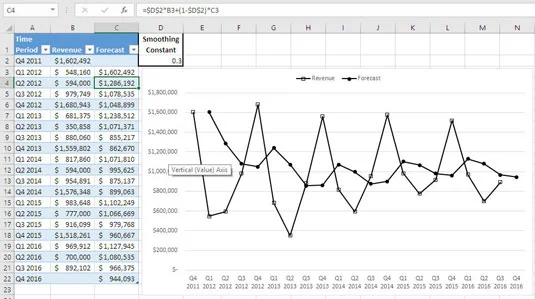
Předpovědi plynule procházejí signálem v základní linii.
Zde je vyhlazovací konstanta 0,3 a předpovědi jsou relativně necitlivé na výkyvy skutečných hodnot od základní linie. Předpovědi přikyvují na vrcholy a údolí na základní linii, ale je to odmítavý druh přikývnutí.
Co kdybyste zvýšili vyhlazovací konstantu tak, aby prognózy více sledovaly skutečné hodnoty, než je vyhlazovaly? Tato situace je ukázána zde, kde konstanta vyhlazování je 0,7.
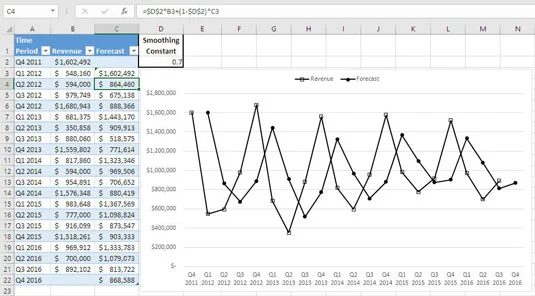
Prognózy jsou pozdě, aby odrážely změny v základní linii.
Vrcholy a údolí jsou znázorněny jasněji — ale zaostávají o jedno období za svým skutečným výskytem. Porovnejte poslední údaj a jeho opožděné předpovědi s prvním číslem a jeho včasnými předpověďmi. Předpovědi na obrázku 18-1 se mohou objevit včas, protože věnují pozornost tomu, co se stalo minulý rok. A ukázat se je 85 procent života.
Následující obrázek ukazuje, jak můžete kombinovat komponenty, abyste získali předpovědní hodnotu. Nebojte se, zdroj komponent a co znamenají budou jasné, když budete procházet vývojem sezónní předpovědi.
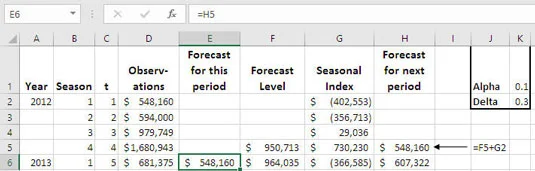
Sezónní vlivy jsou nad (pozitivní hodnoty) a pod (negativní hodnoty) současnou celkovou úrovní základní linie.
Vzorec v buňce F5 udává úroveň základní linie ke 4. čtvrtletí 2012. Vzorec je:
=AVERAGE(D2:D5)
Na začátku procesu vyhlazování je to náš nejlepší odhad aktuální úrovně základní linie. Je to pouze průměr čtyř čtvrtletních výsledků tržeb za rok 2012. Je to analogické použití prvního pozorování jako první prognózy v jednoduchém exponenciálním vyhlazování.
Z prozkoumání vzorce v buňce H5:
=F5+G2
můžete vidět, že předpověď pro 1. čtvrtletí roku 2013 je součtem dvou veličin:
Každá předpověď ve sloupcích E a H je součtem úrovně předpovědi základní linie a vlivu sezóny z předchozího roku. Dobrá kontrola zdravého rozumu porovná sezónní předpovědi vyhlazování na prvním obrázku s běžnými předpovědi vyhlazování na dalších dvou obrázcích.
Je jasné, že pro vás bude lepší, když dokážete odhadnout sezónní efekt dříve, než k němu dojde. To je to, co se děje na posledním obrázku, který kombinuje úroveň, kterou lze přiřadit sezóně, s obecnou úrovní základní linie, aby se získala předpověď aktuální sezóny před tím, než se uskuteční další instance sezóny.
To je důvod, proč dát předpověď na další období do sloupce H a na aktuální období do sloupce E. Díky tomu si zapamatujete, že předpověď na dané období můžete sestavit na konci předchozího období. Všimněte si například, že buňka H5 obsahuje předpověď na další období, buňka E6 má předpověď pro aktuální období a obě se rovnají 548 160 USD.
Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Naučte se, jak efektivně změnit stav buněk v Excelu 2010 z uzamčených na odemčené nebo z neskrytého na skrytý s naším podrobným průvodcem.
Zjistěte, jak efektivně využít překladové nástroje v Office 2016 pro překlad slov a frází. Překlad Gizmo vám pomůže překládat text s lehkostí.
Šablona ve Wordu šetří čas a usnadňuje vytváření dokumentů. Zjistěte, jak efektivně používat šablony ve Wordu 2013.
Zjistěte, jak si vytvořit e-mailová upozornění ve SharePointu a zůstat informováni o změnách v dokumentech a položkách.
Objevte skvělé funkce SharePoint Online, včetně tvorby a sdílení dokumentů a typů obsahu pro efektivnější správu dat.
Zjistěte, jak vypočítat fiskální čtvrtletí v Excelu pro různá data s použitím funkce CHOOSE.
Zjistěte, jak vytvořit hypertextový odkaz v PowerPointu, který vám umožní pohodlně navigovat mezi snímky. Použijte náš návod na efektivní prezentace.
Uložili jste nedávno svůj dokument? Náš návod vám ukáže, jak zobrazit starší verze dokumentu v aplikaci Word 2016.
Jak přiřadit makra vlastní kartě na pásu karet nebo tlačítku na panelu nástrojů Rychlý přístup. Návod pro Excel 2013.





