A Power Pivot használatához nem kell szakértő adatbázismodellezőnek lennie. De fontos megérteni a kapcsolatokat. Minél jobban megérti, hogyan tárolják és kezelik az adatokat az adatbázisokban, annál hatékonyabban tudja használni a Power Pivotot a jelentéskészítéshez.
A kapcsolat az a mechanizmus, amellyel a különálló táblák kapcsolódnak egymáshoz. A kapcsolatot úgy képzelheti el, mint egy VLOOKUP-ot, amelyben az egyik adattartomány adatait egy másik adattartományban lévő adatokhoz kapcsolja össze index vagy egyedi azonosító használatával. Az adatbázisokban a kapcsolatok ugyanezt teszik, de a képletek írásának gondja nélkül.
A kapcsolatok azért fontosak, mert a legtöbb adat, amellyel dolgozik, egyfajta többdimenziós hierarchiába illeszkedik. Például rendelkezhet egy táblázattal, amely a termékeket vásárló ügyfeleket mutatja. Ezeknek az ügyfeleknek olyan számlákra van szükségük, amelyek számlaszámmal rendelkeznek. Ezeken a számlákon több tranzakciósor szerepel, amelyek felsorolják, hogy mit vásároltak. Ott egy hierarchia létezik.
Most, az egydimenziós táblázatkezelő világban ezeket az adatokat általában egy lapos táblázatban tárolják, mint az itt látható.
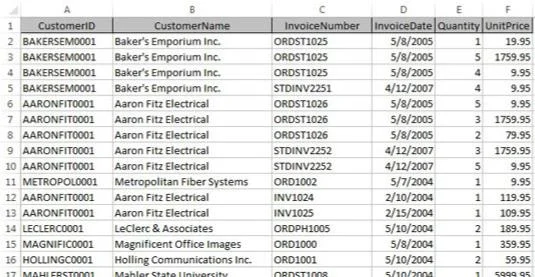
Az adatok egy Excel-táblázatban tárolódnak síktáblás formátumban.
Mivel az ügyfelek egynél több számlával rendelkeznek, az ügyféladatokat (ebben a példában Ügyfélazonosító és Ügyfélnév) meg kell ismételni. Ez problémát okoz, amikor az adatokat frissíteni kell.
Képzelje el például, hogy az Aaron Fitz Electrical cég neve Fitz and Sons Electricalra változik. A táblázatot nézve azt látja, hogy több sorban szerepel a régi név. Gondoskodnia kell arról, hogy a régi cégnevet tartalmazó minden sor frissüljön, hogy tükrözze a változást. A kihagyott sorok nem lesznek megfelelően leképezve a megfelelő ügyfélhez.
Nem lenne logikusabb és hatékonyabb az ügyfél nevét és adatait csak egyszer rögzíteni? Ekkor ahelyett, hogy ugyanazokat az ügyféladatokat kellene többször megírnia, egyszerűen rendelkezhet valamilyen ügyfél-hivatkozási számmal.
Ez az ötlet a kapcsolatok mögött. Elválaszthatja az ügyfeleket a számláktól, mindegyiket a saját táblázataiba helyezheti. Ezután egyedi azonosítóval (például ügyfélazonosítóval) összekapcsolhatja őket.
A következő ábra szemlélteti, hogyan néznek ki ezek az adatok egy relációs adatbázisban. Az adatok három külön táblázatra oszlanak: Ügyfelek, InvoiceHeader és InvoiceDetails. Ezután az egyes táblákat egyedi azonosítók (ebben az esetben Ügyfélazonosító és Számlaszám) segítségével kapcsolják össze.
![Kapcsolatok és Power Pivot]()
Az adatbázisok kapcsolatokat használnak az adatok egyedi táblákban való tárolására, és egyszerűen összekapcsolják ezeket a táblákat egymással.
A Vevők tábla minden ügyfélhez egyedi rekordot tartalmazna. Ily módon, ha meg kell változtatnia egy ügyfél nevét, akkor csak abban a rekordban kell módosítania. Természetesen a való életben az Ügyfelek tábla más attribútumokat is tartalmazna, például az ügyfél címét, telefonszámát és az ügyfél kezdési dátumát. Ezen egyéb attribútumok bármelyike könnyen tárolható és kezelhető a Vevők táblában.
A leggyakoribb kapcsolattípus az egy-a-többhöz kapcsolat. Ez azt jelenti, hogy egy tábla minden rekordjához egy rekord párosítható egy külön tábla több rekordjával. Például egy számlafejléc-tábla egy számlarészlet-táblázathoz kapcsolódik. A számlafejléc táblázat egyedi azonosítóval rendelkezik: Számlaszám. A számlarészlet a számlaszámot fogja használni minden olyan rekordhoz, amely az adott számla részletét reprezentálja.
Egy másik típusú kapcsolattípus az egy-egy kapcsolat: egy tábla minden rekordjához egy és csak egy megfelelő rekord található egy másik táblában. A különböző táblák adatai egy-egy kapcsolatban technikailag egyetlen táblává kombinálhatók.
Végül egy sok a sokhoz viszonyban mindkét tábla rekordjainak tetszőleges számú egyező rekordja lehet a másik táblában. Például egy bank adatbázisa tartalmazhat egy táblázatot a különféle hiteltípusokról (lakáshitel, autóhitel stb.), valamint egy táblázatot az ügyfelekről. Egy ügyfélnek sokféle hitele lehet. Mindeközben az egyes hiteltípusok sok ügyfélnek nyújthatók.









