Kako postaviti upit u bazu podataka MS Access 2019

Naučite kako postaviti upite u Access bazi podataka uz jednostavne korake i savjete za učinkovito filtriranje i sortiranje podataka.
Kako bi vam pomogao razumjeti statističku analizu s Excelom, pomaže simulirati središnji granični teorem. Gotovo ne zvuči kako treba. Kako populacija koja nije normalno raspoređena može rezultirati normalno raspoređenom distribucijom uzorka?
Da biste dobili ideju o tome kako funkcionira središnji granični teorem, postoji simulacija. Ova simulacija stvara nešto poput distribucije uzorka srednje vrijednosti za vrlo mali uzorak, na temelju populacije koja nije normalno raspoređena. Kao što ćete vidjeti, iako populacija nije normalna distribucija, i iako je uzorak mali, distribucija uzorka srednje vrijednosti izgleda prilično kao normalna distribucija.
Zamislite ogromnu populaciju koja se sastoji od samo tri rezultata - 1, 2 i 3 - i svaka je jednako vjerojatno da će se pojaviti u uzorku. Zamislite također da možete nasumično odabrati uzorak od tri rezultata iz ove populacije.
Svi mogući uzorci od tri rezultata (i njihova sredstva) iz populacije koja se sastoji od ocjena 1, 2 i 3
| Uzorak | Zločin | Uzorak | Zločin | Uzorak | Zločin |
| 1,1,1 | 1.00 | 2,1,1 | 1.33 | 3,1,1 | 1.67 |
| 1,1,2 | 1.33 | 2,1,2 | 1.67 | 3,1,2 | 2.00 |
| 1,1,3 | 1.67 | 2,1,3 | 2.00 | 3,1,3 | 2.33 |
| 1,2,1 | 1.33 | 2,2,1 | 1.67 | 3,2,1 | 2.00 |
| 1,2,2 | 1.67 | 2,2,2 | 2.00 | 3,2,2 | 2.33 |
| 1,2,3 | 2.00 | 2,2,3 | 2.33 | 3,2,3 | 2.67 |
| 1,3,1 | 1.67 | 2,3,1 | 2.00 | 3,3,1 | 2.33 |
| 1,3,2 | 2.00 | 2,3,2 | 2.33 | 3,3,2 | 2.67 |
| 1,3,3 | 2.33 | 2,3,3 | 2.67 | 3,3,3 | 3.00 |
Ako pažljivo pogledate tablicu, gotovo možete vidjeti što će se dogoditi u simulaciji. Srednja vrijednost uzorka koja se najčešće pojavljuje je 2,00. Znakovi uzorka koji se najmanje pojavljuju su 1.00 i 3.00. Hmmm. . . .
U simulaciji, rezultat je nasumično odabran iz populacije, a zatim nasumično odabrana još dva. Ta skupina od tri rezultata je uzorak. Zatim izračunate srednju vrijednost tog uzorka. Ovaj postupak je ponovljen za ukupno 60 uzoraka, što je rezultiralo 60 srednjih vrijednosti uzorka. Konačno, crtate distribuciju uzorka srednjih vrijednosti.
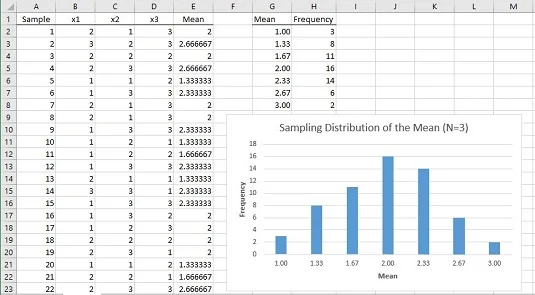
Kako izgleda simulirana distribucija uzorkovanja srednje vrijednosti? Slika ispod prikazuje radni list koji odgovara na ovo pitanje.
U radnom listu svaki redak je uzorak. Stupci označeni s x1, x2 i x3 prikazuju tri rezultata za svaki uzorak. Stupac E prikazuje prosjek za uzorak u svakom retku. Stupac G prikazuje sve moguće vrijednosti za srednju vrijednost uzorka, a stupac H pokazuje koliko se često svaka srednja vrijednost pojavljuje u 60 uzoraka. Stupci G i H, te grafikon, pokazuju da distribucija ima svoju maksimalnu frekvenciju kada je srednja vrijednost uzorka 2,00. Frekvencije se smanjuju jer se uzorak sve više udaljava od 2.00.
Poanta svega ovoga je da populacija ne izgleda ništa kao normalna distribucija i da je veličina uzorka vrlo mala. Čak i pod tim ograničenjima, distribucija uzorkovanja srednje vrijednosti na temelju 60 uzoraka počinje vrlo sličiti normalnoj distribuciji.
Što je s parametrima koje središnji granični teorem predviđa za distribuciju uzorkovanja? Počnite s populacijom. Prosječna populacija je 2,00, a standardna devijacija populacije je 0,67. (Ova vrsta populacije zahtijeva malo otmjenu matematiku za odgonetanje parametara.)
Na distribuciju uzorkovanja. Srednja vrijednost 60 srednjih vrijednosti je 1,98, a njihova standardna devijacija (procjena standardne pogreške srednje vrijednosti) je 0,48. Ti su brojevi usko približni Centralnom graničnom teoremu – predviđeni parametri za distribuciju uzorka srednje vrijednosti, 2,00 (jednako srednjoj populaciji) i ,47 (standardna devijacija, 0,67, podijeljeno s kvadratnim korijenom od 3, veličinom uzorka) .
U slučaju da ste zainteresirani za ovu simulaciju, evo koraka:
Odaberite ćeliju za svoj prvi nasumično odabrani broj.
Odaberite ćeliju B2.
Koristite funkciju radnog lista RANDBETWEEN za odabir 1, 2 ili 3.
Ovo simulira izvlačenje broja iz populacije koja se sastoji od brojeva 1, 2 i 3 gdje imate jednake šanse za odabir svakog broja. Možete odabrati FORMULE | Matematika & Trig | RANDBETWEEN i upotrijebite dijaloški okvir Argumenti funkcije ili jednostavno upišite =RANDBETWEEN(1,3) u B2 i pritisnite Enter. Prvi argument je najmanji broj koji se vraća RANDBETWEEN, a drugi argument je najveći broj.
Odaberite ćeliju desno od izvorne ćelije i odaberite drugi slučajni broj između 1 i 3. Učinite to ponovno za treći slučajni broj u ćeliji desno od drugog.
Najlakši način da to učinite je da automatski ispunite dvije ćelije desno od izvorne ćelije. U ovom radnom listu te dvije ćelije su C2 i D2.
Ove tri ćelije smatrajte uzorkom i izračunajte njihovu srednju vrijednost u ćeliji desno od treće ćelije.
Najlakši način da to učinite je samo upišite =AVERAGE(B2:D2) u ćeliju E2 i pritisnite Enter.
Ponovite ovaj postupak za onoliko uzoraka koliko želite uključiti u simulaciju. Neka svaki red odgovara uzorku.
Ovdje je korišteno 60 uzoraka. Brz i jednostavan način da to učinite je da odaberete prvi redak od tri nasumično odabrana broja i njihovu srednju vrijednost, a zatim automatski popunite preostale retke. Skup srednjih vrijednosti uzorka u stupcu E je simulirana distribucija uzorkovanja srednje vrijednosti. Koristite AVERAGE i STDEV.P da biste pronašli njegovu srednju vrijednost i standardnu devijaciju.
Da biste vidjeli kako izgleda ova simulirana distribucija uzorkovanja, upotrijebite funkciju niza FREQUENCY na uzorku znači u stupcu E. Slijedite ove korake:
Unesite moguće vrijednosti srednje vrijednosti uzorka u niz.
Za to možete koristiti stupac G. Moguće vrijednosti srednje vrijednosti uzorka možete izraziti u obliku frakcija (3/3, 4/3, 5/3, 6/3, 7/3, 8/3 i 9/3) poput onih unesenih u ćelije G2 do G8. Excel ih pretvara u decimalni oblik. Provjerite jesu li te ćelije u formatu brojeva.
Odaberite niz za frekvencije mogućih vrijednosti srednje vrijednosti uzorka.
Možete koristiti stupac H za zadržavanje frekvencija, odabirom ćelija H2 do H8.
Na izborniku Statističke funkcije odaberite FREQUENCY da biste otvorili dijaloški okvir Argumenti funkcije za FREKVENCIJA
U dijaloškom okviru Argumenti funkcije unesite odgovarajuće vrijednosti za argumente.
U okvir Data_array unesite ćelije koje sadrže sredstva uzorka. U ovom primjeru, to je E2:E61.
Identificirajte niz koji sadrži moguće vrijednosti srednje vrijednosti uzorka.
FREQUENCY drži ovaj niz u okviru Bins_array. Za ovaj radni list, G2:G8 ide u okvir Bins_array. Nakon što identificirate oba niza, dijaloški okvir Argumenti funkcije prikazuje frekvencije unutar para vitičastih zagrada.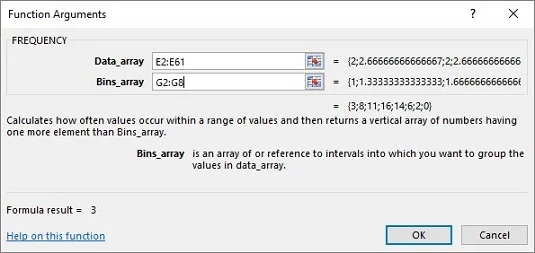
Pritisnite Ctrl+Shift+Enter da zatvorite dijaloški okvir Argumenti funkcije i prikažete frekvencije.
Koristite ovu kombinaciju tipki jer je FREQUENCY funkcija polja.
Na kraju, s istaknutim H2:H8, odaberite Umetni | Preporučeni grafikoni i odaberite raspored klasteriranih stupaca za izradu grafa frekvencija. Vaš će grafikon vjerojatno izgledati nešto drugačije od mog, jer ćete vjerojatno završiti s drugačijim slučajnim brojem.
Usput, Excel ponavlja postupak slučajnog odabira kad god učinite nešto što uzrokuje da Excel ponovno izračuna radni list. Učinak je da se brojevi mogu promijeniti dok to radite. (To jest, ponovno izvodite simulaciju.) Na primjer, ako se vratite i ponovno automatski popunite jedan od redaka, brojevi se mijenjaju i grafikon se mijenja.
Naučite kako postaviti upite u Access bazi podataka uz jednostavne korake i savjete za učinkovito filtriranje i sortiranje podataka.
Tabulatori su oznake položaja u odlomku programa Word 2013 koje određuju kamo će se točka umetanja pomaknuti kada pritisnete tipku Tab. Otkrijte kako prilagoditi tabulatore i optimizirati svoj rad u Wordu.
Word 2010 nudi mnoge načine označavanja i poništavanja odabira teksta. Otkrijte kako koristiti tipkovnicu i miš za odabir blokova. Učinite svoj rad učinkovitijim!
Naučite kako pravilno postaviti uvlaku za odlomak u Wordu 2013 kako biste poboljšali izgled svog dokumenta.
Naučite kako jednostavno otvoriti i zatvoriti svoje Microsoft PowerPoint 2019 prezentacije s našim detaljnim vodičem. Pronađite korisne savjete i trikove!
Saznajte kako crtati jednostavne objekte u PowerPoint 2013 uz ove korisne upute. Uključuje crtanje linija, pravokutnika, krugova i više.
U ovom vodiču vam pokazujemo kako koristiti alat za filtriranje u programu Access 2016 kako biste lako prikazali zapise koji dijele zajedničke vrijednosti. Saznajte više o filtriranju podataka.
Saznajte kako koristiti Excelove funkcije zaokruživanja za prikaz čistih, okruglih brojeva, što može poboljšati čitljivost vaših izvješća.
Zaglavlje ili podnožje koje postavite isto je za svaku stranicu u vašem Word 2013 dokumentu. Otkrijte kako koristiti različita zaglavlja za parne i neparne stranice.
Poboljšajte čitljivost svojih Excel izvješća koristeći prilagođeno oblikovanje brojeva. U ovom članku naučite kako se to radi i koja su najbolja rješenja.








