Kako postaviti upit u bazu podataka MS Access 2019

Naučite kako postaviti upite u Access bazi podataka uz jednostavne korake i savjete za učinkovito filtriranje i sortiranje podataka.
Excel zna kako pomoći kada imate više od dva uzorka. FarKlempt Robotics, Inc., ispituje svoje zaposlenike o njihovoj razini zadovoljstva svojim poslom. Traže programere, menadžere, radnike na održavanju i pisce tehnologije da ocijene zadovoljstvo poslom na ljestvici od 1 (najmanje zadovoljan) do 100 (najzadovoljniji).
U svakoj kategoriji je šest zaposlenika. Slika ispod prikazuje proračunsku tablicu s podacima u stupcima A do D, recima 1-7. Nul hipoteza je da svi uzorci potječu iz iste populacije. Alternativna hipoteza je da nemaju.
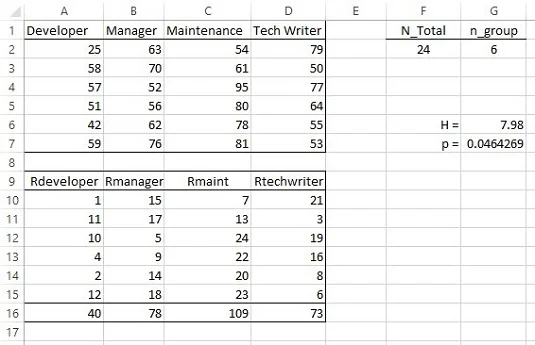
Kruskal-Wallisova jednosmjerna analiza varijance.
Odgovarajući neparametarski test je Kruskal-Wallis-ova jednosmjerna analiza varijance. Započnite rangiranjem svih 24 rezultata uzlaznim redoslijedom. Opet, ako je nulta hipoteza istinita, rangovi bi trebali biti približno jednako raspoređeni po grupama.
Formula za ovu statistiku je
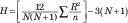
N je ukupan broj bodova, a n broj bodova u svakoj skupini. Da biste olakšali posao, navedite isti broj bodova u svakoj skupini, ali to nije potrebno za ovaj test. R je zbroj rangova u skupini. H je raspoređen približno kao hi-kvadrat s df = brojem skupina — 1, kada je svaki n veći od 5.
Gledajući unatrag na sliku, rangovi podataka nalaze se u recima 9-15 stupaca od A do D. Redak 16 sadrži zbrojeve rangova u svakoj grupi. Definirajte N_Total kao naziv za vrijednost u ćeliji F2, ukupan broj rezultata. Definirajte n_group kao naziv za vrijednost u G2, broj rezultata u svakoj grupi.
Za izračunavanje H upišite
=(12/(N_Ukupno*(N_Ukupno+1)))*(SUMSQ(A16:D16)/n_grupa)-3*(N_Ukupno+1)
u ćeliju G6.
Za test hipoteze upišite
=CHISQ.DIST.RT(G6,3)
u G7. Rezultat je manji od 0,05, pa odbacujete nultu hipotezu.
Naučite kako postaviti upite u Access bazi podataka uz jednostavne korake i savjete za učinkovito filtriranje i sortiranje podataka.
Tabulatori su oznake položaja u odlomku programa Word 2013 koje određuju kamo će se točka umetanja pomaknuti kada pritisnete tipku Tab. Otkrijte kako prilagoditi tabulatore i optimizirati svoj rad u Wordu.
Word 2010 nudi mnoge načine označavanja i poništavanja odabira teksta. Otkrijte kako koristiti tipkovnicu i miš za odabir blokova. Učinite svoj rad učinkovitijim!
Naučite kako pravilno postaviti uvlaku za odlomak u Wordu 2013 kako biste poboljšali izgled svog dokumenta.
Naučite kako jednostavno otvoriti i zatvoriti svoje Microsoft PowerPoint 2019 prezentacije s našim detaljnim vodičem. Pronađite korisne savjete i trikove!
Saznajte kako crtati jednostavne objekte u PowerPoint 2013 uz ove korisne upute. Uključuje crtanje linija, pravokutnika, krugova i više.
U ovom vodiču vam pokazujemo kako koristiti alat za filtriranje u programu Access 2016 kako biste lako prikazali zapise koji dijele zajedničke vrijednosti. Saznajte više o filtriranju podataka.
Saznajte kako koristiti Excelove funkcije zaokruživanja za prikaz čistih, okruglih brojeva, što može poboljšati čitljivost vaših izvješća.
Zaglavlje ili podnožje koje postavite isto je za svaku stranicu u vašem Word 2013 dokumentu. Otkrijte kako koristiti različita zaglavlja za parne i neparne stranice.
Poboljšajte čitljivost svojih Excel izvješća koristeći prilagođeno oblikovanje brojeva. U ovom članku naučite kako se to radi i koja su najbolja rješenja.








