Създаване и управление на шаблони за Word 2019

Научете как да създавате и управлявате шаблони за Word 2019 с нашето ръководство. Оптимизирайте документите си с персонализирани стилове.
За да ви помогне да разберете статистическия анализ с Excel, помага да се симулира централната пределна теорема. Почти не звучи правилно. Как може популация, която не е нормално разпределена, да доведе до нормално разпределено извадково разпределение?
За да ви даде представа как работи централната пределна теорема, има симулация. Тази симулация създава нещо като извадково разпределение на средната стойност за много малка извадка, базирана на популация, която не е нормално разпределена. Както ще видите, въпреки че популацията не е нормално разпределение и въпреки че извадката е малка, извадковото разпределение на средната стойност изглежда доста като нормално разпределение.
Представете си огромна популация, която се състои само от три резултата – 1, 2 и 3 – и всяка от тях е еднакво вероятно да се появи в извадка. Представете си също, че можете да изберете произволно извадка от три резултата от тази популация.
Всички възможни проби от три точки (и техните средства) от популация, състояща се от точки 1, 2 и 3
| Проба | Означава | Проба | Означава | Проба | Означава |
| 1,1,1 | 1.00 | 2,1,1 | 1.33 | 3,1,1 | 1.67 |
| 1,1,2 | 1.33 | 2,1,2 | 1.67 | 3,1,2 | 2.00 |
| 1,1,3 | 1.67 | 2,1,3 | 2.00 | 3,1,3 | 2.33 |
| 1,2,1 | 1.33 | 2,2,1 | 1.67 | 3,2,1 | 2.00 |
| 1,2,2 | 1.67 | 2,2,2 | 2.00 | 3,2,2 | 2.33 |
| 1,2,3 | 2.00 | 2,2,3 | 2.33 | 3,2,3 | 2.67 |
| 1,3,1 | 1.67 | 2,3,1 | 2.00 | 3,3,1 | 2.33 |
| 1,3,2 | 2.00 | 2,3,2 | 2.33 | 3,3,2 | 2.67 |
| 1,3,3 | 2.33 | 2,3,3 | 2.67 | 3,3,3 | 3.00 |
Ако погледнете внимателно таблицата, почти можете да видите какво предстои да се случи в симулацията. Средната извадка, която се появява най-често, е 2,00. Извадката означава, че се появяват най-рядко, са 1.00 и 3.00. Хммм. . . .
При симулацията резултатът беше избран на случаен принцип от популацията и след това бяха избрани на случаен принцип още две. Тази група от три точки е извадка. След това изчислявате средната стойност на тази извадка. Този процес се повтаря за общо 60 проби, което води до 60 средни проби. Накрая изобразявате графика на разпределението на извадковите средни стойности.
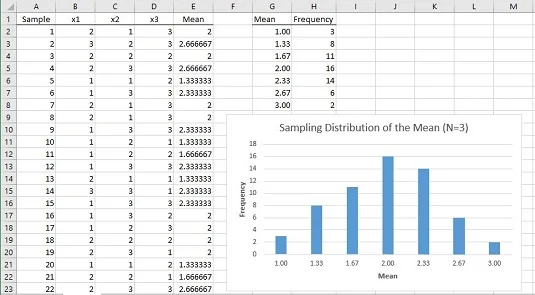
Как изглежда симулираното извадково разпределение на средната стойност? Изображението по-долу показва работен лист, който отговаря на този въпрос.
В работния лист всеки ред е извадка. Колоните, обозначени с x1, x2 и x3, показват трите точки за всяка проба. Колона E показва средната стойност за пробата във всеки ред. Колона G показва всички възможни стойности за средната стойност на извадката, а колона H показва колко често всяка средна стойност се появява в 60-те проби. Колони G и H и графиката показват, че разпределението има максимална честота, когато средната стойност на извадката е 2,00. Честотите се отклоняват, тъй като извадковите средства се отдалечават все повече и повече от 2.00.
Смисълът на всичко това е, че популацията не изглежда като нормално разпределение и размерът на извадката е много малък. Дори при тези ограничения, разпределението на извадката на средната стойност на базата на 60 проби започва да изглежда много като нормално разпределение.
Какво ще кажете за параметрите, които централната пределна теорема предвижда за разпределението на извадката? Започнете с населението. Средната стойност на населението е 2,00, а стандартното отклонение на населението е 0,67. (Този вид население изисква малко сложна математика, за да разберете параметрите.)
Към разпределението на пробите. Средната стойност на средните 60 е 1,98, а тяхното стандартно отклонение (оценка на стандартната грешка на средната стойност) е 0,48. Тези числа се доближават доблизо до централната пределна теорема – прогнозирани параметри за извадковото разпределение на средната стойност, 2,00 (равно на средната стойност на популацията) и 0,47 (стандартното отклонение, 0,67, разделено на корен квадратен от 3, размерът на извадката) .
В случай, че се интересувате от тази симулация, ето стъпките:
Изберете клетка за първото си произволно избрано число.
Изберете клетка B2.
Използвайте функцията на работния лист RANDBETWEEN, за да изберете 1, 2 или 3.
Това симулира изтеглянето на число от популация, състояща се от числата 1, 2 и 3, където имате равен шанс да изберете всяко число. Можете да изберете или ФОРМУЛИ | Математика и триг. | RANDBETWEEN и използвайте диалоговия прозорец Аргументи на функцията или просто въведете =RANDBETWEEN(1,3) в B2 и натиснете Enter. Първият аргумент е най-малкото число, което RANDBETWEEN връща, а вторият аргумент е най-голямото число.
Изберете клетката вдясно от оригиналната клетка и изберете друго произволно число между 1 и 3. Направете това отново за трето произволно число в клетката вдясно от второто.
Най-лесният начин да направите това е да попълните автоматично двете клетки вдясно от оригиналната клетка. В този работен лист тези две клетки са C2 и D2.
Считайте тези три клетки за извадка и изчислете тяхната средна стойност в клетката вдясно от третата клетка.
Най-лесният начин да направите това е просто да въведете =AVERAGE(B2:D2) в клетка E2 и да натиснете Enter.
Повторете този процес за толкова проби, колкото искате да включите в симулацията. Всеки ред трябва да съответства на извадка.
Тук са използвани 60 проби. Бързият и лесен начин да направите това е да изберете първия ред от три произволно избрани числа и тяхната средна стойност и след това автоматично да попълните останалите редове. Наборът от средни стойности на извадката в колона E е симулираното разпределение на извадката на средната стойност. Използвайте AVERAGE и STDEV.P, за да намерите неговото средно и стандартно отклонение.
За да видите как изглежда това симулирано разпределение на извадката, използвайте функцията на масива FREQUENCY на извадката означава в колона E. Следвайте тези стъпки:
Въведете възможните стойности на средната извадка в масив.
Можете да използвате колона G за това. Можете да изразите възможните стойности на средната стойност на пробата във фракционна форма (3/3, 4/3, 5/3, 6/3, 7/3, 8/3 и 9/3) като тези, въведени в клетките G2 до G8. Excel ги преобразува в десетична форма. Уверете се, че тези клетки са в числов формат.
Изберете масив за честотите на възможните стойности на средната стойност на извадката.
Можете да използвате колона H, за да задържите честотите, като изберете клетки от H2 до H8.
От менюто Статистически функции изберете ЧЕСТОТА, за да отворите диалоговия прозорец Аргументи на функцията за ЧЕСТОТА
В диалоговия прозорец Аргументи на функцията въведете подходящите стойности за аргументите.
В полето Data_array въведете клетките, които съдържат примерните средства. В този пример това е E2:E61.
Идентифицирайте масива, който съдържа възможните стойности на средната стойност на извадката.
FREQUENCY съхранява този масив в полето Bins_array. За този работен лист G2:G8 влиза в полето Bins_array. След като идентифицирате двата масива, диалоговият прозорец Аргументи на функцията показва честотите в двойка къдрави скоби.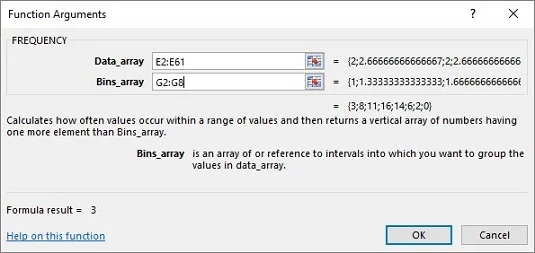
Натиснете Ctrl+Shift+Enter, за да затворите диалоговия прозорец Аргументи на функцията и да покажете честотите.
Използвайте тази комбинация от натискане на клавиши, защото FREQUENCY е функция от масив.
Накрая, с маркирано H2:H8, изберете Insert | Препоръчителни диаграми и изберете оформлението на клъстерирана колона, за да създадете графиката на честотите. Вашата графика вероятно ще изглежда малко по-различно от моята, защото вероятно ще се окажете с различно произволно число.
Между другото, Excel повтаря процеса на произволен избор всеки път, когато направите нещо, което кара Excel да преизчисли работния лист. Ефектът е, че числата могат да се променят, докато работите през това. (Т.е. стартирате отново симулацията.) Например, ако се върнете назад и автоматично попълните един от редовете отново, числата се променят и графиката се променя.
Научете как да създавате и управлявате шаблони за Word 2019 с нашето ръководство. Оптимизирайте документите си с персонализирани стилове.
Научете как да настроите отстъп на абзаци в Word 2016, за да подобрите визуалната комуникация на вашите документи.
Как да блокирам Microsoft Word да отваря файлове в режим само за четене в Windows Microsoft Word отваря файлове в режим само за четене, което прави невъзможно редактирането им? Не се притеснявайте, методите са по-долу
Как да коригирате грешки при отпечатването на неправилни документи на Microsoft Word Грешките при отпечатването на документи на Word с променени шрифтове, разхвърляни абзаци, липсващ текст или изгубено съдържание са доста чести. Въпреки това недейте
Ако сте използвали писалката или маркера, за да рисувате върху слайдовете на PowerPoint по време на презентация, можете да запазите чертежите за следващата презентация или да ги изтриете, така че следващия път, когато го покажете, да започнете с чисти слайдове на PowerPoint. Следвайте тези инструкции, за да изтриете чертежи с писалка и маркери: Изтриване на линии една в […]
Библиотеката със стилове съдържа CSS файлове, файлове с разширяем език на стиловия език (XSL) и изображения, използвани от предварително дефинирани главни страници, оформления на страници и контроли в SharePoint 2010. За да намерите CSS файлове в библиотеката със стилове на сайт за публикуване: Изберете Действия на сайта→Преглед Цялото съдържание на сайта. Появява се съдържанието на сайта. Библиотеката Style се намира в […]
Не затрупвайте аудиторията си с огромни числа. В Microsoft Excel можете да подобрите четливостта на вашите табла за управление и отчети, като форматирате числата си така, че да се показват в хиляди или милиони.
Научете как да използвате инструменти за социални мрежи на SharePoint, които позволяват на индивиди и групи да общуват, да си сътрудничат, споделят и да се свързват.
Юлианските дати често се използват в производствени среди като времеви печат и бърза справка за партиден номер. Този тип кодиране на дата позволява на търговците на дребно, потребителите и обслужващите агенти да идентифицират кога е произведен продуктът и по този начин възрастта на продукта. Юлианските дати се използват и в програмирането, военните и астрономията. Различно […]
Можете да създадете уеб приложение в Access 2016. И така, какво всъщност е уеб приложение? Е, уеб означава, че е онлайн, а приложението е просто съкращение от „приложение“. Персонализирано уеб приложение е онлайн приложение за база данни, достъпно от облака с помощта на браузър. Вие създавате и поддържате уеб приложението в настолната версия […]








