Създаване и управление на шаблони за Word 2019

Научете как да създавате и управлявате шаблони за Word 2019 с нашето ръководство. Оптимизирайте документите си с персонализирани стилове.
Excel знае как да помогне, когато имате повече от две проби. FarKlempt Robotics, Inc., проучва служителите си за тяхното ниво на удовлетвореност от работата си. Те молят разработчиците, мениджърите, работниците по поддръжката и техническите писатели да оценят удовлетвореността от работата по скала от 1 (най-малко удовлетворени) до 100 (най-доволни).
Във всяка категория са по шест служители. Изображението по-долу показва електронна таблица с данните в колони от A до D, редове 1–7. Нулевата хипотеза е, че всички проби идват от една и съща популация. Алтернативната хипотеза е, че не го правят.
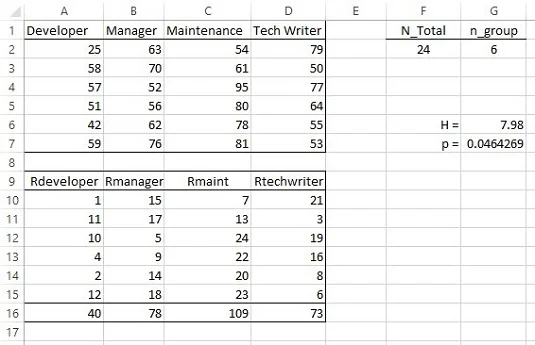
Еднопосочен дисперсионен анализ на Крускал-Уолис.
Подходящият непараметричен тест е еднопосочният дисперсионен анализ на Крускал-Уолис. Започнете, като класирате всички 24 резултата във възходящ ред. Отново, ако нулевата хипотеза е вярна, ранговете трябва да бъдат разпределени приблизително еднакво между групите.
Формулата за тази статистика е
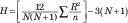
N е общият брой точки, а n е броят на точките във всяка група. За да улесните нещата, посочвате еднакъв брой точки във всяка група, но това не е необходимо за този тест. R е сборът от ранговете в група. H се разпределя приблизително като хи-квадрат с df = брой групи — 1, когато всяко n е по-голямо от 5.
Поглеждайки назад към изображението, ранговете на данните са в редове 9–15 от колони от A до D. Ред 16 съдържа сумите от ранговете във всяка група. Дефинирайте N_Total като име за стойността в клетка F2, общия брой резултати. Дефинирайте n_group като име за стойността в G2, броя на резултатите във всяка група.
За да изчислите H , въведете
=(12/(N_Общо*(N_Общо+1)))*(SUMSQ(A16:D16)/n_група)-3*(N_Общо+1)
в клетка G6.
За теста на хипотезата въведете
=CHISQ.DIST.RT(G6,3)
в G7. Резултатът е по-малък от .05, така че отхвърляте нулевата хипотеза.
Научете как да създавате и управлявате шаблони за Word 2019 с нашето ръководство. Оптимизирайте документите си с персонализирани стилове.
Научете как да настроите отстъп на абзаци в Word 2016, за да подобрите визуалната комуникация на вашите документи.
Как да блокирам Microsoft Word да отваря файлове в режим само за четене в Windows Microsoft Word отваря файлове в режим само за четене, което прави невъзможно редактирането им? Не се притеснявайте, методите са по-долу
Как да коригирате грешки при отпечатването на неправилни документи на Microsoft Word Грешките при отпечатването на документи на Word с променени шрифтове, разхвърляни абзаци, липсващ текст или изгубено съдържание са доста чести. Въпреки това недейте
Ако сте използвали писалката или маркера, за да рисувате върху слайдовете на PowerPoint по време на презентация, можете да запазите чертежите за следващата презентация или да ги изтриете, така че следващия път, когато го покажете, да започнете с чисти слайдове на PowerPoint. Следвайте тези инструкции, за да изтриете чертежи с писалка и маркери: Изтриване на линии една в […]
Библиотеката със стилове съдържа CSS файлове, файлове с разширяем език на стиловия език (XSL) и изображения, използвани от предварително дефинирани главни страници, оформления на страници и контроли в SharePoint 2010. За да намерите CSS файлове в библиотеката със стилове на сайт за публикуване: Изберете Действия на сайта→Преглед Цялото съдържание на сайта. Появява се съдържанието на сайта. Библиотеката Style се намира в […]
Не затрупвайте аудиторията си с огромни числа. В Microsoft Excel можете да подобрите четливостта на вашите табла за управление и отчети, като форматирате числата си така, че да се показват в хиляди или милиони.
Научете как да използвате инструменти за социални мрежи на SharePoint, които позволяват на индивиди и групи да общуват, да си сътрудничат, споделят и да се свързват.
Юлианските дати често се използват в производствени среди като времеви печат и бърза справка за партиден номер. Този тип кодиране на дата позволява на търговците на дребно, потребителите и обслужващите агенти да идентифицират кога е произведен продуктът и по този начин възрастта на продукта. Юлианските дати се използват и в програмирането, военните и астрономията. Различно […]
Можете да създадете уеб приложение в Access 2016. И така, какво всъщност е уеб приложение? Е, уеб означава, че е онлайн, а приложението е просто съкращение от „приложение“. Персонализирано уеб приложение е онлайн приложение за база данни, достъпно от облака с помощта на браузър. Вие създавате и поддържате уеб приложението в настолната версия […]








