Ako zmeniť pozadie v PowerPointe 2019

Naučte sa, ako jednoducho zmeniť pozadie v PowerPointe 2019, aby vaše prezentácie pôsobili pútavo a profesionálne. Získajte tipy na plnú farbu, prechod, obrázky a vzory.
Na používanie doplnku Power Pivot nemusíte byť skúseným databázovým modelárom. Ale je dôležité pochopiť vzťahy. Čím lepšie pochopíte, ako sa údaje ukladajú a spravujú v databázach, tým efektívnejšie využijete Power Pivot na vytváranie prehľadov.
Vzťah je mechanizmus, ktorým sú jednotlivé tabuľky vzťahujúce sa k sebe navzájom. Vzťah si môžete predstaviť ako VLOOKUP, v ktorom spájate údaje v jednom rozsahu údajov s údajmi v inom rozsahu údajov pomocou indexu alebo jedinečného identifikátora. V databázach robia vzťahy to isté, ale bez problémov s písaním vzorcov.
Vzťahy sú dôležité, pretože väčšina údajov, s ktorými pracujete, zapadá do viacrozmernej hierarchie druhov. Môžete mať napríklad tabuľku zobrazujúcu zákazníkov, ktorí kupujú produkty. Títo zákazníci vyžadujú faktúry s číslami faktúr. Tieto faktúry obsahujú viacero riadkov transakcií, ktoré uvádzajú, čo kúpili. Existuje tam hierarchia.
Teraz, v jednorozmernom tabuľkovom svete, by sa tieto údaje zvyčajne ukladali do plochej tabuľky, ako je tá, ktorá je tu zobrazená.
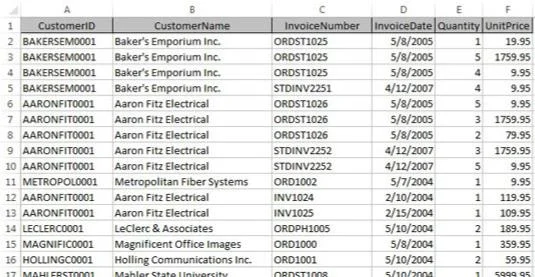
Údaje sa ukladajú v tabuľkovom hárku programu Excel pomocou formátu plochej tabuľky.
Pretože zákazníci majú viac ako jednu faktúru, informácie o zákazníkovi (v tomto príklade CustomerID a CustomerName) sa musia opakovať. To spôsobuje problém, keď je potrebné tieto údaje aktualizovať.
Predstavte si napríklad, že názov spoločnosti Aaron Fitz Electrical sa zmení na Fitz and Sons Electrical. Pri pohľade na tabuľku vidíte, že viaceré riadky obsahujú starý názov. Mali by ste zabezpečiť, aby sa každý riadok obsahujúci starý názov spoločnosti aktualizoval tak, aby odrážal zmenu. Všetky riadky, ktoré vynecháte, sa nebudú správne mapovať späť na správneho zákazníka.
Nebolo by logickejšie a efektívnejšie zaznamenať meno a informácie o zákazníkovi iba raz? Potom, namiesto toho, aby ste museli opakovane písať rovnaké informácie o zákazníkovi, môžete jednoducho mať nejakú formu zákazníckeho referenčného čísla.
Toto je myšlienka vzťahov. Zákazníkov môžete oddeliť od faktúr, pričom každého umiestnite do vlastných tabuliek. Potom môžete použiť jedinečný identifikátor (napríklad CustomerID), aby ste ich spojili.
Nasledujúci obrázok ilustruje, ako by tieto údaje vyzerali v relačnej databáze. Údaje by boli rozdelené do troch samostatných tabuliek: Zákazníci, Hlavička faktúry a Podrobnosti faktúry. Každá tabuľka by potom bola spojená pomocou jedinečných identifikátorov (v tomto prípade ID zákazníka a číslo faktúry).

Databázy používajú vzťahy na ukladanie údajov do jedinečných tabuliek a jednoducho tieto tabuľky navzájom spájajú.
Tabuľka Zákazníci by obsahovala jedinečný záznam pre každého zákazníka. Týmto spôsobom, ak potrebujete zmeniť meno zákazníka, budete musieť vykonať zmenu iba v tomto zázname. Samozrejme, v reálnom živote by tabuľka Zákazníci obsahovala ďalšie atribúty, ako je adresa zákazníka, telefónne číslo zákazníka a dátum začiatku zákazníka. Ktorýkoľvek z týchto ďalších atribútov možno tiež jednoducho uložiť a spravovať v tabuľke Zákazníci.
Najbežnejším typom vzťahu je vzťah jeden k mnohým . To znamená, že pre každý záznam v jednej tabuľke môže byť jeden záznam priradený k mnohým záznamom v samostatnej tabuľke. Napríklad tabuľka hlavičky faktúry súvisí s tabuľkou podrobností faktúry. Tabuľka hlavičky faktúry má jedinečný identifikátor: Číslo faktúry. V detaile faktúry sa použije Číslo faktúry pre každý záznam predstavujúci detail danej faktúry.
Ďalším typom vzťahu je vzťah jedna k jednej : Pre každý záznam v jednej tabuľke je v inej tabuľke iba jeden zodpovedajúci záznam. Údaje z rôznych tabuliek vo vzťahu jedna k jednej možno technicky spojiť do jednej tabuľky.
Nakoniec, vo vzťahu many-to-many môžu mať záznamy v oboch tabuľkách ľubovoľný počet zhodných záznamov v druhej tabuľke. Napríklad databáza v banke môže obsahovať tabuľku rôznych typov úverov (úver na bývanie, úver na auto atď.) a tabuľku zákazníkov. Klient môže mať viacero druhov pôžičiek. Medzitým môže byť každý typ úveru poskytnutý mnohým zákazníkom.
Naučte sa, ako jednoducho zmeniť pozadie v PowerPointe 2019, aby vaše prezentácie pôsobili pútavo a profesionálne. Získajte tipy na plnú farbu, prechod, obrázky a vzory.
Excel poskytuje štyri užitočné štatistické funkcie na počítanie buniek v hárku alebo zozname: COUNT, COUNTA, COUNTBLANK a COUNTIF. Pre viac informácií o Excel funkciách, pokračujte.
Objavte efektívne klávesové skratky v Exceli 2013 pre zobrazenie, ktoré vám pomôžu zlepšiť produktivitu. Všetky skratky sú začiatkom s Alt+W.
Naučte sa, ako nastaviť okraje v programe Word 2013 s naším jednoduchým sprievodcom. Tento článok obsahuje užitočné tipy a predvoľby okrajov pre váš projekt.
Excel vám poskytuje niekoľko štatistických funkcií na výpočet priemerov, režimov a mediánov. Pozrite si podrobnosti a príklady ich použitia.
Excel 2016 ponúka niekoľko efektívnych spôsobov, ako opraviť chyby vo vzorcoch. Opravy môžete vykonávať po jednom, spustiť kontrolu chýb a sledovať odkazy na bunky.
V niektorých prípadoch Outlook ukladá e-mailové správy, úlohy a plánované činnosti staršie ako šesť mesiacov do priečinka Archív – špeciálneho priečinka pre zastarané položky. Učte sa, ako efektívne archivovať vaše položky v Outlooku.
Word vám umožňuje robiť rôzne zábavné veci s tabuľkami. Učte sa o vytváraní a formátovaní tabuliek vo Worde 2019. Tabuľky sú skvelé na organizáciu informácií.
V článku sa dozviete, ako umožniť používateľovi vybrať rozsah v Excel VBA pomocou dialógového okna. Získajte praktické tipy a príklady na zlepšenie práce s rozsahom Excel VBA.
Vzorec na výpočet percentuálnej odchýlky v Exceli s funkciou ABS pre správne výsledky aj so zápornými hodnotami.






