Ako zmeniť pozadie v PowerPointe 2019

Naučte sa, ako jednoducho zmeniť pozadie v PowerPointe 2019, aby vaše prezentácie pôsobili pútavo a profesionálne. Získajte tipy na plnú farbu, prechod, obrázky a vzory.
Excel vie, ako pomôcť, keď máte viac ako dve vzorky. FarKlempt Robotics, Inc., zisťuje u svojich zamestnancov úroveň ich spokojnosti s prácou. Požadujú od vývojárov, manažérov, údržbárov a technických autorov, aby hodnotili spokojnosť s prácou na stupnici od 1 (najmenej spokojný) do 100 (najspokojnejší).
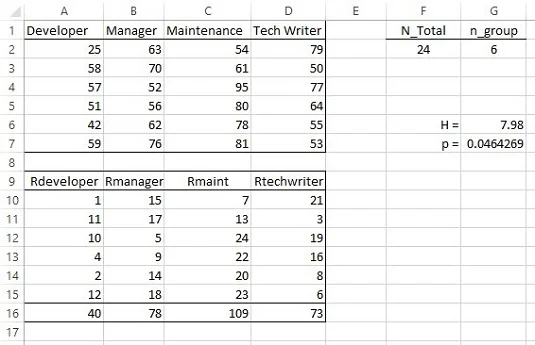
V každej kategórii je šesť zamestnancov. Obrázok nižšie zobrazuje tabuľku s údajmi v stĺpcoch A až D, riadky 1–7. Nulová hypotéza je, že všetky vzorky pochádzajú z rovnakej populácie. Alternatívnou hypotézou je, že nie.
Kruskal-Wallisova jednosmerná analýza rozptylu.
Vhodným neparametrickým testom je Kruskal-Wallisova jednosmerná analýza rozptylu. Začnite zoradením všetkých 24 skóre vo vzostupnom poradí. Opäť platí, že ak platí nulová hypotéza, poradie by malo byť v skupinách rozdelené približne rovnako.
Vzorec pre túto štatistiku je
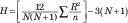
N je celkový počet skóre a n je počet skóre v každej skupine. Aby ste to uľahčili, zadáte rovnaký počet skóre v každej skupine, ale to nie je potrebné pre tento test. R je súčet poradí v skupine. H je rozdelené približne ako chí-kvadrát s df = počet skupín — 1, keď každé n je väčšie ako 5.
Pri spätnom pohľade na obrázok sú poradia údajov v riadkoch 9 – 15 stĺpcov A až D. Riadok 16 obsahuje súčty poradí v každej skupine. Definujte N_Total ako názov pre hodnotu v bunke F2, celkový počet skóre. Definujte n_group ako názov pre hodnotu v G2, počet skóre v každej skupine.
Ak chcete vypočítať H , napíšte
=(12/(N_Total*(N_Total+1)))*(SUMSQ(A16:D16)/n_group)-3*(N_Total+1)
do bunky G6.
Pre test hypotéz napíšte
=CHISQ.DIST.RT(G6;3)
do G7. Výsledok je menší ako 0,05, takže zamietnete nulovú hypotézu.
Naučte sa, ako jednoducho zmeniť pozadie v PowerPointe 2019, aby vaše prezentácie pôsobili pútavo a profesionálne. Získajte tipy na plnú farbu, prechod, obrázky a vzory.
Excel poskytuje štyri užitočné štatistické funkcie na počítanie buniek v hárku alebo zozname: COUNT, COUNTA, COUNTBLANK a COUNTIF. Pre viac informácií o Excel funkciách, pokračujte.
Objavte efektívne klávesové skratky v Exceli 2013 pre zobrazenie, ktoré vám pomôžu zlepšiť produktivitu. Všetky skratky sú začiatkom s Alt+W.
Naučte sa, ako nastaviť okraje v programe Word 2013 s naším jednoduchým sprievodcom. Tento článok obsahuje užitočné tipy a predvoľby okrajov pre váš projekt.
Excel vám poskytuje niekoľko štatistických funkcií na výpočet priemerov, režimov a mediánov. Pozrite si podrobnosti a príklady ich použitia.
Excel 2016 ponúka niekoľko efektívnych spôsobov, ako opraviť chyby vo vzorcoch. Opravy môžete vykonávať po jednom, spustiť kontrolu chýb a sledovať odkazy na bunky.
V niektorých prípadoch Outlook ukladá e-mailové správy, úlohy a plánované činnosti staršie ako šesť mesiacov do priečinka Archív – špeciálneho priečinka pre zastarané položky. Učte sa, ako efektívne archivovať vaše položky v Outlooku.
Word vám umožňuje robiť rôzne zábavné veci s tabuľkami. Učte sa o vytváraní a formátovaní tabuliek vo Worde 2019. Tabuľky sú skvelé na organizáciu informácií.
V článku sa dozviete, ako umožniť používateľovi vybrať rozsah v Excel VBA pomocou dialógového okna. Získajte praktické tipy a príklady na zlepšenie práce s rozsahom Excel VBA.
Vzorec na výpočet percentuálnej odchýlky v Exceli s funkciou ABS pre správne výsledky aj so zápornými hodnotami.






