Ako zmeniť pozadie v PowerPointe 2019

Naučte sa, ako jednoducho zmeniť pozadie v PowerPointe 2019, aby vaše prezentácie pôsobili pútavo a profesionálne. Získajte tipy na plnú farbu, prechod, obrázky a vzory.
Excel je skvelý nástroj, keď potrebujete použiť štatistiku. Ak ste sa v škole nikdy nestretli so štatistikou alebo je to od vás desať či dve desaťročia, tieto tipy vám pomôžu použiť niektoré zo štatistických nástrojov, ktoré Excel poskytuje.
Prvá vec, ktorú by ste mali vedieť, je, že niektoré štatistické analýzy a niektoré štatistické merania sú sakramentsky jednoduché. Opisné štatistiky, ktoré zahŕňajú veci ako krížové tabuľky kontingenčnej tabuľky, ako aj niektoré štatistické funkcie, dávajú zmysel aj niekomu, kto nie je až taký kvantitatívny.
Keď niekto používa termín priemer, zvyčajne sa tým myslí najbežnejšie priemerné meranie, čo je priemer. Pochopenie toho, že pojem priemer je nepresný, robí väčšinu štatistických funkcií Excelu zrozumiteľnejšími.
Aby bola táto diskusia konkrétnejšia, predpokladajme, že sa pozeráte na malý súbor hodnôt: 1, 2, 3, 4 a 5. Ako možno viete, priemer v tomto malom súbore hodnôt je 3. Môžete vypočítať priemer sčítaním všetkých čísel v súbore (1+2+3+4+5) a následným delením tohto súčtu (15) celkovým počtom hodnôt v súbore (5).
Stredná hodnota je hodnota, ktorá oddeľuje najväčšie hodnoty z najmenších hodnôt. V súbore údajov 1, 2, 3, 4 a 5 je medián 3. Hodnota 3 oddeľuje najväčšie hodnoty (4 a 5) od najmenších hodnôt (1 a 2).
Nemusíte rozumieť rôznym priemerným meraniam, ale mali by ste si uvedomiť, že pojem priemer je dosť nepresný.
Vzorec pre štandardnú odchýlku a logika sú celkom ľahko pochopiteľné.
Štandardná odchýlka popisuje hodnoty v súbore dát pohybujú okolo strednej hodnoty. Na štatistických meraniach, ako je štandardná odchýlka, je to pekné, že často získate skutočný prehľad o charakteristikách údajov, na ktoré sa pozeráte. Ďalšou vecou je, že s týmito dvoma bitmi údajov môžete často vyvodzovať závery o údajoch pohľadom na vzorky.
Pozorovanie je jeden z pojmov, s ktorým sa stretnete, ak si prečítate čokoľvek o štatistike. Pozorovanie je len pozorovanie. Jeden spôsob, ako definovať pojem pozorovanie, je takýto: Kedykoľvek skutočne priradíte hodnotu jednej z vašich náhodných premenných, vytvoríte pozorovanie.
Vzorka je kolekcia pozorovaní z populácie. Napríklad, ak vytvoríte súbor údajov, ktorý zaznamenáva dennú vysokú teplotu vo vašom okolí, vaša malá zbierka pozorovaní je vzorkou.
Na porovnanie, vzorka nie je populácia. Obyvateľstvo zahŕňa všetky prípadné pripomienky.
Ak sa pozriete na vzorku hodnôt z populácie a vzorka je reprezentatívna a dostatočne veľká, môžete vyvodiť závery o populácii na základe charakteristík vzorky.
Inferenčná štatistika, hoci je veľmi silná, má dve vlastnosti, ktoré potrebujete vedieť:
Problémy s presnosťou
Strmá krivka učenia
P distribučnej robability funkcie znie celkom zložité; ale v skutočnosti môžete intuitívne pochopiť, čo je funkcia rozdelenia pravdepodobnosti pomocou niekoľkých užitočných príkladov.
Jednou z bežných distribúcií, o ktorých počujete napríklad na hodinách štatistiky, je distribúcia T. T distribúcie je v podstate normálne distribúcie, s výnimkou ťažšími, hrubšie chvosty.
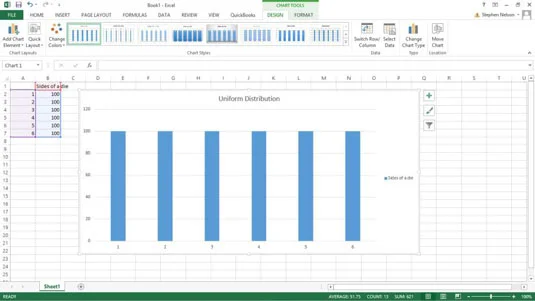
Jednou zo spoločných funkcií rozdelenia pravdepodobnosti je rovnomerné rozdelenie. Pri rovnomernom rozdelení má každá udalosť rovnakú pravdepodobnosť výskytu. Jedinečná vec na tejto distribúcii je, že všetko je na veľmi vysokej úrovni.
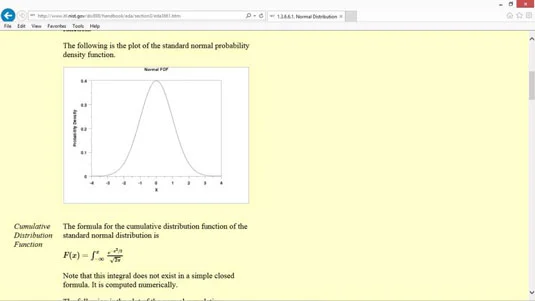
Ďalším bežným typom funkcie rozdelenia pravdepodobnosti je normálne rozdelenie, známe tiež ako zvonová krivka alebo Gaussovo rozdelenie.
Normálne rozdelenie sa prirodzene vyskytuje v mnohých situáciách. Napríklad inteligenčné kvocienty (IQ) sú rozdelené normálne.
Parameter je vstupom do funkcie rozdelenia pravdepodobnosti. Inými slovami, vzorec alebo funkcia alebo rovnica, ktorá opisuje krivku rozdelenia pravdepodobnosti, potrebuje vstupy. V štatistike sa tieto vstupy nazývajú parametre.
Niektoré funkcie rozdelenia pravdepodobnosti potrebujú iba jeden jednoduchý parameter. Napríklad, ak chcete pracovať s rovnomerným rozdelením, všetko, čo skutočne potrebujete, je počet hodnôt v súbore údajov. Napríklad šesťstranná kocka má iba šesť možností.
Niekoľko ďalších užitočných štatistických výrazov, ktoré je potrebné poznať, sú šikmosť a špičatosť. Šikmosť kvantifikuje nedostatok symetrie v rozdelení pravdepodobnosti. V dokonale symetrickom rozdelení, podobne ako pri normálnom rozdelení, sa šikmosť rovná nule. Ak sa však rozdelenie pravdepodobnosti nakloní doprava alebo doľava, šikmosť sa rovná inej hodnote ako nule a hodnota kvantifikuje nedostatok symetrie.
Kurtosis kvantifikuje ťažkosť chvostov v distribúcii. Pri normálnom rozdelení sa špičatosť rovná nule. Chvost je vec, ktorá zasahuje do ľavej alebo pravej. Ak je však chvost v distribúcii ťažší ako normálne rozdelenie, špičatosť je kladné číslo. Ak sú konce v distribúcii tenšie ako v normálnej distribúcii, špičatosť je záporné číslo.
Pravdepodobnosti často mätú ľudí. Pri úrovniach spoľahlivosti je dôležité pochopiť, že sú spojené s mierou chyby.
Ďalšou dôležitou vecou, ktorú je potrebné pochopiť o úrovniach spoľahlivosti, je, že čím väčšiu veľkosť vzorky urobíte, tým menšie bude vaše chybové rozpätie pri použití rovnakej úrovne spoľahlivosti.
Ako jeden príklad povedzme, že máte nejaké údaje služby Google Analytics o dvoch rôznych webových reklamách, ktoré prevádzkujete na propagáciu svojej malej firmy, a chcete vedieť, ktorá reklama je efektívnejšia. Vzorec intervalu spoľahlivosti môžete použiť na zistenie, ako dlho musia byť vaše reklamy v prevádzke, kým spoločnosť Google nazbiera dostatok údajov, aby ste vedeli, ktorá reklama je skutočne lepšia.
Naučte sa, ako jednoducho zmeniť pozadie v PowerPointe 2019, aby vaše prezentácie pôsobili pútavo a profesionálne. Získajte tipy na plnú farbu, prechod, obrázky a vzory.
Excel poskytuje štyri užitočné štatistické funkcie na počítanie buniek v hárku alebo zozname: COUNT, COUNTA, COUNTBLANK a COUNTIF. Pre viac informácií o Excel funkciách, pokračujte.
Objavte efektívne klávesové skratky v Exceli 2013 pre zobrazenie, ktoré vám pomôžu zlepšiť produktivitu. Všetky skratky sú začiatkom s Alt+W.
Naučte sa, ako nastaviť okraje v programe Word 2013 s naším jednoduchým sprievodcom. Tento článok obsahuje užitočné tipy a predvoľby okrajov pre váš projekt.
Excel vám poskytuje niekoľko štatistických funkcií na výpočet priemerov, režimov a mediánov. Pozrite si podrobnosti a príklady ich použitia.
Excel 2016 ponúka niekoľko efektívnych spôsobov, ako opraviť chyby vo vzorcoch. Opravy môžete vykonávať po jednom, spustiť kontrolu chýb a sledovať odkazy na bunky.
V niektorých prípadoch Outlook ukladá e-mailové správy, úlohy a plánované činnosti staršie ako šesť mesiacov do priečinka Archív – špeciálneho priečinka pre zastarané položky. Učte sa, ako efektívne archivovať vaše položky v Outlooku.
Word vám umožňuje robiť rôzne zábavné veci s tabuľkami. Učte sa o vytváraní a formátovaní tabuliek vo Worde 2019. Tabuľky sú skvelé na organizáciu informácií.
V článku sa dozviete, ako umožniť používateľovi vybrať rozsah v Excel VBA pomocou dialógového okna. Získajte praktické tipy a príklady na zlepšenie práce s rozsahom Excel VBA.
Vzorec na výpočet percentuálnej odchýlky v Exceli s funkciou ABS pre správne výsledky aj so zápornými hodnotami.






