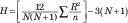Excel zna pomagati, ko imate več kot dva vzorca. FarKlempt Robotics, Inc., raziskuje svoje zaposlene o njihovi stopnji zadovoljstva s svojim delom. Razvijalci, menedžerji, vzdrževalci in tehnični pisci prosijo, naj ocenijo zadovoljstvo pri delu na lestvici od 1 (najmanj zadovoljen) do 100 (najbolj zadovoljen).
V vsaki kategoriji je šest zaposlenih. Spodnja slika prikazuje preglednico s podatki v stolpcih od A do D, vrstice 1–7. Ničelna hipoteza je, da vsi vzorci prihajajo iz iste populacije. Alternativna hipoteza je, da ne.
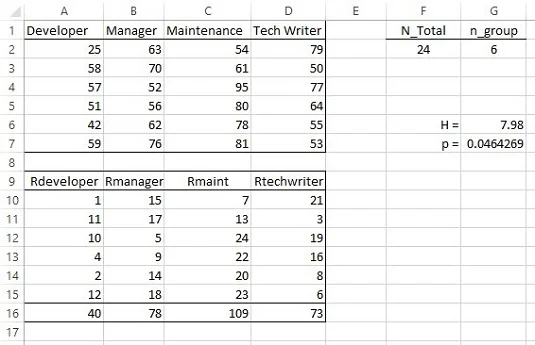
Kruskal-Wallisova enosmerna analiza variance.
Ustrezen neparametrični test je Kruskal-Wallisova enosmerna analiza variance. Začnite tako, da razvrstite vseh 24 rezultatov v naraščajočem vrstnem redu. Še enkrat, če je ničelna hipoteza resnična, je treba uvrstitve porazdeliti po skupinah približno enakomerno.
Formula za to statistiko je
![Uporaba več kot dveh vzorcev v Excelu: enosmerna ANOVA Kruskal-Wallis]()
N je skupno število točk, n pa število točk v vsaki skupini. Za lažje delo določite enako število točk v vsaki skupini, vendar to za ta test ni potrebno. R je vsota rangov v skupini. H je porazdeljen približno kot hi-kvadrat z df = številom skupin — 1, ko je vsak n večji od 5.
Če pogledamo nazaj na sliko, so uvrstitve za podatke v vrsticah 9–15 stolpcev A do D. Vrstica 16 vsebuje vsote uvrstitev v vsaki skupini. Definirajte N_Total kot ime za vrednost v celici F2, skupno število točk. Definirajte n_group kot ime za vrednost v G2, število točk v vsaki skupini.
Za izračun H vnesite
=(12/(N_skupaj*(N_skupaj+1)))*(SUMSQ(A16:D16)/n_skupina)-3*(N_skupaj+1)
v celico G6.
Za preizkus hipoteze vnesite
=CHISQ.DIST.RT(G6,3)
v G7. Rezultat je manjši od 0,05, zato zavrnete ničelno hipotezo.