Za lažje razumevanje statistične analize z Excelom pomaga simulacija osrednjega mejnega izreka. Skoraj ne zveni prav. Kako lahko populacija, ki ni normalno porazdeljena, povzroči normalno porazdeljeno porazdelitev vzorčenja?
Da bi dobili predstavo o tem, kako deluje osrednji mejni izrek, obstaja simulacija. Ta simulacija ustvari nekaj podobnega vzorčne porazdelitve povprečja za zelo majhen vzorec, ki temelji na populaciji, ki ni običajno porazdeljena. Kot boste videli, čeprav populacija ni normalna porazdelitev in čeprav je vzorec majhen, je vzorčna porazdelitev povprečja precej podobna normalni porazdelitvi.
Predstavljajte si ogromno populacijo, ki je sestavljena iz samo treh točk – 1, 2 in 3 – in vsaka je enako verjetno, da se bo pojavila v vzorcu. Predstavljajte si tudi, da lahko iz te populacije naključno izberete vzorec treh točk.
Vsi možni vzorci treh točk (in njihovih pomenov) iz populacije, sestavljene iz točk 1, 2 in 3
| Vzorec |
Pomeni |
Vzorec |
Pomeni |
Vzorec |
Pomeni |
| 1,1,1 |
1.00 |
2,1,1 |
1.33 |
3,1,1 |
1.67 |
| 1,1,2 |
1.33 |
2,1,2 |
1.67 |
3,1,2 |
2.00 |
| 1,1,3 |
1.67 |
2,1,3 |
2.00 |
3,1,3 |
2.33 |
| 1,2,1 |
1.33 |
2,2,1 |
1.67 |
3,2,1 |
2.00 |
| 1,2,2 |
1.67 |
2,2,2 |
2.00 |
3,2,2 |
2.33 |
| 1,2,3 |
2.00 |
2,2,3 |
2.33 |
3,2,3 |
2.67 |
| 1,3,1 |
1.67 |
2,3,1 |
2.00 |
3,3,1 |
2.33 |
| 1,3,2 |
2.00 |
2,3,2 |
2.33 |
3,3,2 |
2.67 |
| 1,3,3 |
2.33 |
2,3,3 |
2.67 |
3,3,3 |
3.00 |
Če natančno pogledate tabelo, lahko skoraj vidite, kaj se bo zgodilo v simulaciji. Vzorčno povprečje, ki se pojavlja najpogosteje, je 2,00. Vzorčna sredstva, ki se pojavljajo najmanj pogosto, sta 1.00 in 3.00. Hmmm. . . .
V simulaciji je bil rezultat naključno izbran iz populacije in nato naključno izbran še dva. Ta skupina treh točk je vzorec. Nato izračunate povprečje tega vzorca. Ta postopek smo ponovili za skupno 60 vzorcev, kar je povzročilo 60 vzorčnih sredstev. Na koncu narišete graf porazdelitve vzorčnih srednjih vrednosti.
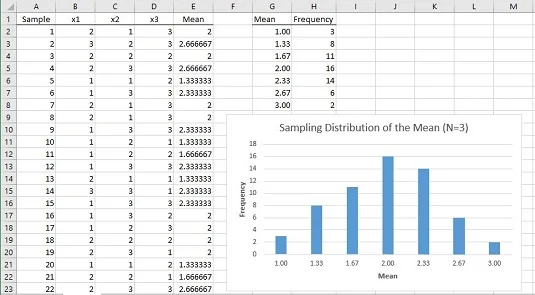
Kako izgleda simulirana porazdelitev vzorčenja povprečja? Spodnja slika prikazuje delovni list, ki odgovarja na to vprašanje.
Na delovnem listu je vsaka vrstica vzorec. Stolpci z oznako x1, x2 in x3 prikazujejo tri ocene za vsak vzorec. Stolpec E prikazuje povprečje za vzorec v vsaki vrstici. Stolpec G prikazuje vse možne vrednosti za povprečje vzorca, stolpec H pa prikazuje, kako pogosto se vsako povprečje pojavlja v 60 vzorcih. Stolpca G in H ter graf prikazujeta, da ima porazdelitev največjo frekvenco, ko je povprečje vzorca 2,00. Frekvence upadajo, saj se vzorčna sredstva vedno bolj oddaljujejo od 2.00.
Bistvo vsega tega je, da populacija ne izgleda nič kot normalna porazdelitev in je velikost vzorca zelo majhna. Tudi pod temi omejitvami je vzorčna porazdelitev povprečja, ki temelji na 60 vzorcih, zelo podobna normalni porazdelitvi.
Kaj pa parametri, ki jih osrednji mejni izrek predvideva za porazdelitev vzorčenja? Začnite s prebivalstvom. Povprečna populacija je 2,00, standardna deviacija populacije pa 0,67. (Takšna populacija zahteva nekaj nekoliko prefinjene matematike za ugotavljanje parametrov.)
Na distribucijo vzorčenja. Srednja vrednost 60 srednjih vrednosti je 1,98, njihova standardna deviacija (ocena standardne napake srednje vrednosti) pa 0,48. Te številke se zelo približajo osrednjemu mejnemu izreku – napovedani parametri za vzorčno porazdelitev povprečja, 2,00 (enako povprečju populacije) in 0,47 (standardni odklon, 0,67, deljeno s kvadratnim korenom iz 3, velikost vzorca) .
Če vas zanima ta simulacija, so naslednji koraki:
Izberite celico za svojo prvo naključno izbrano številko.
Izberite celico B2.
Uporabite funkcijo delovnega lista RANDBETWEEN, da izberete 1, 2 ali 3.
To simulira črpanje števila iz populacije, sestavljene iz številk 1, 2 in 3, kjer imate enake možnosti, da izberete vsako število. Izberete lahko FORMULE | Matematika & Trig | RANDBETWEEN in uporabite pogovorno okno Argumenti funkcije ali samo vnesite =RANDBETWEEN(1,3) v B2 in pritisnite Enter. Prvi argument je najmanjše število vrnjenih RANDBETWEEN, drugi argument pa je največje število.
Izberite celico desno od prvotne celice in izberite drugo naključno število med 1 in 3. To ponovite za tretje naključno število v celici desno od druge.
Najlažji način za to je, da samodejno izpolnite dve celici desno od prvotne celice. V tem delovnem listu sta ti dve celici C2 in D2.
Te tri celice štejte za vzorec in izračunajte njihovo povprečje v celici desno od tretje celice.
Najlažji način za to je, da v celico E2 vnesete =AVERAGE(B2:D2) in pritisnete Enter.
Ta postopek ponovite za toliko vzorcev, kot jih želite vključiti v simulacijo. Vsaka vrstica naj ustreza vzorcu.
Tukaj je bilo uporabljenih 60 vzorcev. Hiter in enostaven način za to je, da izberete prvo vrstico treh naključno izbranih številk in njihove srednje vrednosti ter nato samodejno izpolnite preostale vrstice. Nabor vzorčnih srednjih vrednosti v stolpcu E je simulirana vzorčna porazdelitev srednje vrednosti. Uporabite AVERAGE in STDEV.P, da poiščete njegovo povprečje in standardni odklon.
Če želite videti, kako izgleda ta simulirana porazdelitev vzorčenja, uporabite funkcijo matrike FREQUENCY na vzorčnih sredstvih v stolpcu E. Sledite tem korakom:
V matriko vnesite možne vrednosti vzorčne sredine.
Za to lahko uporabite stolpec G. Možne vrednosti vzorčnega povprečja lahko izrazite v obliki frakcij (3/3, 4/3, 5/3, 6/3, 7/3, 8/3 in 9/3), kot so vnesene v celice G2 do G8. Excel jih pretvori v decimalno obliko. Prepričajte se, da so te celice v številski obliki.
Izberite niz za frekvence možnih vrednosti vzorčne sredine.
Za shranjevanje frekvenc lahko uporabite stolpec H, pri čemer izberete celice od H2 do H8.
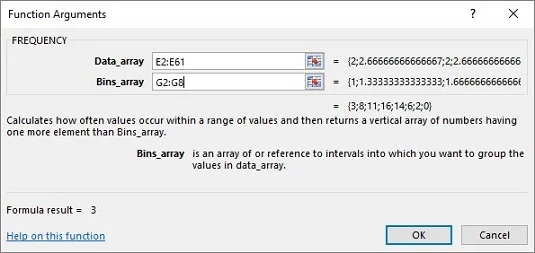
V meniju Statistične funkcije izberite FREQUENCY, da odprete pogovorno okno Argumenti funkcije za FREQUENCY
V pogovornem oknu Argumenti funkcije vnesite ustrezne vrednosti za argumente.
V polje Data_array vnesite celice, ki vsebujejo vzorčna sredstva. V tem primeru je to E2:E61.
Določite niz, ki vsebuje možne vrednosti vzorčne sredine.
FREQUENCY vsebuje to matriko v polju Bins_array. Za ta delovni list gre G2:G8 v polje Bins_array. Ko identificirate obe matriki, pogovorno okno Argumenti funkcije prikaže frekvence znotraj para zavitih oklepajev.![(Približno) Simulacija osrednjega mejnega izreka v Excelu]()
Pritisnite Ctrl+Shift+Enter, da zaprete pogovorno okno Argumenti funkcije in prikažete frekvence.
Uporabite to kombinacijo tipk, ker je FREQUENCY funkcija matrike.
Na koncu z označenimi H2:H8 izberite Vstavi | Priporočeni grafikoni in izberite postavitev gručastega stolpca, da ustvarite graf frekvenc. Vaš graf bo verjetno videti nekoliko drugačen od mojega, ker boste verjetno dobili drugačno naključno število.
Mimogrede, Excel ponovi postopek naključnega izbora vsakič, ko naredite nekaj, kar povzroči, da Excel ponovno izračuna delovni list. Učinek je, da se lahko številke spremenijo, ko to delate. (To pomeni, da znova zaženete simulacijo.) Če se na primer vrnete in znova samodejno izpolnite eno od vrstic, se spremenijo številke in graf.