Za uporabo Power Pivot vam ni treba biti strokovnjak za modeliranje baz podatkov. Vendar je pomembno razumeti odnose. Bolj ko razumete, kako se podatki shranjujejo in upravljajo v bazah podatkov, učinkoviteje boste izkoristili Power Pivot za poročanje.
Razmerje je mehanizem, s katerim so ločene mize med seboj povezani. Razmerje si lahko predstavljate kot VLOOKUP, v katerem podatke v enem obsegu podatkov povežete s podatki v drugem obsegu podatkov z uporabo indeksa ali edinstvenega identifikatorja. V bazah podatkov relacije opravljajo isto stvar, vendar brez težav s pisanjem formul.
Odnosi so pomembni, ker se večina podatkov, s katerimi delate, ujema v nekakšno večdimenzionalno hierarhijo. Na primer, imate lahko tabelo, ki prikazuje stranke, ki kupujejo izdelke. Te stranke potrebujejo račune s številkami računov. Ti računi imajo več vrstic transakcij, ki navajajo, kaj so kupili. Tam obstaja hierarhija.
Zdaj, v svetu enodimenzionalnih preglednic, bi bili ti podatki običajno shranjeni v ravni tabeli, kot je prikazana tukaj.
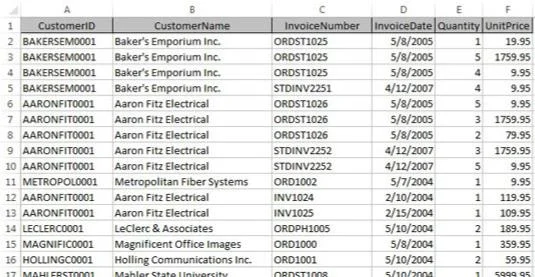
Podatki so shranjeni v Excelovi preglednici v obliki ploščate tabele.
Ker imajo stranke več kot en račun, je treba podatke o stranki (v tem primeru ID stranke in Ime stranke) ponoviti. To povzroča težavo, ko je treba te podatke posodobiti.
Predstavljajte si na primer, da se ime podjetja Aaron Fitz Electrical spremeni v Fitz and Sons Electrical. Če pogledate tabelo, vidite, da več vrstic vsebuje staro ime. Zagotoviti bi morali, da je vsaka vrstica, ki vsebuje staro ime podjetja, posodobljena, da odraža spremembo. Vse vrstice, ki jih zamudite, ne bodo pravilno preslikane nazaj na pravo stranko.
Ali ne bi bilo bolj logično in učinkovito, če bi ime in podatke stranke zabeležili samo enkrat? Potem, namesto da bi morali večkrat pisati iste podatke o stranki, bi lahko preprosto imeli neko obliko referenčne številke stranke.
To je ideja v ozadju odnosov. Stranke lahko ločite od računov, tako da vsakogar postavite v svoje tabele. Nato lahko uporabite edinstven identifikator (kot je CustomerID), da jih povežete skupaj.
Naslednja slika prikazuje, kako bi ti podatki izgledali v relacijski bazi podatkov. Podatki bi bili razdeljeni v tri ločene tabele: Stranke, InvoiceHeader in InvoiceDetails. Vsaka tabela bi bila nato povezana z uporabo edinstvenih identifikatorjev (v tem primeru ID stranke in številka računa).
![Odnosi in Power Pivot]()
Baze podatkov uporabljajo relacije za shranjevanje podatkov v edinstvene tabele in te tabele preprosto povezujejo med seboj.
Tabela Stranke bi vsebovala edinstven zapis za vsako stranko. Na ta način, če morate spremeniti ime stranke, boste morali spremeniti samo ta zapis. Seveda bi v resničnem življenju tabela Stranke vključevala druge atribute, kot so naslov stranke, telefonska številka stranke in začetni datum stranke. Katere koli od teh drugih atributov je mogoče enostavno shraniti in upravljati v tabeli Stranke.
Najpogostejša vrsta razmerja je odnos eden proti več . To pomeni, da se za vsak zapis v eni tabeli lahko en zapis ujema z več zapisi v ločeni tabeli. Na primer, tabela glave računa je povezana s tabelo s podrobnostmi računa. Tabela glave računa ima edinstven identifikator: številka računa. Podatki o računu bodo uporabili številko računa za vsak zapis, ki predstavlja podrobnost tega določenega računa.
Druga vrsta odnosa je odnos ena proti ena : za vsak zapis v eni tabeli je en in samo en ujemajoči se zapis v drugi tabeli. Podatke iz različnih tabel v razmerju ena proti ena je tehnično mogoče združiti v eno tabelo.
Nazadnje, v razmerju mnogo proti mnogo imajo lahko zapisi v obeh tabelah poljubno število ujemajočih se zapisov v drugi tabeli. Baza podatkov v banki ima lahko na primer tabelo različnih vrst posojil (stanovanjski kredit, avtoposojilo itd.) in tabelo strank. Stranka ima lahko več vrst posojil. Medtem se lahko vsaka vrsta posojila odobri številnim strankam.






