Power Pivoti kasutamiseks ei pea te olema ekspert andmebaasi modelleerija. Kuid on oluline mõista suhteid. Mida paremini mõistate, kuidas andmeid andmebaasides salvestatakse ja hallatakse, seda tõhusamalt saate Power Pivoti aruandluseks kasutada.
Suhe on mehhanism, mille eraldi tabelid on omavahel seotud. Seost võib mõelda kui VLOOKUP-i, mille puhul seote ühe andmevahemiku andmed indeksi või kordumatu identifikaatori abil teise andmevahemiku andmetega. Andmebaasides teevad seosed sama asja, kuid ilma valemite kirjutamise vaevata.
Seosed on olulised, kuna enamik teie töötavatest andmetest mahub mitmemõõtmelisse hierarhiasse. Näiteks võib teil olla tabel, mis näitab kliente, kes tooteid ostavad. Need kliendid nõuavad arveid, millel on arve numbrid. Nendel arvetel on mitu tehingurida, kus on loetletud, mida nad ostsid. Seal valitseb hierarhia.
Nüüd, ühemõõtmelises tabelimaailmas, salvestatakse need andmed tavaliselt lamedasse tabelisse, nagu siin näidatud.
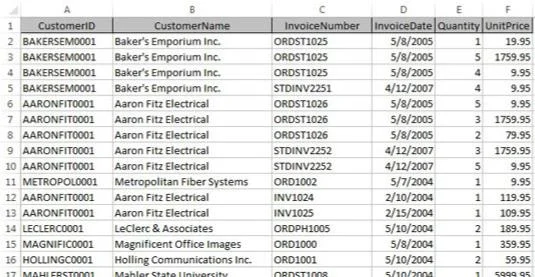
Andmed salvestatakse Exceli tabelisse lametabelivormingus.
Kuna klientidel on rohkem kui üks arve, tuleb kliendi teavet (selles näites Kliendi ID ja Kliendinimi) korrata. See põhjustab probleeme, kui neid andmeid on vaja värskendada.
Näiteks kujutage ette, et ettevõtte Aaron Fitz Electrical nimi muutub Fitz and Sons Electricaliks. Tabelit vaadates näete, et mitmel real on vana nimi. Peaksite tagama, et iga vana ettevõtte nime sisaldavat rida värskendatakse muudatuse kajastamiseks. Mis tahes rida, mille te märkamata jätate, ei vastandata õigesti õigele kliendile.
Kas poleks loogilisem ja tõhusam salvestada kliendi nimi ja andmed ainult üks kord? Selle asemel, et sama klienditeavet korduvalt kirjutada, võiks teil olla lihtsalt mingi kliendi viitenumber.
See on suhete idee. Saate kliendid arvetest eraldada, paigutades igaüks oma tabelitesse. Seejärel saate nende omavahel seostamiseks kasutada kordumatut identifikaatorit (nt kliendi ID).
Järgmine joonis illustreerib, kuidas need andmed relatsiooniandmebaasis välja näeksid. Andmed jagataks kolme eraldi tabelisse: Kliendid, Arvepäis ja Arve üksikasjad. Seejärel seotakse iga tabel kordumatute identifikaatorite abil (antud juhul kliendi ID ja arve number).
![Suhted ja Power Pivot]()
Andmebaasid kasutavad seoseid andmete salvestamiseks unikaalsetesse tabelitesse ja lihtsalt seostavad need tabelid üksteisega.
Tabel Kliendid sisaldaks iga kliendi kordumatut kirjet. Kui teil on vaja muuta kliendi nime, peate muudatuse tegema ainult selles kirjes. Muidugi sisaldaks reaalses elus tabel Kliendid muid atribuute, nagu kliendi aadress, kliendi telefoninumber ja kliendi alguskuupäev. Kõiki neid muid atribuute saab hõlpsasti salvestada ja hallata ka tabelis Kliendid.
Kõige tavalisem suhtetüüp on üks-mitmele suhe. See tähendab, et iga ühe tabeli kirje kohta saab ühe kirje sobitada paljude eraldi tabelis olevate kirjetega. Näiteks arve päise tabel on seotud arve üksikasjade tabeliga. Arve päise tabelil on kordumatu identifikaator: Arve number. Arve detail kasutab arve numbrit iga kirje jaoks, mis esindab selle konkreetse arve detaili.
Teist tüüpi suhtetüüp on üks-ühele suhe: iga ühe tabeli kirje jaoks on erinevas tabelis üks ja ainult üks sobiv kirje. Andmed erinevatest tabelitest üks-ühele seoses saab tehniliselt ühendada üheks tabelisse.
Lõpuks võib mitu-mitmele seose korral mõlema tabeli kirjetel olla teises tabelis suvaline arv sobivaid kirjeid. Näiteks võib panga andmebaasis olla tabel erinevat tüüpi laenudest (kodulaen, autolaen jne) ja klientide tabel. Kliendil võib olla mitut tüüpi laene. Samal ajal saab igat tüüpi laenu anda paljudele klientidele.










