Som byggesten for dine Excel-rapporter skal dataene i dine datamodeller struktureres hensigtsmæssigt. Ikke alle datasæt er skabt lige. Selvom nogle datasæt fungerer i et standard Excel-miljø, fungerer de muligvis ikke til datamodelleringsformål. Før du bygger din datamodel, skal du sikre dig, at dine kildedata er korrekt struktureret til dashboardingformål.
Med risiko for oversimplificering kommer datasæt, der typisk bruges i Excel, i tre grundlæggende former:
-
Regnearksrapporten
-
Den flade datafil
-
Datasættet i tabelform
Punch line er, at kun flade datafiler og tabeldatasæt giver effektive datamodeller.
Regnearksrapporter skaber ineffektive datamodeller
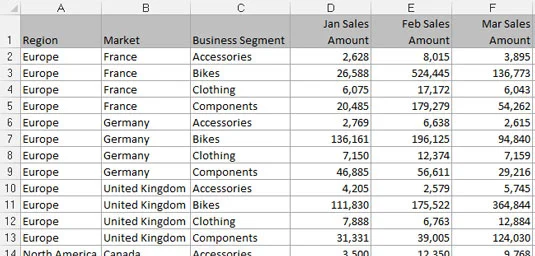
Regnearksrapporter viser højt formaterede, opsummerede data og er ofte designet som præsentationsværktøjer til ledelses- eller ledende brugere. En typisk regnearksrapport gør fornuftig brug af tom plads til formatering, gentager data til æstetiske formål og præsenterer kun analyser på højt niveau. Følgende figur illustrerer en regnearksrapport.
En regnearksrapport.
Selvom en regnearksrapport kan se pæn ud, er den ikke en effektiv datamodel. Hvorfor? Den primære årsag er, at disse rapporter ikke tilbyder dig adskillelse af data, analyse og præsentation. Du er i bund og grund låst i én analyse.
Selvom du kunne lave diagrammer fra den viste rapport, ville det være upraktisk at anvende enhver analyse uden for det, der allerede er der. Hvordan ville du for eksempel beregne og præsentere gennemsnittet af alt cykelsalg ved hjælp af denne specifikke rapport? Hvordan ville du beregne en liste over de ti bedste markeder?
Med denne opsætning er du tvunget ind i meget manuelle processer, som er svære at vedligeholde måned efter måned. Enhver analyse uden for de høje niveauer, der allerede er i rapporten, er i bedste fald grundlæggende - selv med smarte formler. Desuden, hvad sker der, når du er forpligtet til at vise cykelsalg efter måned? Når din datamodel kræver analyse med data, der ikke er i regnearksrapporten, er du tvunget til at søge efter et andet datasæt.
Flade datafiler egner sig fint til datamodeller
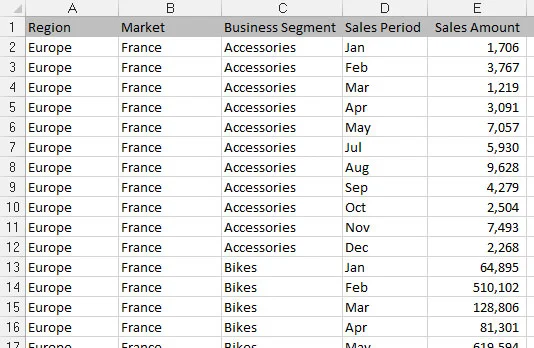
En anden type filformat er en flad fil. Flade filer er datalagre organiseret efter række og kolonne. Hver række svarer til et sæt dataelementer eller en post. Hver kolonne er et felt. Et felt svarer til et unikt dataelement i en post. Følgende figur indeholder de samme data som den forrige rapport, men udtrykt i et fladt datafilformat.
![Strukturer data korrekt i dine Excel-datamodeller]()
En flad datafil.
Bemærk, at hvert datafelt har en kolonne, og hver kolonne svarer til ét dataelement. Desuden er der ingen ekstra mellemrum, og hver række (eller post) svarer til et unikt sæt information. Men den vigtigste egenskab, der gør dette til en flad fil, er, at intet enkelt felt entydigt identificerer en post. Faktisk skal du angive fire separate felter (Region, Market, Business Segment og en måneds salgsbeløb), før du entydigt kunne identificere posten.
Flade filer egner sig fint til datamodellering i Excel, fordi de kan være detaljerede nok til at indeholde de data, du har brug for og stadig være befordrende for en bred vifte af analyser med simple formler - SUM, AVERAGE, VLOOKUP og SUMIF, for blot at nævne nogle få .
Tabeldatasæt er perfekte til pivottabeldrevne datamodeller
Mange effektive datamodeller drives primært af pivottabeller. Pivottabeller er Excels førende analyseværktøjer. For de af jer, der har brugt pivottabeller, ved du, at de tilbyder en fremragende måde at opsummere og forme data til brug ved rapporteringskomponenter, såsom diagrammer og tabeller.
Tabeldatasæt er ideelle til pivottabeldrevne datamodeller. Følgende figur illustrerer et datasæt i tabelform. Bemærk, at den primære forskel mellem et tabeldatasæt og en flad datafil er, at kolonneetiketterne i tabeldatasæt ikke fordobles som faktiske data. For eksempel indeholder kolonnen Salgsperiode måneds-id'et. Denne subtile forskel i struktur er det, der gør tabeldatasæt til optimale datakilder til pivottabeller. Denne struktur sikrer, at vigtige pivottabelfunktioner, såsom sortering og gruppering, fungerer som de skal.
![Strukturer data korrekt i dine Excel-datamodeller]()
Et tabeldatasæt.
Attributterne for et tabeldatasæt er som følger:
-
Den første række af datasættet indeholder feltetiketter, der beskriver oplysningerne i hver kolonne.
-
Kolonneetiketterne trækker ikke dobbeltpligt som dataelementer, der kan bruges som filtre eller forespørgselskriterier (såsom måneder, datoer, år, regioner eller markeder).
-
Der er ingen tomme rækker eller kolonner - hver kolonne har en overskrift, og en værdi er i hver række.
-
Hver kolonne repræsenterer en unik kategori af data.
-
Hver række repræsenterer individuelle elementer i hver kolonne.