Du behøver ikke at være ekspert i databasemodeller for at bruge Power Pivot. Men det er vigtigt at forstå relationer. Jo bedre du forstår, hvordan data lagres og administreres i databaser, jo mere effektivt vil du udnytte Power Pivot til rapportering.
En relation er den mekanisme, hvorved separate tabeller er relateret til hinanden. Du kan tænke på en relation som en VLOOKUP, hvor du relaterer dataene i et dataområde til dataene i et andet dataområde ved hjælp af et indeks eller en unik identifikator. I databaser gør relationer det samme, men uden besværet med at skrive formler.
Relationer er vigtige, fordi de fleste af de data, du arbejder med, passer ind i et slags multidimensionelt hierarki. For eksempel kan du have en tabel, der viser kunder, der køber produkter. Disse kunder kræver fakturaer, der har fakturanumre. Disse fakturaer har flere transaktionslinjer, der viser, hvad de har købt. Der eksisterer et hierarki.
Nu, i den endimensionelle regnearksverden, vil disse data typisk blive gemt i en flad tabel, som den vist her.
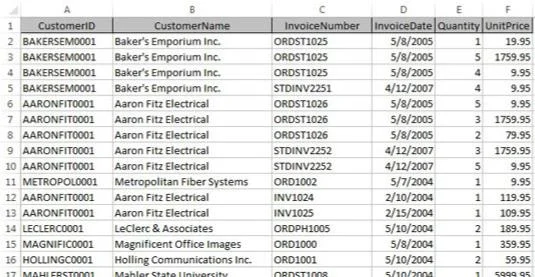
Data gemmes i et Excel-regneark i et fladt-tabelformat.
Fordi kunder har mere end én faktura, skal kundeoplysningerne (i dette eksempel, CustomerID og CustomerName) gentages. Dette forårsager et problem, når disse data skal opdateres.
Forestil dig for eksempel, at navnet på virksomheden Aaron Fitz Electrical ændres til Fitz and Sons Electrical. Ser du på tabellen, kan du se, at flere rækker indeholder det gamle navn. Du skal sikre dig, at hver række, der indeholder det gamle virksomhedsnavn, er opdateret for at afspejle ændringen. Eventuelle rækker, du går glip af, vil ikke kortlægges korrekt tilbage til den rigtige kunde.
Ville det ikke være mere logisk og effektivt kun at registrere kundens navn og oplysninger én gang? Så i stedet for at skulle skrive de samme kundeoplysninger gentagne gange, kunne du blot have en form for kundereferencenummer.
Dette er ideen bag relationer. Du kan adskille kunder fra fakturaer ved at placere hver i deres egne tabeller. Derefter kan du bruge en unik identifikator (såsom CustomerID) til at relatere dem sammen.
Følgende figur illustrerer, hvordan disse data ville se ud i en relationsdatabase. Dataene vil blive opdelt i tre separate tabeller: Kunder, InvoiceHeader og InvoiceDetails. Hver tabel vil derefter være relateret ved hjælp af unikke identifikatorer (kunde-id og fakturanummer, i dette tilfælde).
![Relationer og Power Pivot]()
Databaser bruger relationer til at gemme data i unikke tabeller og relaterer simpelthen disse tabeller til hinanden.
Tabellen Kunder ville indeholde en unik post for hver kunde. På den måde, hvis du har brug for at ændre en kundes navn, skal du kun foretage ændringen i denne post. I det virkelige liv vil Kunder-tabellen naturligvis indeholde andre attributter, såsom kundeadresse, kundetelefonnummer og kundestartdato. Enhver af disse andre attributter kan også nemt gemmes og administreres i Kunder-tabellen.
Den mest almindelige forholdstype er et en-til-mange forhold. Det vil sige, at for hver post i en tabel kan én post matches med mange poster i en separat tabel. For eksempel er en fakturaoverskriftstabel relateret til en fakturadetaljetabel. Fakturahovedtabellen har en unik identifikator: Fakturanummer. Fakturadetaljerne vil bruge fakturanummeret for hver post, der repræsenterer en detalje af den pågældende faktura.
En anden form for relationstype er en-til-en- relationen: For hver post i en tabel er én og kun én matchende post i en anden tabel. Data fra forskellige tabeller i en en-til-en relation kan teknisk set kombineres til en enkelt tabel.
Endelig, i et mange-til-mange forhold, kan poster i begge tabeller have et hvilket som helst antal matchende poster i den anden tabel. For eksempel kan en database i en bank have en tabel over de forskellige typer lån (boliglån, billån osv.) og en tabel over kunder. En kunde kan have mange typer lån. I mellemtiden kan hver type lån ydes til mange kunder.









