For at hjælpe dig med at forstå statistisk analyse med Excel, hjælper det at simulere Central Limit Theorem. Det lyder næsten ikke rigtigt. Hvordan kan en population, der ikke er normalfordelt, resultere i en normalfordelt stikprøvefordeling?
For at give dig en idé om, hvordan Central Limit Theorem fungerer, er der en simulering. Denne simulering skaber noget som en stikprøvefordeling af middelværdien for en meget lille prøve baseret på en population, der ikke er normalfordelt. Som du vil se, selvom populationen ikke er en normalfordeling, og selvom stikprøven er lille, ligner stikprøvefordelingen af middelværdien ganske lidt en normalfordeling.
Forestil dig en enorm population, der kun består af tre scores - 1, 2 og 3 - og hver enkelt er lige sandsynligt, at de optræder i en stikprøve. Forestil dig også, at du tilfældigt kan vælge en stikprøve på tre scores fra denne population.
Alle mulige prøver af tre scores (og deres midler) fra en population bestående af scorerne 1, 2 og 3
| Prøve |
Betyde |
Prøve |
Betyde |
Prøve |
Betyde |
| 1,1,1 |
1.00 |
2,1,1 |
1,33 |
3,1,1 |
1,67 |
| 1,1,2 |
1,33 |
2,1,2 |
1,67 |
3,1,2 |
2.00 |
| 1,1,3 |
1,67 |
2,1,3 |
2.00 |
3,1,3 |
2,33 |
| 1,2,1 |
1,33 |
2,2,1 |
1,67 |
3,2,1 |
2.00 |
| 1,2,2 |
1,67 |
2,2,2 |
2.00 |
3,2,2 |
2,33 |
| 1,2,3 |
2.00 |
2,2,3 |
2,33 |
3,2,3 |
2,67 |
| 1,3,1 |
1,67 |
2,3,1 |
2.00 |
3,3,1 |
2,33 |
| 1,3,2 |
2.00 |
2,3,2 |
2,33 |
3,3,2 |
2,67 |
| 1,3,3 |
2,33 |
2,3,3 |
2,67 |
3,3,3 |
3.00 |
Ser man godt efter i tabellen, kan man næsten se, hvad der er ved at ske i simuleringen. Det stikprøvemiddel, der oftest optræder, er 2,00. De stikprøvemidler, der forekommer mindst hyppigt, er 1,00 og 3,00. Hmmm. . . .
I simuleringen blev en score tilfældigt udvalgt fra populationen og derefter tilfældigt udvalgt to mere. Denne gruppe på tre scoringer er et eksempel. Derefter beregner du middelværdien af den prøve. Denne proces blev gentaget for i alt 60 prøver, hvilket resulterede i 60 prøvegennemsnit. Til sidst tegner du fordelingen af stikprøvemiddelværdierne.
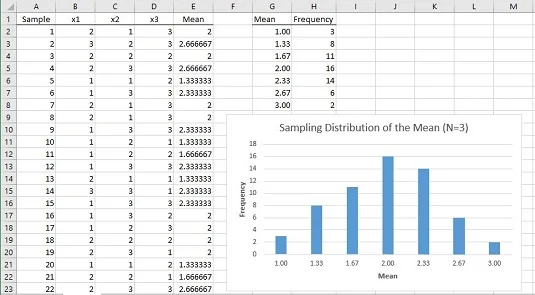
Hvordan ser den simulerede stikprøvefordeling af middelværdien ud? Billedet nedenfor viser et arbejdsark, der besvarer dette spørgsmål.
I regnearket er hver række et eksempel. Kolonnerne mærket x1, x2 og x3 viser de tre point for hver prøve. Kolonne E viser gennemsnittet for prøven i hver række. Kolonne G viser alle mulige værdier for prøvegennemsnittet, og kolonne H viser, hvor ofte hvert gennemsnit optræder i de 60 prøver. Kolonne G og H og grafen viser, at fordelingen har sin maksimale frekvens, når prøvegennemsnittet er 2,00. Frekvenserne aftager, efterhånden som samplemidlet bliver længere og længere væk fra 2.00.
Pointen med alt dette er, at populationen ikke ligner en normalfordeling, og stikprøvestørrelsen er meget lille. Selv under disse begrænsninger begynder prøveudtagningsfordelingen af gennemsnittet baseret på 60 prøver at ligne en normalfordeling.
Hvad med de parametre, Central Limit Theorem forudsiger for samplingsfordelingen? Start med befolkningen. Befolkningsgennemsnittet er 2,00, og populationens standardafvigelse er 0,67. (Denne type population kræver noget lidt fancy matematik for at finde ud af parametrene.)
Videre til stikprøvefordelingen. Middelværdien af de 60 middelværdier er 1,98, og deres standardafvigelse (et estimat af middelværdiens standardfejl) er 0,48. Disse tal nærmer sig nøje de forudsagte parametre for Central Limit Theorem for stikprøvefordelingen af middelværdien, 2,00 (lig med populationsmiddelværdien) og 0,47 (standardafvigelsen, 0,67, divideret med kvadratroden af 3, stikprøvestørrelsen) .
Hvis du er interesseret i at lave denne simulering, er trinene her:
Vælg en celle til dit første tilfældigt valgte nummer.
Vælg celle B2.
Brug regnearksfunktionen RANDBETWEEN til at vælge 1, 2 eller 3.
Dette simulerer at tegne et tal fra en population bestående af tallene 1, 2 og 3, hvor du har lige stor chance for at vælge hvert tal. Du kan enten vælge FORMLER | Matematik og trig | RANDBETWEEN og brug dialogboksen Funktionsargumenter eller bare skriv =RANDBETWEEN(1,3) i B2 og tryk på Enter. Det første argument er det mindste tal, RANDBETWEEN returnerer, og det andet argument er det største tal.
Vælg cellen til højre for den oprindelige celle, og vælg et andet tilfældigt tal mellem 1 og 3. Gør dette igen for et tredje tilfældigt tal i cellen til højre for det andet.
Den nemmeste måde at gøre dette på er at autofylde de to celler til højre for den oprindelige celle. I dette regneark er disse to celler C2 og D2.
Betragt disse tre celler som en prøve, og beregn deres middelværdi i cellen til højre for den tredje celle.
Den nemmeste måde at gøre dette på er bare at skrive =AVERAGE(B2:D2) i celle E2 og trykke på Enter.
Gentag denne proces for så mange prøver, som du vil inkludere i simuleringen. Få hver række til at svare til en prøve.
60 prøver blev brugt her. Den hurtige og nemme måde at få dette gjort på er at vælge den første række af tre tilfældigt valgte tal og deres middelværdi og derefter autofylde de resterende rækker. Sættet af prøvemiddelværdier i kolonne E er den simulerede prøveudtagningsfordeling af middelværdien. Brug AVERAGE og STDEV.P til at finde dens middelværdi og standardafvigelse.
For at se, hvordan denne simulerede samplingsfordeling ser ud, skal du bruge array-funktionen FREQUENCY på prøvemiddelværdierne i kolonne E. Følg disse trin:
Indtast de mulige værdier for prøvegennemsnittet i et array.
Du kan bruge kolonne G til dette. Du kan udtrykke de mulige værdier af prøvegennemsnittet i brøkform (3/3, 4/3, 5/3, 6/3, 7/3, 8/3 og 9/3) ligesom dem, der er indtastet i cellerne G2 til G8. Excel konverterer dem til decimalform. Sørg for, at disse celler er i talformat.
Vælg et array for frekvenserne af de mulige værdier af prøvegennemsnittet.
Du kan bruge kolonne H til at holde frekvenserne ved at vælge cellerne H2 til H8.
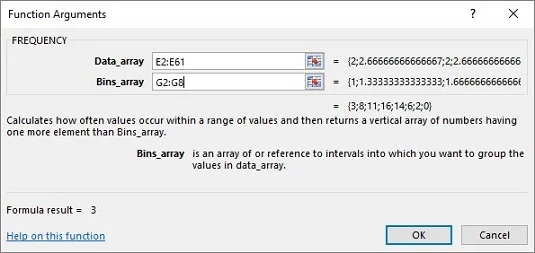
Fra menuen Statistiske funktioner skal du vælge FREKVENS for at åbne dialogboksen Funktionsargumenter for FREKVENS
Indtast de relevante værdier for argumenterne i dialogboksen Funktionsargumenter.
I feltet Data_array skal du indtaste de celler, der indeholder prøvemidlet. I dette eksempel er det E2:E61.
Identificer det array, der indeholder de mulige værdier af prøvegennemsnittet.
FREQUENCY holder dette array i boksen Bins_array. For dette regneark går G2:G8 ind i boksen Bins_array. Når du har identificeret begge arrays, viser dialogboksen Funktionsargumenter frekvenserne inden for et par krøllede parenteser.![(Omtrent) Simulering af Central Limit Theorem i Excel]()
Tryk på Ctrl+Shift+Enter for at lukke dialogboksen Funktionsargumenter og vise frekvenserne.
Brug denne tastekombination, fordi FREKVENS er en array-funktion.
Til sidst, med H2:H8 fremhævet, vælg Indsæt | Anbefalede diagrammer, og vælg Clustered Column-layoutet for at fremstille grafen over frekvenserne. Din graf vil sandsynligvis se noget anderledes ud end min, fordi du sandsynligvis ender med et andet tilfældigt tal.
Excel gentager i øvrigt den tilfældige udvælgelsesproces, når du gør noget, der får Excel til at genberegne regnearket. Effekten er, at tallene kan ændre sig, efterhånden som du arbejder dig igennem dette. (Det vil sige, at du kører simuleringen igen.) For eksempel, hvis du går tilbage og autofylder en af rækkerne igen, ændres tallene, og grafen ændres.