Як спілкуватися в чаті в Outlook Web App
Досліджуйте, як ефективно спілкуватися в чаті з колегами в Outlook Web App. Дізнайтеся про покрокову інструкцію та нові можливості для підвищення продуктивності.
Excel знає, як допомогти, якщо у вас більше двох зразків. FarKlempt Robotics, Inc. проводить опитування своїх співробітників щодо рівня їх задоволеності своєю роботою. Вони просять розробників, менеджерів, працівників технічного обслуговування та технічних авторів оцінити задоволеність роботою за шкалою від 1 (найменш задоволений) до 100 (найбільш задоволений).
У кожній категорії по шість співробітників. На зображенні нижче показано електронну таблицю з даними в стовпцях A–D, рядках 1–7. Нульова гіпотеза полягає в тому, що всі вибірки походять з однієї сукупності. Альтернативна гіпотеза полягає в тому, що вони цього не роблять.
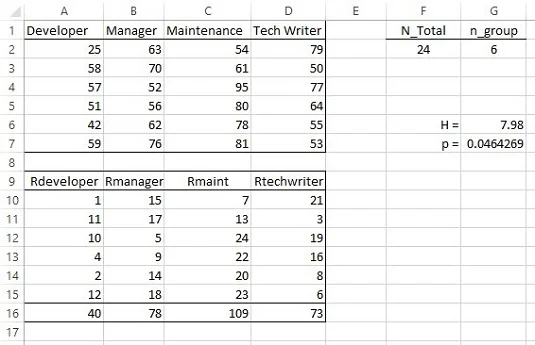
Односторонній дисперсійний аналіз Крускала–Уолліса.
Відповідним непараметричним тестом є односторонній дисперсійний аналіз Краскала-Уолліса. Почніть з рейтингу всіх 24 балів у порядку зростання. Знову ж таки, якщо нульова гіпотеза вірна, ранги повинні бути розподілені приблизно порівну між групами.
Формула цієї статистики така
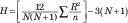
N – загальна кількість балів, а n – кількість балів у кожній групі. Щоб полегшити завдання, ви вказуєте однакову кількість балів у кожній групі, але це не обов’язково для цього тесту. R — сума рангів у групі. H розподіляється приблизно як хі-квадрат з df = кількість груп — 1, коли кожне n більше 5.
Подивившись на зображення, ранги даних знаходяться в рядках 9–15 стовпців A–D. Рядок 16 містить суми рангів у кожній групі. Визначте N_Total як назву для значення в клітинці F2, тобто загальної кількості балів. Визначте n_group як назву для значення в G2, кількість балів у кожній групі.
Щоб обчислити H , введіть
=(12/(N_всього*(N_всього+1)))*(SUMSQ(A16:D16)/n_група)-3*(N_всього+1)
в комірку G6.
Для перевірки гіпотези введіть
=CHISQ.DIST.RT(G6,3)
в G7. Результат менший за 0,05, тому ви відхиляєте нульову гіпотезу.
Досліджуйте, як ефективно спілкуватися в чаті з колегами в Outlook Web App. Дізнайтеся про покрокову інструкцію та нові можливості для підвищення продуктивності.
Як заборонити Microsoft Word відкривати файли в режимі лише для читання в Windows. Microsoft Word відкриває файли в режимі лише для читання, що робить неможливим їх редагування? Не хвилюйтеся, методи наведено нижче
Як виправити помилки під час друку неправильних документів Microsoft Word Помилки під час друку документів Word зі зміненими шрифтами, безладними абзацами, відсутнім текстом або втраченим вмістом є досить поширеними. Однак не варто
Якщо ви використовували перо або маркер для малювання на слайдах PowerPoint під час презентації, ви можете зберегти малюнки для наступної презентації або стерти їх, щоб наступного разу, коли ви показуватимете їх, розпочали з чистих слайдів PowerPoint. Дотримуйтесь цих інструкцій, щоб стерти малюнки пером і маркером: Стирання рядків на одній з […]
Бібліотека стилів містить файли CSS, файли мови розширюваної мови таблиць стилів (XSL) та зображення, які використовуються попередньо визначеними основними сторінками, макетами сторінок та елементами керування в SharePoint 2010. Щоб знайти файли CSS у бібліотеці стилів сайту видавництва: виберіть «Дії сайту»→ «Перегляд». Весь вміст сайту. З’являється вміст сайту. Бібліотека Style знаходиться в […]
Не перевантажуйте аудиторію гігантськими цифрами. У Microsoft Excel ви можете покращити читабельність своїх інформаційних панелей і звітів, відформатувавши числа, щоб вони відображалися в тисячах або мільйонах.
Дізнайтеся, як використовувати інструменти соціальних мереж SharePoint, які дозволяють особам і групам спілкуватися, співпрацювати, обмінюватися інформацією та спілкуватися.
Юліанські дати часто використовуються у виробничих середовищах як мітка часу та швидкий довідник для номера партії. Цей тип кодування дати дозволяє роздрібним продавцям, споживачам та агентам з обслуговування визначити, коли був виготовлений продукт, а отже, і вік продукту. Юліанські дати також використовуються в програмуванні, військовій справі та астрономії. Інший […]
Ви можете створити веб-програму в Access 2016. Так що ж таке веб-програма? Ну, веб означає, що він онлайн, а додаток — це просто скорочення від «додаток». Користувацька веб-програма — це онлайн-додаток для баз даних, доступ до якого здійснюється з хмари за допомогою браузера. Ви створюєте та підтримуєте веб-програму у настільній версії […]
Більшість сторінок у SharePoint 2010 відображають список посилань навігації на панелі швидкого запуску ліворуч. Панель швидкого запуску відображає посилання на пропонований вміст сайту, наприклад списки, бібліотеки, сайти та сторінки публікації. Панель швидкого запуску містить два дуже важливі посилання: Посилання на весь вміст сайту: […]








