Som byggesteinen for Excel-rapportene dine, må dataene i datamodellene struktureres riktig. Ikke alle datasett er skapt like. Selv om noen datasett fungerer i et standard Excel-miljø, kan det hende at de ikke fungerer for datamodelleringsformål. Før du bygger datamodellen din, sørg for at kildedataene dine er riktig strukturert for dashbordformål.
Med fare for overforenkling kommer datasett som vanligvis brukes i Excel i tre grunnleggende former:
Punch-linjen er at bare flate datafiler og tabellformede datasett gir effektive datamodeller.
Regnearkrapporter gir ineffektive datamodeller
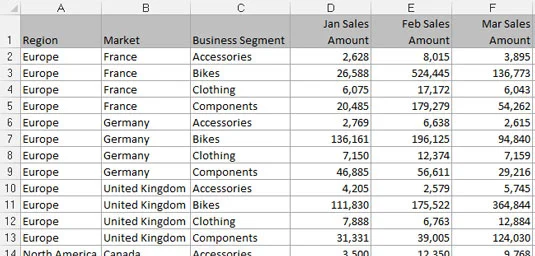
Regnearkrapporter viser høyt formaterte, oppsummerte data og er ofte utformet som presentasjonsverktøy for ledelse eller ledende brukere. En typisk regnearkrapport bruker fornuftig bruk av tom plass til formatering, gjentar data for estetiske formål og presenterer kun analyser på høyt nivå. Følgende figur illustrerer en regnearkrapport.
En regnearkrapport.
Selv om en regnearkrapport kan se bra ut, gir den ikke en effektiv datamodell. Hvorfor? Hovedårsaken er at disse rapportene ikke gir deg noen separasjon av data, analyse og presentasjon. Du er i hovedsak låst til én analyse.
Selv om du kan lage diagrammer fra rapporten som vises, ville det være upraktisk å bruke enhver analyse utenfor det som allerede er der. Hvordan vil du for eksempel beregne og presentere gjennomsnittet av alle sykkelsalg ved å bruke denne spesifikke rapporten? Hvordan vil du beregne en liste over de ti beste markedene?
Med dette oppsettet blir du tvunget inn i veldig manuelle prosesser som er vanskelige å vedlikeholde måned etter måned. Enhver analyse utenfor de på høyt nivå allerede i rapporten er i beste fall grunnleggende - selv med fancy formler. Videre, hva skjer når du er pålagt å vise sykkelsalg etter måned? Når datamodellen din krever analyse med data som ikke er i regnearkrapporten, er du tvunget til å søke etter et annet datasett.
Flate datafiler egner seg fint til datamodeller
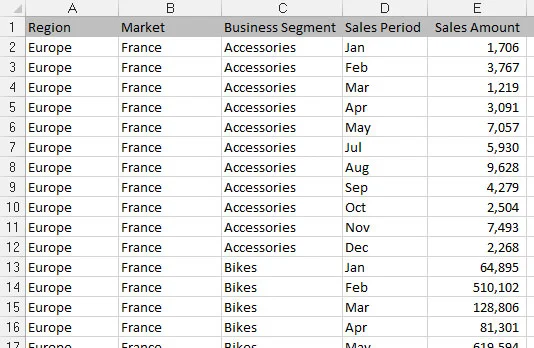
En annen type filformat er en flat fil. Flate filer er datalager organisert etter rad og kolonne. Hver rad tilsvarer et sett med dataelementer, eller en post. Hver kolonne er et felt. Et felt tilsvarer et unikt dataelement i en post. Følgende figur inneholder de samme dataene som den forrige rapporten, men uttrykt i et flatt datafilformat.
![Strukturer data på riktig måte i Excel-datamodellene dine]()
En flat datafil.
Legg merke til at hvert datafelt har en kolonne, og hver kolonne tilsvarer ett dataelement. Dessuten er det ingen ekstra mellomrom, og hver rad (eller post) tilsvarer et unikt sett med informasjon. Men nøkkelattributtet som gjør dette til en flat fil er at intet enkelt felt identifiserer en post unikt. Faktisk må du spesifisere fire separate felt (Region, Market, Business Segment og en måneds salgsbeløp) før du kan identifisere posten unikt.
Flate filer egner seg godt til datamodellering i Excel fordi de kan være detaljerte nok til å inneholde dataene du trenger og fortsatt bidra til et bredt spekter av analyser med enkle formler – SUM, AVERAGE, VLOOKUP og SUMIF, bare for å nevne noen få. .
Tabellformede datasett er perfekte for pivottabelldrevne datamodeller
Mange effektive datamodeller drives primært av pivottabeller. Pivottabeller er Excels fremste analyseverktøy. For de av dere som har brukt pivottabeller, vet du at de tilbyr en utmerket måte å oppsummere og forme data for bruk av rapporteringskomponenter, som diagrammer og tabeller.
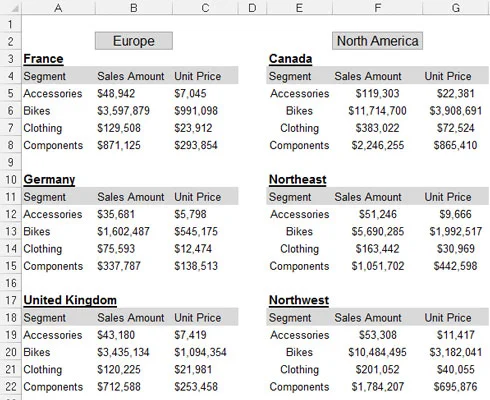
Tabelldatasett er ideelle for pivottabelldrevne datamodeller. Følgende figur illustrerer et tabellbasert datasett. Merk at den primære forskjellen mellom et tabelldatasett og en flat datafil er at kolonneetikettene i tabelldatasett ikke dobler som faktiske data. For eksempel inneholder kolonnen Salgsperiode månedsidentifikatoren. Denne subtile forskjellen i struktur er det som gjør tabelldatasett til optimale datakilder for pivottabeller. Denne strukturen sikrer at sentrale pivottabellfunksjoner, som sortering og gruppering, fungerer slik de skal.
![Strukturer data på riktig måte i Excel-datamodellene dine]()
Et tabellbasert datasett.
Attributtene til et tabelldatasett er som følger:
-
Den første raden i datasettet inneholder feltetiketter som beskriver informasjonen i hver kolonne.
-
Kolonneetikettene trekker ikke dobbel plikt som dataelementer som kan brukes som filtre eller søkekriterier (som måneder, datoer, år, regioner eller markeder).
-
Det er ingen tomme rader eller kolonner - hver kolonne har en overskrift, og en verdi er i hver rad.
-
Hver kolonne representerer en unik kategori av data.
-
Hver rad representerer individuelle elementer i hver kolonne.