Du trenger ikke være en ekspert på databasemodeller for å bruke Power Pivot. Men det er viktig å forstå relasjoner. Jo bedre du forstår hvordan data lagres og administreres i databaser, jo mer effektivt vil du utnytte Power Pivot for rapportering.
En relasjon er mekanismen der separate tabeller er relatert til hverandre. Du kan tenke på et forhold som en VLOOKUP, der du relaterer dataene i ett dataområde til dataene i et annet dataområde ved hjelp av en indeks eller en unik identifikator. I databaser gjør relasjoner det samme, men uten bryet med å skrive formler.
Relasjoner er viktige fordi de fleste dataene du jobber med passer inn i et slags flerdimensjonalt hierarki. Du kan for eksempel ha en tabell som viser kunder som kjøper produkter. Disse kundene krever fakturaer som har fakturanummer. Disse fakturaene har flere linjer med transaksjoner som viser hva de har kjøpt. Det eksisterer et hierarki der.
Nå, i den endimensjonale regnearkverdenen, vil disse dataene vanligvis bli lagret i en flat tabell, som den som vises her.
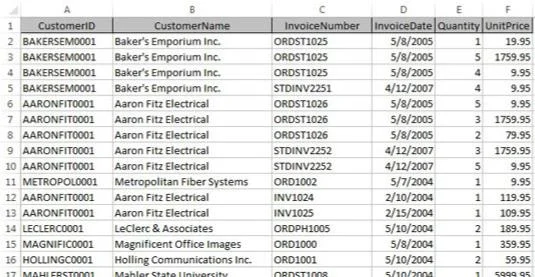
Data lagres i et Excel-regneark med et flatt-tabellformat.
Fordi kunder har mer enn én faktura, må kundeinformasjonen (i dette eksemplet, CustomerID og CustomerName) gjentas. Dette forårsaker et problem når disse dataene må oppdateres.
Tenk deg for eksempel at navnet på selskapet Aaron Fitz Electrical endres til Fitz and Sons Electrical. Når du ser på tabellen, ser du at flere rader inneholder det gamle navnet. Du må sørge for at hver rad som inneholder det gamle firmanavnet oppdateres for å gjenspeile endringen. Eventuelle rader du savner vil ikke kartlegges riktig tilbake til riktig kunde.
Ville det ikke vært mer logisk og effektivt å registrere navnet og informasjonen til kunden kun én gang? Deretter, i stedet for å måtte skrive den samme kundeinformasjonen gjentatte ganger, kan du ganske enkelt ha en form for kundereferansenummer.
Dette er tanken bak relasjoner. Du kan skille kunder fra fakturaer ved å plassere hver i sine egne tabeller. Deretter kan du bruke en unik identifikator (som CustomerID) for å relatere dem sammen.
Følgende figur illustrerer hvordan disse dataene vil se ut i en relasjonsdatabase. Dataene vil bli delt inn i tre separate tabeller: Kunder, InvoiceHeader og InvoiceDetails. Hver tabell vil da være relatert ved hjelp av unike identifikatorer (CustomerID og InvoiceNumber, i dette tilfellet).
![Relasjoner og Power Pivot]()
Databaser bruker relasjoner til å lagre data i unike tabeller og bare relatere disse tabellene til hverandre.
Kunder-tabellen vil inneholde en unik post for hver kunde. På den måten, hvis du trenger å endre en kundes navn, må du bare gjøre endringen i den posten. Selvfølgelig, i det virkelige liv, vil Kunder-tabellen inkludere andre attributter, for eksempel kundeadresse, kundetelefonnummer og kundestartdato. Enhver av disse andre attributtene kan også enkelt lagres og administreres i Kunder-tabellen.
Den vanligste relasjonstypen er et en-til-mange forhold. Det vil si at for hver post i én tabell kan én post matches med mange poster i en separat tabell. For eksempel er en fakturaoverskriftstabell relatert til en fakturadetaljtabell. Fakturaoverskriftstabellen har en unik identifikator: Fakturanummer. Fakturadetaljene vil bruke fakturanummeret for hver post som representerer en detalj av den aktuelle fakturaen.
En annen type relasjonstype er en-til-en- relasjonen: For hver post i én tabell er én og bare én matchende post i en annen tabell. Data fra forskjellige tabeller i et en-til-en-forhold kan teknisk sett kombineres til en enkelt tabell.
Til slutt, i et mange-til-mange- forhold, kan poster i begge tabellene ha et hvilket som helst antall samsvarende poster i den andre tabellen. For eksempel kan en database i en bank ha en tabell over ulike typer lån (boliglån, billån og så videre) og en tabell over kunder. En kunde kan ha mange typer lån. I mellomtiden kan hver type lån gis til mange kunder.









