For å hjelpe deg å forstå statistisk analyse med Excel, hjelper det å simulere Central Limit Theorem. Det høres nesten ikke riktig ut. Hvordan kan en populasjon som ikke er normalfordelt resultere i en normalfordelt utvalgsfordeling?
For å gi deg en ide om hvordan sentralgrensesetningen fungerer, er det en simulering. Denne simuleringen skaper noe sånt som en prøvefordeling av gjennomsnittet for et veldig lite utvalg, basert på en populasjon som ikke er normalfordelt. Som du vil se, selv om populasjonen ikke er en normalfordeling, og selv om utvalget er lite, ser prøvefordelingen av gjennomsnittet ganske ut som en normalfordeling.
Se for deg en enorm populasjon som består av bare tre poengsummer - 1, 2 og 3 - og hver enkelt er like sannsynlig å vises i et utvalg. Tenk deg også at du tilfeldig kan velge et utvalg av tre poengsum fra denne populasjonen.
Alle mulige prøver av tre poeng (og deres midler) fra en populasjon som består av poeng 1, 2 og 3
| Prøve |
Mener |
Prøve |
Mener |
Prøve |
Mener |
| 1,1,1 |
1.00 |
2,1,1 |
1,33 |
3,1,1 |
1,67 |
| 1,1,2 |
1,33 |
2,1,2 |
1,67 |
3,1,2 |
2.00 |
| 1,1,3 |
1,67 |
2,1,3 |
2.00 |
3,1,3 |
2,33 |
| 1,2,1 |
1,33 |
2,2,1 |
1,67 |
3,2,1 |
2.00 |
| 1,2,2 |
1,67 |
2,2,2 |
2.00 |
3,2,2 |
2,33 |
| 1,2,3 |
2.00 |
2,2,3 |
2,33 |
3,2,3 |
2,67 |
| 1,3,1 |
1,67 |
2,3,1 |
2.00 |
3,3,1 |
2,33 |
| 1,3,2 |
2.00 |
2,3,2 |
2,33 |
3,3,2 |
2,67 |
| 1,3,3 |
2,33 |
2,3,3 |
2,67 |
3,3,3 |
3.00 |
Hvis du ser nøye på tabellen, kan du nesten se hva som er i ferd med å skje i simuleringen. Prøvegjennomsnittet som dukker opp oftest er 2,00. Utvalgsmiddelene som vises minst hyppig er 1,00 og 3,00. Hmmm. . . .
I simuleringen ble en poengsum valgt tilfeldig fra populasjonen og deretter tilfeldig valgt to til. Den gruppen på tre poengsum er et utvalg. Deretter beregner du gjennomsnittet av den prøven. Denne prosessen ble gjentatt for totalt 60 prøver, noe som resulterte i 60 prøvegjennomsnitt. Til slutt tegner du fordelingen av prøvemidlene.
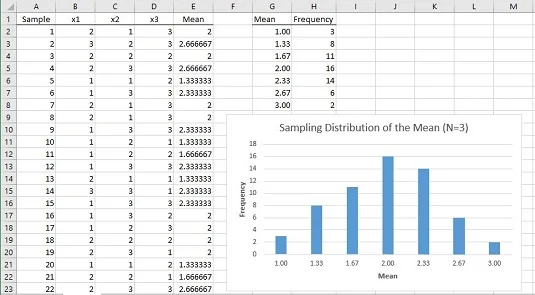
Hvordan ser den simulerte prøvefordelingen av gjennomsnittet ut? Bildet nedenfor viser et regneark som svarer på dette spørsmålet.
I regnearket er hver rad et eksempel. Kolonnene merket x1, x2 og x3 viser de tre poengsummene for hver prøve. Kolonne E viser gjennomsnittet for prøven i hver rad. Kolonne G viser alle mulige verdier for prøvegjennomsnittet, og kolonne H viser hvor ofte hvert gjennomsnitt vises i de 60 prøvene. Kolonne G og H, og grafen, viser at fordelingen har sin maksimale frekvens når prøvegjennomsnittet er 2,00. Frekvensene avtar etter hvert som prøvemidlene kommer lenger og lenger bort fra 2.00.
Poenget med alt dette er at populasjonen ikke ser ut som en normalfordeling og at utvalgsstørrelsen er veldig liten. Selv under disse begrensningene begynner prøvefordelingen av gjennomsnittet basert på 60 prøver å ligne veldig på en normalfordeling.
Hva med parametrene Central Limit Theorem forutsier for samplingsfordelingen? Start med befolkningen. Befolkningsgjennomsnittet er 2,00 og populasjonsstandardavviket er 0,67. (Denne typen populasjon krever litt fancy matematikk for å finne ut parameterne.)
Videre til prøvefordelingen. Gjennomsnittet av de 60 gjennomsnittene er 1,98, og deres standardavvik (et estimat av standardfeilen til gjennomsnittet) er 0,48. Disse tallene tilnærmer seg tett de predikerte parametrene for sentralgrensesetningen for prøvefordelingen av gjennomsnittet, 2,00 (lik populasjonsgjennomsnittet) og ,47 (standardavviket, 0,67, delt på kvadratroten av 3, utvalgsstørrelsen) .
I tilfelle du er interessert i å gjøre denne simuleringen, her er trinnene:
Velg en celle for ditt første tilfeldig valgte nummer.
Velg celle B2.
Bruk regnearkfunksjonen RANDBETWEEN for å velge 1, 2 eller 3.
Dette simulerer å tegne et tall fra en populasjon som består av tallene 1, 2 og 3 hvor du har lik sjanse til å velge hvert tall. Du kan enten velge FORMLER | Matematikk og trig | RANDBETWEEN og bruk dialogboksen Function Arguments eller bare skriv =RANDBETWEEN(1,3) i B2 og trykk Enter. Det første argumentet er det minste tallet RANDBETWEEN returnerer, og det andre argumentet er det største tallet.
Velg cellen til høyre for den opprinnelige cellen og velg et annet tilfeldig tall mellom 1 og 3. Gjør dette igjen for et tredje tilfeldig tall i cellen til høyre for det andre.
Den enkleste måten å gjøre dette på er å autofylle de to cellene til høyre for den opprinnelige cellen. I dette regnearket er de to cellene C2 og D2.
Betrakt disse tre cellene som en prøve, og beregn deres gjennomsnitt i cellen til høyre for den tredje cellen.
Den enkleste måten å gjøre dette på er bare å skrive =AVERAGE(B2:D2) i celle E2 og trykke Enter.
Gjenta denne prosessen for så mange prøver du vil inkludere i simuleringen. La hver rad tilsvare en prøve.
Her ble det brukt 60 prøver. Den raske og enkle måten å få dette til er å velge den første raden av tre tilfeldig valgte tall og deres gjennomsnitt og deretter autofylle de resterende radene. Settet med prøvemidler i kolonne E er den simulerte prøvetakingsfordelingen av gjennomsnittet. Bruk AVERAGE og STDEV.P for å finne gjennomsnittet og standardavviket.
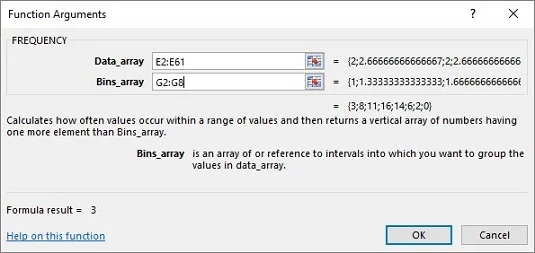
For å se hvordan denne simulerte samplingsfordelingen ser ut, bruk array-funksjonen FREQUENCY på prøvemidlene i kolonne E. Følg disse trinnene:
Skriv inn de mulige verdiene for prøvegjennomsnittet i en matrise.
Du kan bruke kolonne G til dette. Du kan uttrykke de mulige verdiene for prøvegjennomsnittet i brøkform (3/3, 4/3, 5/3, 6/3, 7/3, 8/3 og 9/3) som de som er lagt inn i cellene G2 til G8. Excel konverterer dem til desimalform. Sørg for at disse cellene er i tallformat.
Velg en matrise for frekvensene til de mulige verdiene for prøvegjennomsnittet.
Du kan bruke kolonne H til å holde frekvensene ved å velge cellene H2 til H8.
Fra menyen Statistiske funksjoner, velg FREKVENS for å åpne dialogboksen Funksjonsargumenter for FREKVENS
I dialogboksen Funksjonsargumenter skriver du inn de riktige verdiene for argumentene.
I Data_array-boksen skriver du inn cellene som inneholder prøveverdien. I dette eksemplet er det E2:E61.
Identifiser matrisen som inneholder de mulige verdiene for prøvegjennomsnittet.
FREQUENCY holder denne matrisen i Bins_array-boksen. For dette regnearket går G2:G8 inn i Bins_array-boksen. Etter at du har identifisert begge matrisene, viser dialogboksen Funksjonsargumenter frekvensene innenfor et par krøllede parenteser.![(Omtrent) Simulering av sentralgrensesetningen i Excel]()
Trykk Ctrl+Shift+Enter for å lukke dialogboksen Funksjonsargumenter og vise frekvensene.
Bruk denne tastetrykkkombinasjonen fordi FREKVENS er en matrisefunksjon.
Til slutt, med H2:H8 uthevet, velg Sett inn | Anbefalte diagrammer og velg Clustered Column-oppsettet for å lage grafen over frekvensene. Grafen din vil sannsynligvis se noe annerledes ut enn min, fordi du sannsynligvis vil ende opp med et annet tilfeldig tall.
Excel gjentar forresten den tilfeldige utvalgsprosessen hver gang du gjør noe som får Excel til å beregne regnearket på nytt. Effekten er at tallene kan endre seg etter hvert som du jobber deg gjennom dette. (Det vil si at du kjører simuleringen på nytt.) Hvis du for eksempel går tilbake og autofyller en av radene igjen, endres tallene og grafen endres.