Excel er et fantastisk verktøy når du skal bruke statistikk. Hvis du aldri har vært utsatt for statistikk på skolen eller det har gått et tiår eller to siden du var, la disse tipsene hjelpe deg med å bruke noen av de statistiske verktøyene som Excel gir.
Beskrivende statistikk er grei
Det første du bør vite er at noen statistiske analyser og noen statistiske mål er ganske enkle. Beskrivende statistikk, som inkluderer ting som pivottabellkrysstabellene, samt noen av de statistiske funksjonene, gir mening selv for noen som ikke er så kvantitative.
Gjennomsnitt er ikke så enkelt noen ganger
Når noen bruker begrepet gjennomsnitt, er det han vanligvis refererer til den vanligste gjennomsnittsmålingen, som er et gjennomsnitt. Å forstå at begrepet gjennomsnitt er upresist gjør mye av Excels statistiske funksjonalitet mer forståelig.
For å gjøre denne diskusjonen mer konkret, anta at du ser på et lite sett med verdier: 1, 2, 3, 4 og 5. Som du kanskje vet, er gjennomsnittet i dette lille settet med verdier 3. Du kan regne ut gjennomsnittet ved å legge sammen alle tallene i settet (1+2+3+4+5) og deretter dele denne summen (15) med det totale antallet verdier i settet (5).
Den Medianverdien er den verdien som skiller de største verdiene fra de minste verdiene. I datasettet 1, 2, 3, 4 og 5 er medianen 3. Verdien 3 skiller de største verdiene (4 og 5) fra de minste verdiene (1 og 2).
Du trenger ikke forstå forskjellige gjennomsnittsmålinger, men du bør huske at begrepet gjennomsnitt er ganske upresist.
Standardavvik beskriver spredning
Formelen for standardavvik og logikken er ganske enkle å forstå.
Et standardavvik beskriver hvordan verdier i et datasett varierer rundt gjennomsnittet. Det fine med statistiske mål som standardavvik, du får ofte reell innsikt i egenskapene til dataene du ser på. En annen ting er at med disse to databitene kan du ofte trekke slutninger om data ved å se på prøver.
En observasjon er en observasjon
Observasjon er et av begrepene du vil støte på hvis du leser noe om statistikk. En observasjon er bare en observasjon. En måte å definere begrepet observasjon på er slik: Når du faktisk tildeler en verdi til en av de tilfeldige variablene dine, oppretter du en observasjon.
Et utvalg er en delmengde av verdier
Et utvalg er en samling observasjoner fra en populasjon. Hvis du for eksempel lager et datasett som registrerer den daglige høye temperaturen i nabolaget ditt, er den lille samlingen av observasjoner et eksempel.
Til sammenligning er et utvalg ikke en populasjon. En populasjon inkluderer alle mulige observasjoner.
Inferensiell statistikk er kul, men komplisert
Hvis du ser på et utvalg verdier fra en populasjon og utvalget er representativt og stort nok, kan du trekke konklusjoner om populasjonen basert på egenskaper ved utvalget.
Inferensiell statistikk, selv om den er veldig kraftig, har to egenskaper du trenger å vite:
-
Nøyaktighetsproblemer
-
Bratt læringskurve
Sannsynlighetsfordelingsfunksjoner er ikke alltid forvirrende
P robability fordelingsfunksjonen høres ganske vanskelig; men du kan faktisk forstå intuitivt hva en sannsynlighetsfordelingsfunksjon er med et par nyttige eksempler.
En vanlig fordeling du hører om i statistikkklasser, for eksempel, er en T-fordeling. En T-fordeling er i hovedsak en normalfordeling bortsett fra med tyngre, fetere haler.
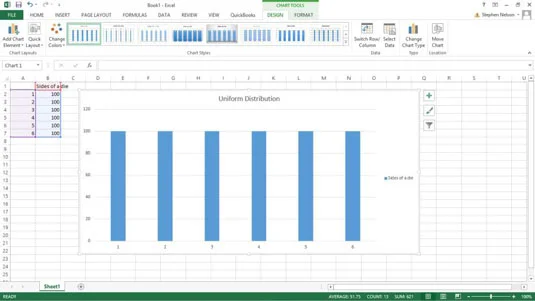
En vanlig sannsynlighetsfordelingsfunksjon er en enhetlig fordeling. I en enhetlig fordeling har hver hendelse samme sannsynlighet for å inntreffe. Det unike med denne distribusjonen er at alt er ganske jævla nivå.
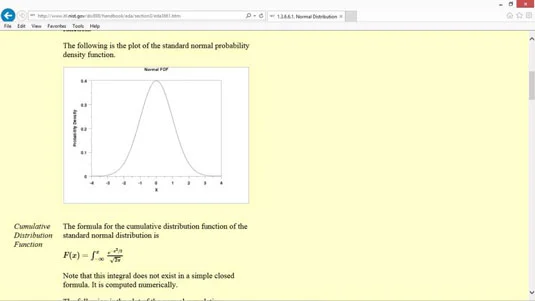
En annen vanlig type sannsynlighetsfordelingsfunksjon er normalfordelingen, også kjent som en klokkekurve eller en gaussisk fordeling.
En normalfordeling forekommer naturlig i mange situasjoner. For eksempel er intelligenskvotienter (IQ) normalfordelt.
![10 ting du bør vite om statistikk for å bruke Excel]()
Parametre er ikke så kompliserte
En parameter er en inngang til sannsynlighetsfordelingsfunksjonen. Formelen eller funksjonen eller ligningen som beskriver en sannsynlighetsfordelingskurve trenger med andre ord input. I statistikk kalles disse inngangene parametere.
Noen sannsynlighetsfordelingsfunksjoner trenger bare en enkel parameter. For eksempel, for å jobbe med en enhetlig fordeling, trenger du bare antall verdier i datasettet. En sekssidig terning, for eksempel, har bare seks muligheter.
Skjevhet og kurtose beskriver en sannsynlighetsfordelings form
Et par andre nyttige statistiske termer å vite er skjevhet og kurtose. Skjevhet kvantifiserer mangelen på symmetri i en sannsynlighetsfordeling. I en perfekt symmetrisk fordeling, som normalfordelingen, er skjevheten lik null. Hvis en sannsynlighetsfordeling heller til høyre eller venstre, er skjevheten lik en annen verdi enn null, og verdien kvantifiserer mangelen på symmetri.
Kurtosis kvantifiserer tyngden av halene i en fordeling. I en normalfordeling er kurtosis lik null. Den halen er det som når ut til venstre eller høyre. Men hvis en hale i en fordeling er tyngre enn en normalfordeling, er kurtosis et positivt tall. Hvis halene i en fordeling er tynnere enn i en normalfordeling, er kurtosis et negativt tall.
Konfidensintervaller virker kompliserte i begynnelsen, men er nyttige
Sannsynligheter forvirrer ofte folk. En viktig ting å forstå om konfidensnivåer er at de er knyttet til feilmarginen.
En annen viktig ting å forstå om konfidensnivåer er at jo større du gjør prøvestørrelsen, desto mindre vil feilmarginen din bruke samme konfidensnivå.
Som bare ett eksempel kan du si at du hadde noen Google Analytics-data om to forskjellige nettannonser du kjører for å markedsføre den lille bedriften din, og du vil vite hvilken annonse som er mer effektiv. Du kan bruke konfidensintervallformelen for å finne ut hvor lenge annonsene dine må kjøre før Google har samlet inn nok data til at du vet hvilken annonse som egentlig er best.