Når du publiserer Power Pivot-rapporter på nettet, har du tenkt å gi publikum en best mulig opplevelse. En stor del av den erfaringen er å sikre at ytelsen er god. Ordet ytelse (som det gjelder applikasjoner og rapportering) er vanligvis synonymt med hastighet - eller hvor raskt en applikasjon utfører visse handlinger som å åpne i nettleseren, kjøre spørringer eller filtrere.
1Begrens antall rader og kolonner i datamodelltabellene.
En stor innflytelse på Power Pivot-ytelsen er antallet kolonner du tar med eller importerer inn i datamodellen. Hver kolonne du importerer er en dimensjon til som Power Pivot må behandle når du laster inn en arbeidsbok. Ikke importer ekstra kolonner "i tilfelle" - hvis du ikke er sikker på at du vil bruke visse kolonner, bare ikke ta dem inn. Disse kolonnene er enkle å legge til senere hvis du finner ut at du trenger dem.
Flere rader betyr mer data å laste, mer data å filtrere og mer data å beregne. Unngå å velge et helt bord hvis du ikke må. Bruk en spørring eller en visning i kildedatabasen for å filtrere etter bare radene du trenger å importere. Tross alt, hvorfor importere 400 000 rader med data når du kan bruke en enkel WHERE-klausul og bare importere 100 000?
2Bruk visninger i stedet for tabeller.
Når vi snakker om synspunkter, for beste praksis, bruk synspunkter når det er mulig.
Selv om tabeller er mer transparente enn visninger – slik at du kan se alle de rå, ufiltrerte dataene – kommer de med alle tilgjengelige kolonner og rader, enten du trenger dem eller ikke. For å holde Power Pivot-datamodellen din i en håndterbar størrelse, blir du ofte tvunget til å ta det ekstra trinnet å eksplisitt filtrere ut kolonnene du ikke trenger.
Visninger kan ikke bare gi renere, mer brukervennlige data, men også bidra til å strømlinjeforme Power Pivot-datamodellen din ved å begrense mengden data du importerer.
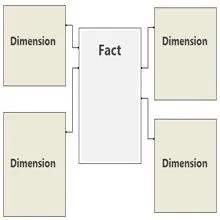
3 Unngå relasjoner på flere nivåer.
Både antall relasjoner og antall relasjonslag har innvirkning på ytelsen til Power Pivot-rapportene dine. Når du bygger modellen din, følg beste praksis og ha en enkelt faktatabell som hovedsakelig inneholder kvantitative numeriske data (fakta) og dimensjonstabeller som er direkte relatert til fakta. I databaseverdenen er denne konfigurasjonen et stjerneskjema, som vist.
Unngå å bygge modeller der dimensjonstabeller relaterer seg til andre dimensjonstabeller.
4 La back-end-databaseserverne gjøre knusingen.
De fleste Excel-analytikere som er nye til Power Pivot har en tendens til å hente rådata direkte fra tabellene på deres eksterne databaseservere. Etter at rådataene er i Power Pivot, bygger de beregnede kolonner og mål for å transformere og aggregere dataene etter behov. For eksempel trekker brukere vanligvis inntekts- og kostnadsdata og lager deretter en beregnet kolonne i Power Pivot for å beregne fortjeneste.
Så hvorfor få Power Pivot til å gjøre denne beregningen når back-end-serveren kunne ha håndtert det? Realiteten er at back-end databasesystemer som SQL Server har evnen til å forme, aggregere, rense og transformere data mye mer effektivt enn Power Pivot. Hvorfor ikke bruke deres kraftige evner til å massere og forme data før du importerer dem til Power Pivot?
I stedet for å hente rå tabelldata, bør du vurdere å utnytte spørringer, visninger og lagrede prosedyrer for å utføre så mye av dataaggregeringen som mulig. Denne utnyttelsen reduserer mengden prosessering som Power Pivot må gjøre og forbedrer naturligvis ytelsen.
5 Pass på kolonner med ikke-distinkte verdier.
Kolonner som har et høyt antall unike verdier er spesielt vanskelige for Power Pivot-ytelsen. Kolonner som Transaksjons-ID, Ordre-ID og Fakturanummer er ofte unødvendige i Power Pivot-rapporter og dashboards på høyt nivå. Så med mindre de er nødvendige for å etablere relasjoner til andre tabeller, la dem være ute av modellen din.
![10 måter å forbedre Power Pivot-ytelsen på]()
6Begrens antall skjærere i en rapport.
Sliceren er en av de beste nye business intelligence (BI)-funksjonene i Excel de siste årene. Ved å bruke slicers kan du gi publikum et intuitivt grensesnitt som muliggjør interaktiv filtrering av Excel-rapporter og dashboards.
En av de mer nyttige fordelene med sliceren er at den reagerer på andre slicers, og gir en gjennomgripende filtereffekt. For eksempel illustrerer figuren ikke bare at ved å klikke på Midtvesten i Region-utsnittet filtrerer pivottabellen, men at Markedsutsnittet også reagerer ved å fremheve markedene som tilhører Midtvest-regionen. Microsoft kaller denne oppførselen kryssfiltrering.
Så nyttig som sliceren er, er den dessverre ekstremt dårlig for Power Pivot-ytelsen. Hver gang en slicer endres, må Power Pivot beregne alle verdier og mål i pivottabellen på nytt. For å gjøre det, må Power Pivot evaluere hver flis i den valgte sliceren og behandle de riktige beregningene basert på utvalget.
7 Opprett skjærere kun på dimensjonsfelt.
Slicers knyttet til kolonner som inneholder mange unike verdier vil ofte føre til et større ytelsestreff enn kolonner som inneholder bare en håndfull verdier. Hvis en slicer inneholder et stort antall fliser, bør du vurdere å bruke en rullegardinliste for pivottabellfilter i stedet.
På et lignende notat, sørg for å ha riktig størrelse på kolonnedatatyper. En kolonne med få distinkte verdier er lettere enn en kolonne med et høyt antall distinkte verdier. Hvis du lagrer resultatene av en beregning fra en kildedatabase, reduser antallet sifre (etter desimalen) som skal importeres. Dette reduserer størrelsen på ordboken og, muligens, antallet distinkte verdier.
![10 måter å forbedre Power Pivot-ytelsen på]()
8Deaktiver kryssfilteratferden for visse skjærere.
Deaktivering av kryssfilteratferden til en slicer forhindrer i hovedsak at sliceren endrer valg når andre slicer klikkes. Dette forhindrer behovet for Power Pivot for å evaluere titlene i den deaktiverte sliceren, og dermed redusere behandlingssyklusene. For å deaktivere kryssfilteratferden til en slicer, velg Slicer Settings for å åpne dialogboksen Slicer Settings. Deretter fjerner du bare valget Visuelt Vis elementer uten data.
9Bruk beregnede mål i stedet for beregnede kolonner.
Bruk beregnede mål i stedet for beregnede kolonner, hvis mulig. Beregnede kolonner lagres som importerte kolonner. Fordi beregnede kolonner iboende samhandler med andre kolonner i modellen, beregner de hver gang pivottabellen oppdateres, enten de brukes eller ikke. Beregnede mål, derimot, beregner kun på spørretidspunktet.
Beregnede kolonner ligner vanlige kolonner ved at de begge tar plass i modellen. Derimot beregnes beregnede mål på flukt og tar ikke plass.
10 Oppgrader til 64-biters Excel.
Hvis du fortsetter å få ytelsesproblemer med Power Pivot-rapportene dine, kan du alltid kjøpe en bedre PC – i dette tilfellet ved å oppgradere til en 64-biters PC med 64-biters Excel installert.
Power Pivot laster hele datamodellen inn i RAM når du jobber med den. Jo mer RAM datamaskinen din har, desto færre ytelsesproblemer ser du. 64-biters versjonen av Excel kan få tilgang til mer av PC-ens RAM, noe som sikrer at den har systemressursene som trengs for å gå gjennom større datamodeller. Faktisk anbefaler Microsoft 64-biters Excel for alle som jobber med modeller som består av millioner av rader.
Men før du raskt begynner å installere 64-bit Excel, må du svare på disse spørsmålene:
Har du allerede installert 64-biters Excel?
Er datamodellene dine store nok?
Har du et 64-bits operativsystem installert på din PC?
Vil de andre tilleggene dine slutte å fungere?










