Jak používat příkazy Znovu a Opakovat ve Wordu 2016

Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Abyste mohli používat Power Pivot, nemusíte být zkušeným databázovým modelářem. Ale je důležité rozumět vztahům. Čím lépe pochopíte, jak jsou data v databázích uložena a spravována, tím efektivněji využijete Power Pivot pro vytváření sestav.
Vztah je mechanismus, kterým jsou jednotlivé tabulky vztahující se k sobě navzájem. Vztah si můžete představit jako SVYHLEDAT, ve kterém spojíte data v jednom datovém rozsahu s daty v jiném datovém rozsahu pomocí indexu nebo jedinečného identifikátoru. V databázích dělají vztahy totéž, ale bez potíží s psaním vzorců.
Vztahy jsou důležité, protože většina dat, se kterými pracujete, zapadá do vícerozměrné hierarchie druhů. Můžete mít například tabulku se zákazníky, kteří nakupují produkty. Tito zákazníci vyžadují faktury s čísly faktur. Tyto faktury obsahují několik řádků transakcí se seznamem toho, co koupili. Existuje tam hierarchie.
Nyní, ve světě jednorozměrných tabulek, by tato data byla obvykle uložena v ploché tabulce, jako je ta, která je zde zobrazena.
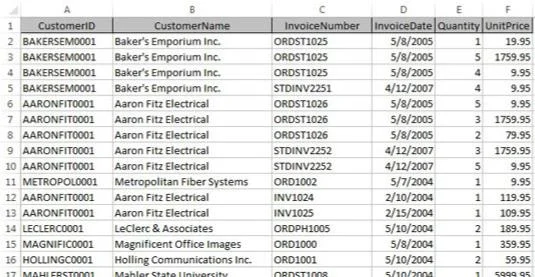
Data jsou uložena v tabulkovém procesoru Excel ve formátu ploché tabulky.
Protože zákazníci mají více než jednu fakturu, musí se informace o zákazníkovi (v tomto příkladu CustomerID a CustomerName) opakovat. To způsobuje problém, když je třeba tato data aktualizovat.
Představte si například, že se název společnosti Aaron Fitz Electrical změní na Fitz and Sons Electrical. Při pohledu na tabulku vidíte, že několik řádků obsahuje starý název. Budete muset zajistit, aby každý řádek obsahující starý název společnosti byl aktualizován, aby odrážel změnu. Žádné řádky, které vynecháte, nebudou správně mapovány zpět na správného zákazníka.
Nebylo by logičtější a efektivnější zaznamenat jméno a údaje zákazníka pouze jednou? Pak byste místo toho, abyste museli opakovaně psát stejné informace o zákazníkovi, mohli mít jednoduše nějakou formu zákaznického referenčního čísla.
To je myšlenka za vztahy. Zákazníky můžete oddělit od faktur a každého umístit do vlastních tabulek. Potom můžete použít jedinečný identifikátor (například CustomerID), abyste je spojili.
Následující obrázek ukazuje, jak by tato data vypadala v relační databázi. Data by byla rozdělena do tří samostatných tabulek: Customers, InvoiceHeader a InvoiceDetails. Každá tabulka by pak byla propojena pomocí jedinečných identifikátorů (v tomto případě CustomerID a InvoiceNumber).

Databáze používají vztahy k ukládání dat v jedinečných tabulkách a jednoduše tyto tabulky vzájemně spojují.
Tabulka Zákazníci by obsahovala jedinečný záznam pro každého zákazníka. Tímto způsobem, pokud potřebujete změnit jméno zákazníka, budete muset provést změnu pouze v tomto záznamu. V reálném životě by tabulka Zákazníci samozřejmě obsahovala další atributy, jako je adresa zákazníka, telefonní číslo zákazníka a datum zahájení. Kterýkoli z těchto dalších atributů lze také snadno uložit a spravovat v tabulce Zákazníci.
Nejběžnějším typem vztahu je vztah jeden k mnoha . To znamená, že pro každý záznam v jedné tabulce lze jeden záznam přiřadit mnoha záznamům v samostatné tabulce. Například tabulka záhlaví faktury souvisí s tabulkou podrobností faktury. Tabulka záhlaví faktury má jedinečný identifikátor: Číslo faktury. Detail faktury použije číslo faktury pro každý záznam představující detail dané faktury.
Dalším typem vztahu je vztah jeden k jednomu : Pro každý záznam v jedné tabulce je jeden a pouze jeden odpovídající záznam v jiné tabulce. Data z různých tabulek ve vztahu jedna ku jedné lze technicky spojit do jediné tabulky.
A konečně, ve vztahu many-to-many mohou mít záznamy v obou tabulkách libovolný počet odpovídajících záznamů v druhé tabulce. Například databáze v bance může obsahovat tabulku různých typů úvěrů (úvěr na bydlení, úvěr na auto atd.) a tabulku zákazníků. Zákazník může mít mnoho typů úvěrů. Mezitím lze každý typ úvěru poskytnout mnoha zákazníkům.
Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Naučte se, jak efektivně změnit stav buněk v Excelu 2010 z uzamčených na odemčené nebo z neskrytého na skrytý s naším podrobným průvodcem.
Zjistěte, jak efektivně využít překladové nástroje v Office 2016 pro překlad slov a frází. Překlad Gizmo vám pomůže překládat text s lehkostí.
Šablona ve Wordu šetří čas a usnadňuje vytváření dokumentů. Zjistěte, jak efektivně používat šablony ve Wordu 2013.
Zjistěte, jak si vytvořit e-mailová upozornění ve SharePointu a zůstat informováni o změnách v dokumentech a položkách.
Objevte skvělé funkce SharePoint Online, včetně tvorby a sdílení dokumentů a typů obsahu pro efektivnější správu dat.
Zjistěte, jak vypočítat fiskální čtvrtletí v Excelu pro různá data s použitím funkce CHOOSE.
Zjistěte, jak vytvořit hypertextový odkaz v PowerPointu, který vám umožní pohodlně navigovat mezi snímky. Použijte náš návod na efektivní prezentace.
Uložili jste nedávno svůj dokument? Náš návod vám ukáže, jak zobrazit starší verze dokumentu v aplikaci Word 2016.
Jak přiřadit makra vlastní kartě na pásu karet nebo tlačítku na panelu nástrojů Rychlý přístup. Návod pro Excel 2013.





