Jak používat příkazy Znovu a Opakovat ve Wordu 2016

Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Jako stavební kámen pro vaše sestavy Excel musí být data ve vašich datových modelech vhodně strukturována. Ne všechny datové sady jsou vytvořeny stejně. Ačkoli některé datové sady fungují ve standardním prostředí Excelu, nemusí fungovat pro účely datového modelování. Před vytvořením datového modelu se ujistěte, že jsou vaše zdrojová data vhodně strukturována pro účely dashboardu.
S rizikem přílišného zjednodušení mají datové sady obvykle používané v Excelu tři základní formy:
Tabulkový přehled
Plochý datový soubor
Tabulková datová sada
Pointa je, že pouze ploché datové soubory a tabulkové datové sady tvoří efektivní datové modely.
Tabulkové sestavy zobrazují vysoce formátovaná, souhrnná data a jsou často navrženy jako prezentační nástroje pro manažery nebo výkonné uživatele. Typický tabulkový procesor uvážlivě využívá prázdný prostor pro formátování, opakuje data pro estetické účely a představuje pouze analýzu na vysoké úrovni. Následující obrázek ilustruje tabulkový procesor.
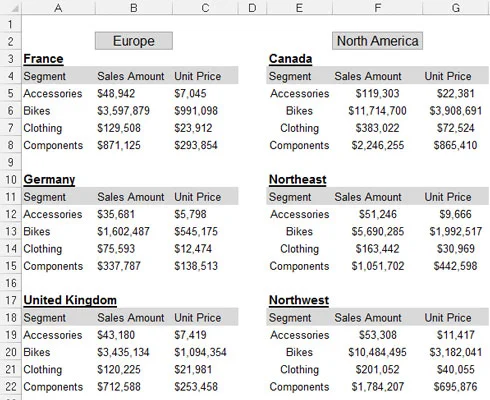
Tabulkový přehled.
Přestože tabulkový kalkulátor může vypadat hezky, nevytváří efektivní datový model. Proč? Hlavním důvodem je, že tyto sestavy nenabízejí žádné oddělení dat, analýzy a prezentace. Jste v podstatě uzavřeni do jedné analýzy.
I když byste ze zobrazené sestavy mohli vytvořit grafy, bylo by nepraktické použít jakoukoli analýzu mimo to, co již existuje. Jak byste například pomocí této konkrétní zprávy vypočítali a prezentovali průměr všech prodejů kol? Jak byste vypočítali seznam deseti nejvýkonnějších trhů?
S tímto nastavením jste nuceni do velmi manuálních procesů, které je obtížné udržovat měsíc po měsíci. Jakákoli analýza mimo ty na vysoké úrovni, které jsou již ve zprávě uvedeny, je přinejlepším základní – dokonce i s efektními vzorci. Navíc, co se stane, když budete muset ukazovat prodeje kol po měsících? Když váš datový model vyžaduje analýzu s daty, která nejsou v tabulkové sestavě, jste nuceni hledat jinou datovou sadu.
Dalším typem formátu souboru je plochý soubor. Ploché soubory jsou datová úložiště organizovaná podle řádků a sloupců. Každý řádek odpovídá sadě datových prvků nebo záznamu. Každý sloupec je pole. Pole odpovídá jedinečnému datovému prvku v záznamu. Následující obrázek obsahuje stejná data jako předchozí zpráva, ale vyjádřená ve formátu plochého datového souboru.
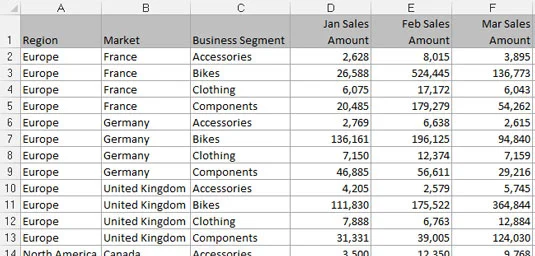
Plochý datový soubor.
Všimněte si, že každé datové pole má sloupec a každý sloupec odpovídá jednomu datovému prvku. Kromě toho zde nejsou žádné další mezery a každý řádek (nebo záznam) odpovídá jedinečné sadě informací. Ale klíčovým atributem, který z tohoto dělá plochý soubor, je to, že žádné jedno pole jednoznačně neidentifikuje záznam. Ve skutečnosti byste museli zadat čtyři samostatná pole (Region, Market, Business Segment a měsíční objem prodeje), než budete moci záznam jednoznačně identifikovat.
Ploché soubory se dobře hodí pro datové modelování v Excelu, protože mohou být dostatečně podrobné, aby obsahovaly data, která potřebujete, a stále umožňují širokou škálu analýz pomocí jednoduchých vzorců – SUM, AVERAGE, SVYHLEDAT a SUMIF, abychom jmenovali alespoň některé. .
Mnoho efektivních datových modelů je řízeno především kontingenčními tabulkami. Kontingenční tabulky jsou přední analytické nástroje Excelu. Pro ty z vás, kteří používali kontingenční tabulky, víte, že nabízejí vynikající způsob, jak sumarizovat a tvarovat data pro použití komponentami sestav, jako jsou grafy a tabulky.
Tabulkové datové sady jsou ideální pro datové modely řízené kontingenčními tabulkami. Následující obrázek ilustruje tabulkovou datovou sadu. Všimněte si, že primární rozdíl mezi tabulkovou datovou sadou a plochým datovým souborem je ten, že v tabulkových datových sadách se popisky sloupců nezdvojují jako skutečná data. Například sloupec Prodejní období obsahuje identifikátor měsíce. Tento jemný rozdíl ve struktuře je to, co dělá tabulkové datové sady optimálními zdroji dat pro kontingenční tabulky. Tato struktura zajišťuje, že funkce klíčových kontingenčních tabulek, jako je řazení a seskupování, fungují tak, jak mají.
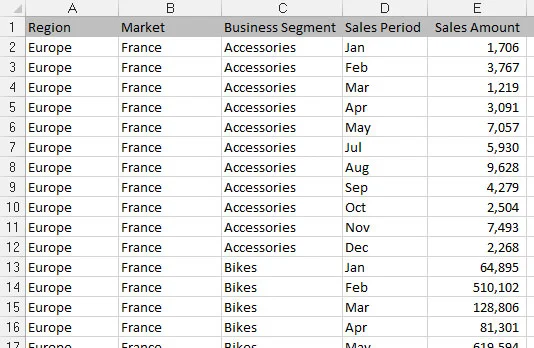
Tabulková datová sada.
Atributy tabulkové datové sady jsou následující:
První řádek datové sady obsahuje popisky polí, které popisují informace v každém sloupci.
Popisky sloupců nevyžadují dvojí povinnost jako datové položky, které lze použít jako filtry nebo kritéria dotazu (jako jsou měsíce, data, roky, oblasti nebo trhy).
Nejsou zde žádné prázdné řádky ani sloupce – každý sloupec má záhlaví a v každém řádku je hodnota.
Každý sloupec představuje jedinečnou kategorii dat.
Každý řádek představuje jednotlivé položky v každém sloupci.
Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Naučte se, jak efektivně změnit stav buněk v Excelu 2010 z uzamčených na odemčené nebo z neskrytého na skrytý s naším podrobným průvodcem.
Zjistěte, jak efektivně využít překladové nástroje v Office 2016 pro překlad slov a frází. Překlad Gizmo vám pomůže překládat text s lehkostí.
Šablona ve Wordu šetří čas a usnadňuje vytváření dokumentů. Zjistěte, jak efektivně používat šablony ve Wordu 2013.
Zjistěte, jak si vytvořit e-mailová upozornění ve SharePointu a zůstat informováni o změnách v dokumentech a položkách.
Objevte skvělé funkce SharePoint Online, včetně tvorby a sdílení dokumentů a typů obsahu pro efektivnější správu dat.
Zjistěte, jak vypočítat fiskální čtvrtletí v Excelu pro různá data s použitím funkce CHOOSE.
Zjistěte, jak vytvořit hypertextový odkaz v PowerPointu, který vám umožní pohodlně navigovat mezi snímky. Použijte náš návod na efektivní prezentace.
Uložili jste nedávno svůj dokument? Náš návod vám ukáže, jak zobrazit starší verze dokumentu v aplikaci Word 2016.
Jak přiřadit makra vlastní kartě na pásu karet nebo tlačítku na panelu nástrojů Rychlý přístup. Návod pro Excel 2013.





