Jak používat příkazy Znovu a Opakovat ve Wordu 2016

Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Abychom vám pomohli porozumět statistické analýze v Excelu, pomůže vám simulovat Centrální limitní teorém. Skoro to nezní správně. Jak může populace, která není normálně distribuována, vyústit v normálně distribuovanou distribuci vzorkování?
Abyste měli představu, jak funguje Centrální limitní věta, existuje simulace. Tato simulace vytváří něco jako vzorkování distribuce průměru pro velmi malý vzorek na základě populace, která není normálně rozdělena. Jak uvidíte, i když populace není normální rozdělení, a přestože je vzorek malý, výběrové rozdělení průměru vypadá docela jako normální rozdělení.
Představte si obrovskou populaci, která se skládá pouze ze tří skóre – 1, 2 a 3 – a každé z nich se stejně pravděpodobně objeví ve vzorku. Představte si také, že můžete náhodně vybrat vzorek tří skóre z této populace.
Všechny možné vzorky tří skóre (a jejich průměry) z populace sestávající ze skóre 1, 2 a 3
| Vzorek | Znamenat | Vzorek | Znamenat | Vzorek | Znamenat |
| 1,1,1 | 1,00 | 2,1,1 | 1.33 | 3,1,1 | 1,67 |
| 1,1,2 | 1.33 | 2,1,2 | 1,67 | 3,1,2 | 2,00 |
| 1,1,3 | 1,67 | 2,1,3 | 2,00 | 3,1,3 | 2.33 |
| 1,2,1 | 1.33 | 2,2,1 | 1,67 | 3,2,1 | 2,00 |
| 1,2,2 | 1,67 | 2,2,2 | 2,00 | 3,2,2 | 2.33 |
| 1,2,3 | 2,00 | 2,2,3 | 2.33 | 3,2,3 | 2.67 |
| 1,3,1 | 1,67 | 2,3,1 | 2,00 | 3,3,1 | 2.33 |
| 1,3,2 | 2,00 | 2,3,2 | 2.33 | 3,3,2 | 2.67 |
| 1,3,3 | 2.33 | 2,3,3 | 2.67 | 3,3,3 | 3,00 |
Když se pozorně podíváte na tabulku, můžete téměř vidět, co se v simulaci děje. Nejčastěji se objevující průměr vzorku je 2,00. Vzorové prostředky, které se objevují nejméně často, jsou 1,00 a 3,00. Hmmm . . .
V simulaci bylo náhodně vybráno skóre z populace a poté náhodně vybrány další dvě. Tato skupina tří skóre je vzorek. Pak vypočítáte průměr tohoto vzorku. Tento proces byl opakován pro celkem 60 vzorků, což vedlo k 60 průměrům vzorků. Nakonec vykreslíte graf distribuce průměrů vzorku.
Jak vypadá simulované vzorkování rozdělení střední hodnoty? Níže uvedený obrázek ukazuje pracovní list, který odpovídá na tuto otázku.
V listu je každý řádek ukázkou. Sloupce označené x1, x2 a x3 ukazují tři skóre pro každý vzorek. Sloupec E ukazuje průměr pro vzorek v každém řádku. Sloupec G ukazuje všechny možné hodnoty pro průměr vzorku a sloupec H ukazuje, jak často se každý průměr objevuje v 60 vzorcích. Sloupce G a H a graf ukazují, že rozdělení má maximální frekvenci, když je průměr vzorku 2,00. Frekvence se snižují, jak se vzorkovací prostředky stále více vzdalují od 2,00.
Pointou toho všeho je, že populace nevypadá jako normální rozdělení a velikost vzorku je velmi malá. I při těchto omezeních začíná výběrové rozdělení průměru založeného na 60 vzorcích vypadat velmi podobně jako normální rozdělení.
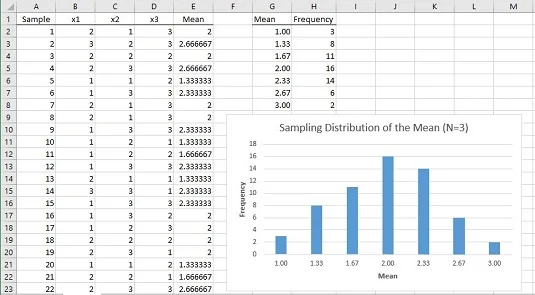
A co parametry, které Centrální limitní teorém předpovídá pro distribuci vzorkování? Začněte s populací. Průměr populace je 2,00 a standardní odchylka populace je 0,67. (Tento druh populace vyžaduje trochu fantazijní matematiky pro zjištění parametrů.)
Ještě k distribuci vzorkování. Průměr 60 průměrů je 1,98 a jejich standardní odchylka (odhad standardní chyby průměru) je 0,48. Tato čísla se těsně blíží parametrům předpovězeným Centrálním limitním teorémem pro výběrové rozdělení průměru, 2,00 (rovná se průměru populace) a 0,47 (směrodatná odchylka, 0,67, děleno druhou odmocninou ze 3, velikost vzorku) .
V případě, že máte zájem o provedení této simulace, zde jsou kroky:
Vyberte buňku pro první náhodně vybrané číslo.
Vyberte buňku B2.
Pomocí funkce listu RANDBETWEEN vyberte 1, 2 nebo 3.
To simuluje vytažení čísla ze základního souboru sestávajícího z čísel 1, 2 a 3, kde máte stejnou šanci vybrat každé číslo. Můžete buď vybrat VZORCE | Math & Trig | RANDBETWEEN a použijte dialogové okno Argumenty funkcí nebo jednoduše zadejte =RANDBETWEEN(1,3) v B2 a stiskněte Enter. První argument je nejmenší číslo, které RANDBETWEEN vrátí, a druhý argument je největší číslo.
Vyberte buňku napravo od původní buňky a vyberte další náhodné číslo mezi 1 a 3. Udělejte to znovu pro třetí náhodné číslo v buňce napravo od druhého.
Nejjednodušší způsob, jak toho dosáhnout, je automaticky vyplnit dvě buňky napravo od původní buňky. V tomto listu jsou tyto dvě buňky C2 a D2.
Považujte tyto tři buňky za vzorek a vypočítejte jejich průměr v buňce napravo od třetí buňky.
Nejjednodušší způsob, jak to udělat, je napsat =AVERAGE(B2:D2) do buňky E2 a stisknout Enter.
Tento proces opakujte pro tolik vzorků, kolik chcete do simulace zahrnout. Nechte každý řádek odpovídat vzorku.
Bylo zde použito 60 vzorků. Rychlý a snadný způsob, jak toho dosáhnout, je vybrat první řádek ze tří náhodně vybraných čísel a jejich střední hodnotu a poté automaticky vyplnit zbývající řádky. Soubor průměrů vzorků ve sloupci E je simulované rozdělení průměru vzorku. Použijte AVERAGE a STDEV.P k nalezení střední hodnoty a standardní odchylky.
Chcete-li vidět, jak tato simulovaná distribuce vzorkování vypadá, použijte funkci pole FREQUENCY na vzorcích ve sloupci E. Postupujte takto:
Zadejte možné hodnoty střední hodnoty vzorku do pole.
K tomu můžete použít sloupec G. Možné hodnoty střední hodnoty vzorku můžete vyjádřit ve formě zlomků (3/3, 4/3, 5/3, 6/3, 7/3, 8/3 a 9/3), jako jsou hodnoty zadané do buněk G2 až G8. Excel je převede do desítkové podoby. Ujistěte se, že tyto buňky jsou ve formátu čísla.
Vyberte pole pro frekvence možných hodnot střední hodnoty vzorku.
Sloupec H můžete použít k uložení frekvencí, výběrem buněk H2 až H8.
Z nabídky Statistické funkce vyberte FREKVENCE a otevřete dialogové okno Argumenty funkcí pro FREKVENCE
V dialogovém okně Argumenty funkce zadejte příslušné hodnoty pro argumenty.
Do pole Data_array zadejte buňky, které obsahují prostředek vzorku. V tomto příkladu je to E2:E61.
Identifikujte pole, které obsahuje možné hodnoty střední hodnoty vzorku.
FREQUENCY obsahuje toto pole v poli Bins_array. Pro tento list přejde G2:G8 do pole Bins_array. Po identifikaci obou polí se v dialogovém okně Argumenty funkcí zobrazí frekvence uvnitř dvojice složených závorek.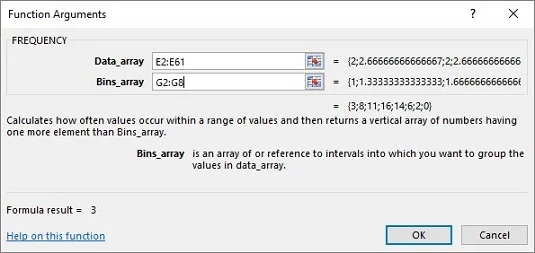
Stisknutím Ctrl+Shift+Enter zavřete dialogové okno Argumenty funkcí a zobrazíte frekvence.
Použijte tuto kombinaci kláves, protože FREQUENCY je funkce pole.
Nakonec se zvýrazněným H2:H8 vyberte Vložit | Doporučené grafy a zvolte rozvržení Clustered Column pro vytvoření grafu frekvencí. Váš graf bude pravděpodobně vypadat poněkud jinak než můj, protože pravděpodobně skončíte s jiným náhodným číslem.
Mimochodem, Excel opakuje proces náhodného výběru, kdykoli uděláte něco, co způsobí, že Excel přepočítá list. Výsledkem je, že čísla se mohou měnit, jak se přes to propracujete. (To znamená, že znovu spustíte simulaci.) Pokud se například vrátíte zpět a znovu automaticky vyplníte jeden z řádků, změní se čísla a změní se graf.
Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Naučte se, jak efektivně změnit stav buněk v Excelu 2010 z uzamčených na odemčené nebo z neskrytého na skrytý s naším podrobným průvodcem.
Zjistěte, jak efektivně využít překladové nástroje v Office 2016 pro překlad slov a frází. Překlad Gizmo vám pomůže překládat text s lehkostí.
Šablona ve Wordu šetří čas a usnadňuje vytváření dokumentů. Zjistěte, jak efektivně používat šablony ve Wordu 2013.
Zjistěte, jak si vytvořit e-mailová upozornění ve SharePointu a zůstat informováni o změnách v dokumentech a položkách.
Objevte skvělé funkce SharePoint Online, včetně tvorby a sdílení dokumentů a typů obsahu pro efektivnější správu dat.
Zjistěte, jak vypočítat fiskální čtvrtletí v Excelu pro různá data s použitím funkce CHOOSE.
Zjistěte, jak vytvořit hypertextový odkaz v PowerPointu, který vám umožní pohodlně navigovat mezi snímky. Použijte náš návod na efektivní prezentace.
Uložili jste nedávno svůj dokument? Náš návod vám ukáže, jak zobrazit starší verze dokumentu v aplikaci Word 2016.
Jak přiřadit makra vlastní kartě na pásu karet nebo tlačítku na panelu nástrojů Rychlý přístup. Návod pro Excel 2013.





