Jak používat příkazy Znovu a Opakovat ve Wordu 2016

Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Excel ví, jak pomoci, když máte více než dva vzorky. Společnost FarKlempt Robotics, Inc., provádí průzkumy svých zaměstnanců ohledně úrovně jejich spokojenosti s jejich zaměstnáním. Požadují od vývojářů, manažerů, pracovníků údržby a technických autorů, aby hodnotili spokojenost s prací na stupnici od 1 (nejméně spokojeni) do 100 (nejspokojenější).
V každé kategorii je šest zaměstnanců. Obrázek níže ukazuje tabulku s daty ve sloupcích A až D, řádky 1–7. Nulová hypotéza je, že všechny vzorky pocházejí ze stejné populace. Alternativní hypotéza je, že ne.
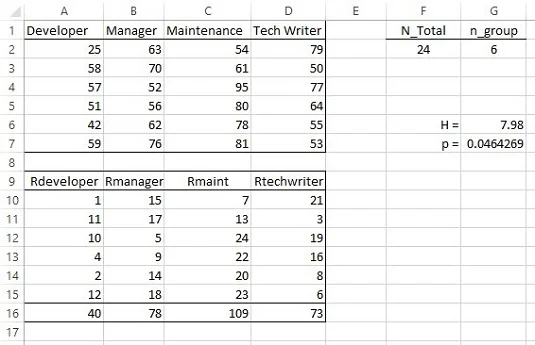
Kruskal–Wallisova jednosměrná analýza rozptylu.
Vhodným neparametrickým testem je Kruskal-Wallisova jednosměrná analýza rozptylu. Začněte seřazením všech 24 skóre ve vzestupném pořadí. Opět platí, že pokud platí nulová hypotéza, pořadí by mělo být ve skupinách rozděleno přibližně rovnoměrně.
Vzorec pro tuto statistiku je
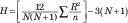
N je celkový počet skóre a n je počet skóre v každé skupině. Pro zjednodušení zadáte v každé skupině stejný počet skóre, ale to není pro tento test nutné. R je součet pořadí ve skupině. H je distribuováno přibližně jako chí-kvadrát s df = počet skupin — 1, když každé n je větší než 5.
Při zpětném pohledu na obrázek jsou pořadí dat v řádcích 9–15 ve sloupcích A až D. Řádek 16 obsahuje součty pořadí v každé skupině. Definujte N_Total jako název pro hodnotu v buňce F2, celkový počet skóre. Definujte n_group jako název pro hodnotu v G2, počet skóre v každé skupině.
Chcete-li vypočítat H , zadejte
=(12/(N_Total*(N_Total+1)))*(SUMSQ(A16:D16)/n_group)-3*(N_Total+1)
do buňky G6.
Pro test hypotéz zadejte
=CHISQ.DIST.RT(G6;3)
do G7. Výsledek je menší než 0,05, takže zamítnete nulovou hypotézu.
Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Naučte se, jak efektivně změnit stav buněk v Excelu 2010 z uzamčených na odemčené nebo z neskrytého na skrytý s naším podrobným průvodcem.
Zjistěte, jak efektivně využít překladové nástroje v Office 2016 pro překlad slov a frází. Překlad Gizmo vám pomůže překládat text s lehkostí.
Šablona ve Wordu šetří čas a usnadňuje vytváření dokumentů. Zjistěte, jak efektivně používat šablony ve Wordu 2013.
Zjistěte, jak si vytvořit e-mailová upozornění ve SharePointu a zůstat informováni o změnách v dokumentech a položkách.
Objevte skvělé funkce SharePoint Online, včetně tvorby a sdílení dokumentů a typů obsahu pro efektivnější správu dat.
Zjistěte, jak vypočítat fiskální čtvrtletí v Excelu pro různá data s použitím funkce CHOOSE.
Zjistěte, jak vytvořit hypertextový odkaz v PowerPointu, který vám umožní pohodlně navigovat mezi snímky. Použijte náš návod na efektivní prezentace.
Uložili jste nedávno svůj dokument? Náš návod vám ukáže, jak zobrazit starší verze dokumentu v aplikaci Word 2016.
Jak přiřadit makra vlastní kartě na pásu karet nebo tlačítku na panelu nástrojů Rychlý přístup. Návod pro Excel 2013.





