Jak používat příkazy Znovu a Opakovat ve Wordu 2016

Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Když publikujete sestavy Power Pivot na web, máte v úmyslu poskytnout svému publiku to nejlepší možné prostředí. Velkou součástí této zkušenosti je zajištění dobrého výkonu. Slovo výkon (související s aplikacemi a sestavováním) je obvykle synonymem pro rychlost – neboli to, jak rychle aplikace provádí určité akce, jako je otevření v prohlížeči, spouštění dotazů nebo filtrování.
Velký vliv na výkon Power Pivot má počet sloupců , které do datového modelu přenesete nebo importujete . Každý importovaný sloupec je další dimenzí, kterou musí Power Pivot zpracovat při načítání sešitu. Neimportujte další sloupce „pro každý případ“ — pokud si nejste jisti, že určité sloupce použijete, prostě je nevkládejte. Tyto sloupce lze snadno přidat později, pokud zjistíte, že je potřebujete.
Více řádků znamená více dat k načtení, více dat k filtrování a více dat k výpočtu. Pokud nemusíte, nevybírejte celý stůl. Pomocí dotazu nebo zobrazení ve zdrojové databázi filtrujte pouze řádky, které potřebujete importovat. Koneckonců, proč importovat 400 000 řádků dat, když můžete použít jednoduchou klauzuli WHERE a importovat pouze 100 000?
Když už mluvíme o pohledech, pro nejlepší praxi používejte pohledy, kdykoli je to možné.
Přestože jsou tabulky průhlednější než pohledy – umožňují vám vidět všechna nezpracovaná, nefiltrovaná data – jsou dodávány se všemi dostupnými sloupci a řádky, ať už je potřebujete nebo ne. Aby byl datový model Power Pivot zachován na zvládnutelné velikosti, jste často nuceni udělat další krok – explicitně odfiltrovat sloupce, které nepotřebujete.
Zobrazení mohou nejen poskytnout čistší a uživatelsky přívětivější data, ale také pomoci zefektivnit datový model Power Pivot omezením množství importovaných dat.
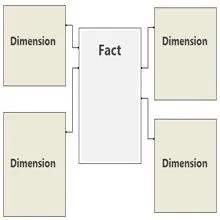
Počet vztahů i počet vrstev vztahů mají vliv na výkon vašich sestav Power Pivot. Při sestavování modelu postupujte podle osvědčených postupů a mějte jednu tabulku faktů obsahující především kvantitativní numerická data (fakta) a tabulky dimenzí, které se přímo vztahují k faktům. Ve světě databází je tato konfigurace hvězdicovým schématem, jak je znázorněno.
Vyhněte se vytváření modelů, kde se tabulky kót vztahují k jiným tabulkám kót.
Většina analytiků Excelu, kteří jsou s Power Pivot noví, mají tendenci stahovat nezpracovaná data přímo z tabulek na svých externích databázových serverech. Poté, co jsou nezpracovaná data v Power Pivot, vytvoří vypočítané sloupce a míry, aby data podle potřeby transformovali a agregovali. Uživatelé například běžně získávají údaje o příjmech a nákladech a poté vytvářejí vypočítaný sloupec v Power Pivot pro výpočet zisku.
Proč tedy nechat Power Pivot provádět tento výpočet, když by to zvládl back-end server? Realita je taková, že back-endové databázové systémy, jako je SQL Server, mají schopnost tvarovat, agregovat, čistit a transformovat data mnohem efektivněji než Power Pivot. Proč nevyužít jejich výkonných schopností k masírování a tvarování dat před jejich importem do Power Pivot?
Spíše než vytahovat nezpracovaná tabulková data zvažte využití dotazů, pohledů a uložených procedur k provedení co největšího množství agregace dat a drcení práce. Toto využití snižuje množství zpracování, které bude muset Power Pivot provést, a přirozeně zvyšuje výkon.
Sloupce, které mají vysoký počet jedinečných hodnot, jsou zvláště náročné na výkon Power Pivot. Sloupce jako ID transakce, ID objednávky a číslo faktury jsou v sestavách a řídicích panelech Power Pivot na vysoké úrovni často zbytečné. Pokud tedy nejsou potřebné k navázání vztahů s jinými tabulkami, vynechejte je ze svého modelu.

Slicer je jednou z nejlepších nových funkcí business intelligence (BI) Excelu v posledních letech. Pomocí průřezů můžete svému publiku poskytnout intuitivní rozhraní, které umožňuje interaktivní filtrování sestav a panelů aplikace Excel.
Jednou z užitečnějších výhod kráječe je, že reaguje na ostatní kráječe a poskytuje efekt kaskádového filtru. Obrázek například ilustruje nejen to, že kliknutím na středozápad v průřezu Region se filtruje kontingenční tabulka, ale že průřez trhů také reaguje zvýrazněním trhů, které patří do regionu Středozápad. Microsoft toto chování nazývá křížové filtrování.
Jakkoli je průřez užitečný, je bohužel extrémně špatný pro výkon Power Pivot. Při každé změně průřezu musí Power Pivot přepočítat všechny hodnoty a míry v kontingenční tabulce. K tomu musí Power Pivot vyhodnotit každou dlaždici ve vybraném průřezu a zpracovat příslušné výpočty na základě výběru.
Průřezy vázané na sloupce, které obsahují mnoho jedinečných hodnot, často způsobí větší zásah do výkonu než sloupce obsahující pouze několik hodnot. Pokud průřez obsahuje velké množství dlaždic, zvažte použití rozevíracího seznamu Filtr kontingenční tabulky.
Podobně se ujistěte, že datové typy sloupců mají správnou velikost. Sloupec s několika odlišnými hodnotami je světlejší než sloupec s vysokým počtem odlišných hodnot. Pokud ukládáte výsledky výpočtu ze zdrojové databáze, snižte počet importovaných číslic (za desetinnou čárkou). Tím se sníží velikost slovníku a případně i počet odlišných hodnot.

Zakázání chování křížového filtru průřezu v podstatě zabrání tomuto průřezu ve změně výběru, když klepnete na jiné průřezy. Tím se zabrání tomu, aby Power Pivot musel vyhodnotit nadpisy v deaktivovaném průřezu, čímž se zkrátí cykly zpracování. Chcete-li zakázat chování křížového filtru průřezu, vyberte Nastavení průřezu a otevřete dialogové okno Nastavení průřezu. Poté jednoduše zrušte výběr možnosti Vizuálně označit položky bez dat.
Pokud je to možné, použijte místo počítaných sloupců vypočítané míry. Vypočítané sloupce jsou uloženy jako importované sloupce. Protože počítané sloupce přirozeně interagují s ostatními sloupci v modelu, počítají pokaždé, když se kontingenční tabulka aktualizuje, bez ohledu na to, zda jsou používány nebo ne. Vypočítané míry se naproti tomu počítají pouze v době dotazu.
Vypočítané sloupce se podobají pravidelným sloupcům v tom, že oba zabírají místo v modelu. Naproti tomu vypočítané míry se počítají za chodu a nezabírají místo.
Pokud budete i nadále narážet na problémy s výkonem u sestav Power Pivot, vždy si můžete koupit lepší počítač – v tomto případě upgradem na 64bitový počítač s nainstalovaným 64bitovým Excelem.
Power Pivot načte celý datový model do paměti RAM, kdykoli s ním pracujete. Čím více paměti RAM má váš počítač, tím méně problémů s výkonem vidíte. 64bitová verze Excelu může přistupovat k větší části paměti RAM vašeho počítače, což zajišťuje, že má systémové prostředky potřebné k procházení většími datovými modely. Společnost Microsoft ve skutečnosti doporučuje 64bitový Excel každému, kdo pracuje s modely složenými z milionů řádků.
Než se však spěšně pustíte do instalace 64bitového Excelu, musíte si odpovědět na tyto otázky:
Máte již nainstalovaný 64bitový Excel?
Jsou vaše datové modely dostatečně velké?
Máte na svém PC nainstalovaný 64bitový operační systém?
Přestanou vaše ostatní doplňky fungovat?
Objevte, jak efektivně využívat příkazy Znovu a Opakovat ve Wordu 2016 pro opravy dokumentů a zlepšení pracovního toku.
Naučte se, jak efektivně změnit stav buněk v Excelu 2010 z uzamčených na odemčené nebo z neskrytého na skrytý s naším podrobným průvodcem.
Zjistěte, jak efektivně využít překladové nástroje v Office 2016 pro překlad slov a frází. Překlad Gizmo vám pomůže překládat text s lehkostí.
Šablona ve Wordu šetří čas a usnadňuje vytváření dokumentů. Zjistěte, jak efektivně používat šablony ve Wordu 2013.
Zjistěte, jak si vytvořit e-mailová upozornění ve SharePointu a zůstat informováni o změnách v dokumentech a položkách.
Objevte skvělé funkce SharePoint Online, včetně tvorby a sdílení dokumentů a typů obsahu pro efektivnější správu dat.
Zjistěte, jak vypočítat fiskální čtvrtletí v Excelu pro různá data s použitím funkce CHOOSE.
Zjistěte, jak vytvořit hypertextový odkaz v PowerPointu, který vám umožní pohodlně navigovat mezi snímky. Použijte náš návod na efektivní prezentace.
Uložili jste nedávno svůj dokument? Náš návod vám ukáže, jak zobrazit starší verze dokumentu v aplikaci Word 2016.
Jak přiřadit makra vlastní kartě na pásu karet nebo tlačítku na panelu nástrojů Rychlý přístup. Návod pro Excel 2013.





