Som byggstenen för dina Excel-rapporter måste data i dina datamodeller struktureras på lämpligt sätt. Alla datauppsättningar är inte skapade lika. Även om vissa datauppsättningar fungerar i en vanlig Excel-miljö, kanske de inte fungerar för datamodelleringsändamål. Innan du bygger din datamodell, se till att dina källdata är korrekt strukturerade för instrumentpanelsändamål.
Med risk för alltför förenkling finns datauppsättningar som vanligtvis används i Excel i tre grundläggande former:
Punch line är att endast platta datafiler och tabelluppsättningar ger effektiva datamodeller.
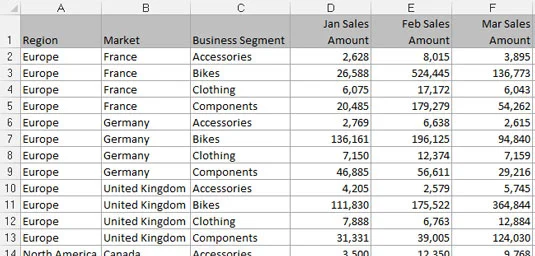
Kalkylbladsrapporter skapar ineffektiva datamodeller
Kalkylbladsrapporter visar högformaterade, sammanfattade data och är ofta utformade som presentationsverktyg för ledning eller verkställande användare. En typisk kalkylarksrapport använder sig av tomt utrymme för formatering, upprepar data i estetiska syften och presenterar endast analyser på hög nivå. Följande bild illustrerar en kalkylbladsrapport.
En kalkylbladsrapport.
Även om en kalkylarksrapport kan se snygg ut, är den inte en effektiv datamodell. Varför? Det främsta skälet är att dessa rapporter inte erbjuder dig någon separation av data, analys och presentation. Du är i princip låst i en analys.
Även om du kan göra diagram från rapporten som visas, skulle det vara opraktiskt att tillämpa någon analys utanför det som redan finns där. Hur skulle du till exempel beräkna och presentera genomsnittet av all cykelförsäljning med den här rapporten? Hur skulle du beräkna en lista över de tio bäst presterande marknaderna?
Med den här inställningen tvingas du in i mycket manuella processer som är svåra att underhålla månad efter månad. Alla analyser utanför de på hög nivå som redan finns i rapporten är i bästa fall grundläggande - även med snygga formler. Dessutom, vad händer när du måste visa cykelförsäljning per månad? När din datamodell kräver analys med data som inte finns i kalkylarksrapporten, tvingas du söka efter en annan datauppsättning.
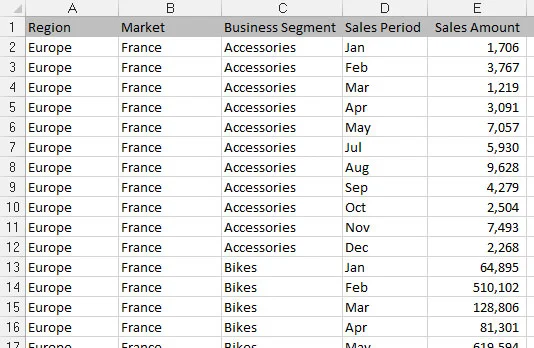
Platta datafiler lämpar sig väl för datamodeller
En annan typ av filformat är en platt fil. Platta filer är datalager organiserade efter rad och kolumn. Varje rad motsvarar en uppsättning dataelement, eller en post. Varje kolumn är ett fält. Ett fält motsvarar ett unikt dataelement i en post. Följande figur innehåller samma data som föregående rapport men uttryckt i ett platt datafilformat.
![Strukturera data på lämpligt sätt i dina Excel-datamodeller]()
En platt datafil.
Observera att varje datafält har en kolumn och varje kolumn motsvarar ett dataelement. Dessutom finns det inget extra mellanrum, och varje rad (eller post) motsvarar en unik uppsättning information. Men nyckelattributet som gör detta till en platt fil är att inget enskilt fält identifierar en post unikt. Faktum är att du måste ange fyra separata fält (Region, Market, Business Segment och en månads försäljningsbelopp) innan du kan identifiera posten unikt.
Platta filer lämpar sig väl för datamodellering i Excel eftersom de kan vara tillräckligt detaljerade för att innehålla den data du behöver och ändå bidra till ett brett utbud av analyser med enkla formler - SUMMA, AVERAGE, VLOOKUP och SUMIF, bara för att nämna några .
Tabelluppsättningar är perfekta för pivottabelldrivna datamodeller
Många effektiva datamodeller drivs främst av pivottabeller. Pivottabeller är Excels främsta analysverktyg. För dig som har använt pivottabeller vet du att de erbjuder ett utmärkt sätt att sammanfatta och forma data för användning av rapporteringskomponenter, såsom diagram och tabeller.
Tabelluppsättningar är idealiska för pivottabelldrivna datamodeller. Följande figur illustrerar en datauppsättning i tabellform. Observera att den primära skillnaden mellan en tabelluppsättning och en platt datafil är att kolumnetiketterna i tabelluppsättningar inte dubblerar som faktiska data. Till exempel innehåller kolumnen Försäljningsperiod månadsidentifieraren. Denna subtila skillnad i struktur är det som gör tabelluppsättningar till optimala datakällor för pivottabeller. Denna struktur säkerställer att viktiga pivottabellfunktioner, såsom sortering och gruppering, fungerar som de ska.
![Strukturera data på lämpligt sätt i dina Excel-datamodeller]()
En tabelluppsättning.
Attributen för en tabelluppsättning är följande:
-
Den första raden i datasetet innehåller fältetiketter som beskriver informationen i varje kolumn.
-
Kolumnetiketterna drar inte dubbla uppgifter som dataobjekt som kan användas som filter eller frågekriterier (som månader, datum, år, regioner eller marknader).
-
Det finns inga tomma rader eller kolumner – varje kolumn har en rubrik och ett värde finns i varje rad.
-
Varje kolumn representerar en unik kategori av data.
-
Varje rad representerar enskilda objekt i varje kolumn.