Du behöver inte vara expert på databasmodellerare för att använda Power Pivot. Men det är viktigt att förstå relationer. Ju bättre du förstår hur data lagras och hanteras i databaser, desto mer effektivt kommer du att utnyttja Power Pivot för rapportering.
En relation är den mekanism genom vilken separata tabeller är relaterade till varandra. Du kan tänka på en relation som en VLOOKUP, där du relaterar data i ett dataintervall till data i ett annat dataområde med hjälp av ett index eller en unik identifierare. I databaser gör relationer samma sak, men utan krånglet med att skriva formler.
Relationer är viktiga eftersom de flesta data du arbetar med passar in i en sorts flerdimensionell hierarki. Du kan till exempel ha en tabell som visar kunder som köper produkter. Dessa kunder kräver fakturor som har fakturanummer. Dessa fakturor har flera transaktionsrader som visar vad de köpte. Det finns en hierarki där.
Nu, i den endimensionella kalkylarksvärlden, skulle dessa data vanligtvis lagras i en platt tabell, som den som visas här.
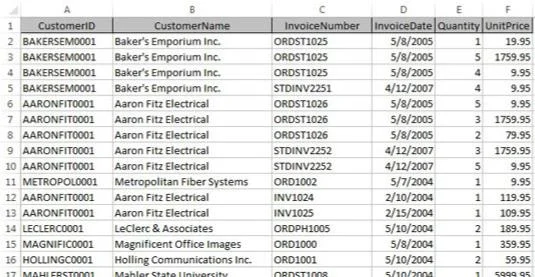
Data lagras i ett Excel-kalkylblad med ett platt-tabellformat.
Eftersom kunder har mer än en faktura måste kundinformationen (i det här exemplet CustomerID och CustomerName) upprepas. Detta orsakar problem när den informationen behöver uppdateras.
Tänk dig till exempel att namnet på företaget Aaron Fitz Electrical ändras till Fitz and Sons Electrical. När du tittar på tabellen ser du att flera rader innehåller det gamla namnet. Du måste se till att varje rad som innehåller det gamla företagsnamnet uppdateras för att återspegla ändringen. Alla rader du missar kommer inte korrekt att mappas tillbaka till rätt kund.
Skulle det inte vara mer logiskt och effektivt att registrera kundens namn och information endast en gång? Då, istället för att behöva skriva samma kundinformation upprepade gånger, kan du helt enkelt ha någon form av kundreferensnummer.
Detta är tanken bakom relationer. Du kan separera kunder från fakturor, placera var och en i sina egna tabeller. Sedan kan du använda en unik identifierare (som CustomerID) för att relatera dem.
Följande figur illustrerar hur dessa data skulle se ut i en relationsdatabas. Data skulle delas upp i tre separata tabeller: Kunder, InvoiceHeader och InvoiceDetails. Varje tabell skulle sedan relateras med hjälp av unika identifierare (CustomerID och InvoiceNumber, i det här fallet).
![Relationer och Power Pivot]()
Databaser använder relationer för att lagra data i unika tabeller och helt enkelt relatera dessa tabeller till varandra.
Tabellen Kunder skulle innehålla en unik post för varje kund. På så sätt, om du behöver ändra en kunds namn, behöver du bara göra ändringen i den posten. Naturligtvis, i verkligheten, skulle tabellen Kunder innehålla andra attribut, såsom kundadress, kundtelefonnummer och kundens startdatum. Alla dessa andra attribut kan också enkelt lagras och hanteras i tabellen Kunder.
Den vanligaste relationstypen är en en-till-många- relation. Det vill säga, för varje post i en tabell kan en post matchas med många poster i en separat tabell. Till exempel är en fakturahuvudtabell relaterad till en fakturadetaljtabell. Fakturahuvudtabellen har en unik identifierare: Fakturanummer. Fakturadetaljen kommer att använda fakturanumret för varje post som representerar en detalj av den specifika fakturan.
En annan typ av relationstyp är en-till-en- relationen: För varje post i en tabell finns en och endast en matchande post i en annan tabell. Data från olika tabeller i en en-till-en relation kan tekniskt sett kombineras till en enda tabell.
Slutligen, i en många-till-många- relation, kan poster i båda tabellerna ha valfritt antal matchande poster i den andra tabellen. En databas på en bank kan till exempel ha en tabell över de olika typerna av lån (bostadslån, billån och så vidare) och en tabell över kunder. En kund kan ha många typer av lån. Samtidigt kan varje typ av lån beviljas till många kunder.










