När du publicerar Power Pivot-rapporter på webben har du för avsikt att ge din publik den bästa möjliga upplevelsen. En stor del av den erfarenheten är att säkerställa att prestandan är bra. Ordet prestanda (som det relaterar till applikationer och rapportering) är vanligtvis synonymt med hastighet - eller hur snabbt en applikation utför vissa åtgärder som att öppna i webbläsaren, köra frågor eller filtrera.
1Begränsa antalet rader och kolumner i dina datamodelltabeller.
En stor inverkan på Power Pivot-prestanda är antalet kolumner du tar med eller importerar till datamodellen. Varje kolumn du importerar är ytterligare en dimension som Power Pivot måste bearbeta när en arbetsbok laddas. Importera inte extra kolumner "för säkerhets skull" - om du inte är säker på att du kommer att använda vissa kolumner, ta bara inte in dem. Dessa kolumner är lätta nog att lägga till senare om du upptäcker att du behöver dem.
Fler rader innebär mer data att ladda, mer data att filtrera och mer data att beräkna. Undvik att välja ett helt bord om du inte måste. Använd en fråga eller en vy i källdatabasen för att filtrera efter endast de rader du behöver importera. När allt kommer omkring, varför importera 400 000 rader med data när du kan använda en enkel WHERE-sats och bara importera 100 000?
2Använd vyer istället för tabeller.
På tal om åsikter, använd åsikter när det är möjligt för bästa praxis.
Även om tabeller är mer transparenta än vyer – så att du kan se all rå, ofiltrerad data – kommer de med alla tillgängliga kolumner och rader, oavsett om du behöver dem eller inte. För att hålla din Power Pivot-datamodell i en hanterbar storlek, tvingas du ofta ta det extra steget att explicit filtrera bort de kolumner du inte behöver.
Views kan inte bara ge renare, mer användarvänliga data utan också hjälpa till att effektivisera din Power Pivot-datamodell genom att begränsa mängden data du importerar.
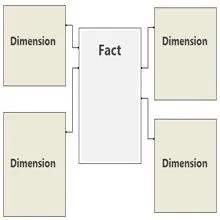
3Undvik relationer på flera nivåer.
Både antalet relationer och antalet relationslager påverkar prestandan för dina Power Pivot-rapporter. När du bygger din modell, följ bästa praxis och ha en enda faktatabell som i första hand innehåller kvantitativa numeriska data (fakta) och dimensionstabeller som direkt relaterar till fakta. I databasvärlden är denna konfiguration ett stjärnschema, som visas.
Undvik att bygga modeller där dimensionstabeller relaterar till andra dimensionstabeller.
4Låt back-end-databasservrarna göra kritan.
De flesta Excel-analytiker som är nya i Power Pivot tenderar att hämta rådata direkt från tabellerna på sina externa databasservrar. Efter att rådata finns i Power Pivot bygger de beräknade kolumner och mått för att transformera och aggregera data efter behov. Användare hämtar till exempel intäkts- och kostnadsdata och skapar sedan en beräknad kolumn i Power Pivot för att beräkna vinsten.
Så varför få Power Pivot att göra den här beräkningen när back-end-servern kunde ha hanterat det? Verkligheten är att backend-databassystem som SQL Server har förmågan att forma, aggregera, rengöra och transformera data mycket mer effektivt än Power Pivot. Varför inte använda deras kraftfulla kapacitet för att massera och forma data innan du importerar den till Power Pivot?
Istället för att hämta obearbetad tabelldata, överväg att utnyttja frågor, vyer och lagrade procedurer för att utföra så mycket av dataaggregering och kritarbete som möjligt. Denna hävstångseffekt minskar mängden bearbetning som Power Pivot kommer att behöva göra och förbättrar naturligtvis prestandan.
5 Akta dig för kolumner med icke-särskilda värden.
Kolumner som har ett stort antal unika värden är särskilt svåra för Power Pivot-prestanda. Kolumner som Transaktions-ID, Order-ID och Fakturanummer är ofta onödiga i Power Pivot-rapporter och instrumentpaneler på hög nivå. Så om de inte behövs för att upprätta relationer till andra tabeller, lämna dem utanför din modell.
![10 sätt att förbättra Power Pivot-prestanda]()
6Begränsa antalet skärare i en rapport.
Slicern är en av de bästa nya affärsintelligens (BI) funktionerna i Excel de senaste åren. Med hjälp av slicers kan du ge din publik ett intuitivt gränssnitt som möjliggör interaktiv filtrering av dina Excel-rapporter och instrumentpaneler.
En av de mer användbara fördelarna med slicern är att den reagerar på andra slicers, vilket ger en kaskadfiltereffekt. Till exempel illustrerar figuren inte bara att om du klickar på Mellanvästern i regionutsnittet filtreras pivottabellen utan att Marknadsutsnittet också reagerar genom att markera de marknader som tillhör Midwestregionen. Microsoft kallar detta beteende för korsfiltrering.
Lika användbar som skivaren är, är den tyvärr extremt dålig för Power Pivot-prestandan. Varje gång en slicer ändras måste Power Pivot räkna om alla värden och mått i pivottabellen. För att göra det måste Power Pivot utvärdera varje bricka i den valda slicern och bearbeta lämpliga beräkningar baserat på urvalet.
7Skapa skivare endast på dimensionsfält.
Slicers kopplade till kolumner som innehåller många unika värden kommer ofta att orsaka en större prestandaträff än kolumner som bara innehåller en handfull värden. Om en skivare innehåller ett stort antal brickor, överväg att använda en rullgardinsmeny för Pivot Table Filter istället.
På liknande sätt, se till att ha rätt storlek på kolumndatatyper. En kolumn med få distinkta värden är ljusare än en kolumn med ett stort antal distinkta värden. Om du lagrar resultaten av en beräkning från en källdatabas, minska antalet siffror (efter decimalen) som ska importeras. Detta minskar storleken på ordboken och, möjligen, antalet distinkta värden.
![10 sätt att förbättra Power Pivot-prestanda]()
8 Inaktivera korsfilterbeteendet för vissa skivare.
Genom att inaktivera korsfilterbeteendet för en skivare förhindras i huvudsak den skivaren från att ändra val när andra skärare klickas. Detta förhindrar att Power Pivot behöver utvärdera titlarna i den inaktiverade slicern, vilket minskar bearbetningscyklerna. Om du vill inaktivera korsfilterbeteendet för en skivare väljer du Slicer Settings för att öppna dialogrutan Slicer Settings. Avmarkera sedan helt enkelt alternativet Visuellt indikera objekt utan data.
9Använd beräknade mått istället för beräknade kolumner.
Använd om möjligt beräknade mått istället för beräknade kolumner. Beräknade kolumner lagras som importerade kolumner. Eftersom beräknade kolumner i sig interagerar med andra kolumner i modellen, beräknar de varje gång pivottabellen uppdateras, oavsett om de används eller inte. Beräknade mått, å andra sidan, beräknar endast vid frågetid.
Beräknade kolumner liknar vanliga kolumner genom att de båda tar plats i modellen. Däremot beräknas beräknade mått i farten och tar inte plats.
10Uppgradera till 64-bitars Excel.
Om du fortsätter att stöta på prestandaproblem med dina Power Pivot-rapporter kan du alltid köpa en bättre dator – i det här fallet genom att uppgradera till en 64-bitars PC med 64-bitars Excel installerat.
Power Pivot laddar hela datamodellen i RAM-minnet när du arbetar med den. Ju mer RAM din dator har, desto färre prestandaproblem ser du. 64-bitarsversionen av Excel kan komma åt mer av din dators RAM-minne, vilket säkerställer att den har de systemresurser som behövs för att gå igenom större datamodeller. Faktum är att Microsoft rekommenderar 64-bitars Excel för alla som arbetar med modeller som består av miljontals rader.
Men innan du snabbt börjar installera 64-bitars Excel måste du svara på dessa frågor:
Har du redan 64-bitars Excel installerat?
Är dina datamodeller tillräckligt stora?
Har du ett 64-bitars operativsystem installerat på din PC?
Kommer dina andra tillägg att sluta fungera?











