IBM SPSS Statistics kommer i form av ett bassystem, men du kan skaffa ytterligare moduler att lägga till i det systemet. SPSS finns i olika licensutgåvor : campusutgåvorna, prenumerationsplaner och kommersiella utgåvor. Även om prissättningen och olika paket skiljer sig åt för var och en, gör de alla att du kan inkludera samma tilläggsmoduler.
Om du använder en kopia av SPSS på jobbet eller i en universitetsmiljö som någon annan har installerat, kanske du har några av dessa tillägg utan att inse det eftersom de flesta är så fullständigt integrerade i menyerna att de ser ut som integrerade delar av bassystem. Om du märker att dina menyer är kortare eller längre än någon annans kopia av SPSS, beror det förmodligen på tilläggsmoduler.
Vissa tillägg kanske inte är av intresse för dig; medan andra kan bli oumbärliga. Observera att om du har en provexemplar av SPSS, har den troligen alla moduler, inklusive de som du kan förlora åtkomst till när du skaffar ditt eget exemplar. Den här artikeln introducerar dig till modulerna som kan läggas till SPSS och vad de gör; Se dokumentationen som medföljer varje modul för en fullständig handledning.
Du kommer troligen att stöta på namnen IBM SPSS Amos och IBM SPSS Modeler . Även om SPSS förekommer i namnen köper du dessa program separat, inte som tillägg. Amos används för Structural Equation Modeling (SEM) och SPSS Modeler är en arbetsbänk för prediktiv analys och maskininlärning.
Modulen Avancerad statistik
Följande är en lista över de statistiska tekniker som ingår i modulen Advanced Statistics:
- Allmänna linjära modeller (GLM)
- Generaliserade linjära modeller (GENLIN)
- Linjära blandade modeller
- Procedurer för generaliserade skattningsekvationer (GEE).
- Generaliserade linjära blandade modeller (GLMM)
- Procedurer för överlevnadsanalys
Även om dessa procedurer är bland de mest avancerade inom SPSS, är vissa ganska populära. Till exempel är hierarkisk linjär modellering (HLM), en del av linjära blandade modeller, vanligt inom utbildningsforskning. HLM-modeller är statistiska modeller där parametrar varierar på mer än en nivå. Till exempel kan du ha data som innehåller information för både elever och skolor, och i en HLM-modell kan du samtidigt införliva information från båda nivåerna.
Nyckelpunkten är att denna avancerade statistiska modul innehåller specialiserade tekniker som du behöver använda om du inte uppfyller antagandena om vanlig vanilj-regression och variansanalys (ANOVA). Dessa tekniker är mer av en ANOVA-smak. Överlevnadsanalys är så kallad time-to-event-modellering, som att uppskatta tid till dödsfall efter diagnos.
Modulen Anpassade tabeller
Modulen Custom Tables har varit den mest populära modulen i flera år, och det av goda skäl. Om du behöver klämma in mycket information i en rapport behöver du den här modulen. Om du till exempel gör enkätundersökningar och vill rapportera om hela undersökningen i tabellform, kan modulen Anpassade tabeller komma till din räddning eftersom den låter dig enkelt presentera omfattande information.
Få en gratis provversion av SPSS Statistics med alla moduler, och tvinga dig själv att spendera en solid dag med de moduler du inte har. Se om någon aspekt av rapporteringen du redan gör kan göras snabbare med modulen Anpassade tabeller. Återskapa en ny rapport och se hur mycket tid du kan spara.
I följande figur ser du en enkel frekvenstabell som visar två variabler. Observera att kategorierna för båda variablerna är desamma.
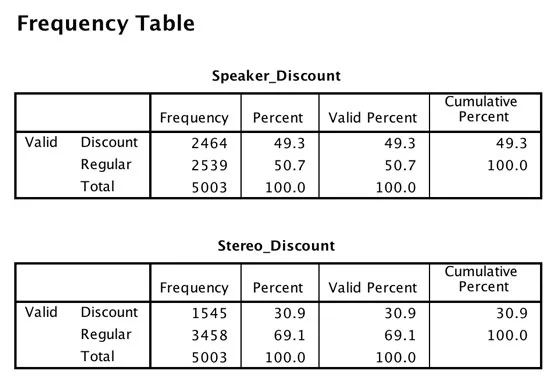
Frekvenstabell över rabattvariablerna.
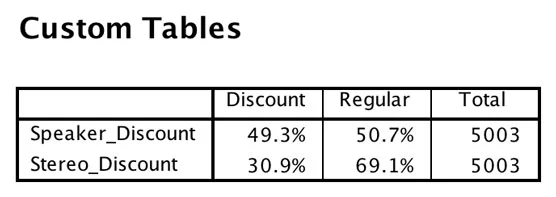
Följande tabell är samma data, men här skapades tabellen med SPSS Custom Tables-modulen och är en mycket bättre tabell.
![Moduler du kan lägga till i SPSS]()
Anpassad tabell över rabattvariablerna.
Om du producerar bordet för dig själv kanske presentationen inte spelar någon roll. Men om du lägger tabellen i en rapport som kommer att skickas till andra behöver du modulen SPSS Custom Tables. Förresten, med övning tar det bara några sekunder att göra den anpassade versionen, och du kan använda Syntax för att ytterligare anpassa tabellen!
Från och med version 27 är modulen Custom Tables en del av standardutgåvan.
Regressionsmodulen
Följande är en lista över de statistiska tekniker som ingår i regressionsmodulen:
- Multinomial och binär logistisk regression
- Icke-linjär regression (NLR) och begränsad olinjär regression (CNLR)
- Viktad minsta kvadratregression och tvåstegs minsta kvadratregression
- Probitanalys
På vissa sätt är regressionsmodulen som modulen Advanced Statistics - du använder dessa tekniker när du inte uppfyller standardantagandena. Men med regressionsmodulen är teknikerna snygga varianter av regression när du inte kan göra vanlig minsta kvadratregression. Binär logistisk regression är populär och används när den beroende variabeln har två kategorier - till exempel stanna eller gå (churn), köpa eller inte köpa, eller få en sjukdom eller inte få en sjukdom.
Modulen Kategorier
Modulen Kategorier låter dig avslöja relationer mellan dina kategoriska data. För att hjälpa dig förstå dina data använder modulen Kategorier perceptuell mappning, optimal skalning, preferensskalning och dimensionsreduktion. Med hjälp av dessa tekniker kan du visuellt tolka relationerna mellan dina rader och kolumner.
Modulen Kategorier utför sin analys av ordinaldata och nominella data. Den använder procedurer som liknar konventionell regression, huvudkomponenter och kanonisk korrelation. Den utför regression med hjälp av nominella eller ordinala kategoriska prediktorer eller utfallsvariabler.
Procedurerna för modulen Kategorier gör det möjligt att utföra statistiska operationer på kategoriska data:
- Med hjälp av skalningsprocedurerna kan du tilldela måttenheter och nollpunkter till dina kategoriska data, vilket ger dig tillgång till nya grupper av statistiska funktioner eftersom du kan analysera variabler med hjälp av blandade mätnivåer.
- Med hjälp av korrespondensanalys kan du numeriskt utvärdera likheter mellan nominella variabler och sammanfatta dina data enligt komponenter du väljer.
- Med hjälp av ickelinjär kanonisk korrelationsanalys kan du samla in variabler av olika mätnivåer till egna uppsättningar och sedan analysera uppsättningarna.
Du kan använda den här modulen för att skapa ett par användbara verktyg:
- Perceptuell karta: Ett högupplöst sammanfattningsdiagram som fungerar som en grafisk visning av liknande variabler eller kategorier. En perceptuell karta ger dig insikter i samband mellan mer än två kategoriska variabler.
- Biplot: Ett sammanfattande diagram som gör det möjligt att titta på relationerna mellan produkter, kunder och demografiska egenskaper.
Dataförberedelsemodulen
Låt oss inse det: Dataförberedelser är inte kul. Vi tar all hjälp vi kan få. Ingen modul kommer att eliminera allt arbete för människan i detta partnerskap mellan människa och dator, men modulen Dataförberedelse kommer att eliminera vissa rutinmässiga, förutsägbara aspekter.
Den här modulen hjälper dig att bearbeta rader och kolumner med data. För rader med data hjälper det dig att identifiera extremvärden som kan förvränga din data. När det gäller variabler hjälper det dig att identifiera de bästa och låter dig veta att du kan förbättra några genom att omvandla dem. Det gör det också möjligt för dig att skapa speciella valideringsregler för att påskynda dina datakontroller och undvika mycket manuellt arbete. Slutligen hjälper det dig att identifiera mönster i dina saknade data.
Från och med version 27 är modulerna Data Preparation och Bootstrapping en del av basutgåvan.
Modulen Beslutsträd
Beslutsträd är överlägset den mest populära och välkända datautvinningstekniken. Faktum är att hela mjukvaruprodukter är dedikerade till detta tillvägagångssätt. Om du inte är säker på om du behöver göra datautvinning men du vill prova det, skulle användningen av modulen Decision Trees vara ett av de bästa sätten att försöka datautvinning eftersom du redan känner till SPSS Statistics. Modulen Decision Trees har inte alla funktioner i beslutsträden i SPSS Modeler (ett helt mjukvarupaket dedikerat till datautvinning), men det finns mycket här för att ge dig en bra start.
Vad är beslutsträd? Tja, tanken är att du har något du vill förutsäga (målvariabeln) och massor av variabler som möjligen kan hjälpa dig att göra det, men du vet inte vilka som är viktigast. SPSS indikerar vilka variabler som är viktigast och hur variablerna interagerar, och hjälper dig att förutsäga målvariabeln i framtiden.
SPSS stöder fyra av de mest populära beslutsträdsalgoritmerna: CHAID, Exhaustive CHAID, C&RT och QUEST.
Prognosmodulen
Du kan använda Prognosmodulen för att snabbt konstruera experttidsserieprognoser. Denna modul innehåller statistiska algoritmer för att analysera historiska data och förutsäga trender. Du kan ställa in den för att analysera hundratals olika tidsserier samtidigt istället för att köra en separat procedur för var och en.
Mjukvaran är designad för att hantera de speciella situationer som uppstår vid trendanalys. Den bestämmer automatiskt den bäst passande autoregressiva integrerade glidande medelvärdet (ARIMA) eller exponentiell utjämningsmodell. Den testar automatiskt data för säsongsvariationer, intermittenser och saknade värden. Programvaran upptäcker extremvärden och förhindrar dem från att onödigtvis påverka resultaten. De genererade graferna inkluderar konfidensintervall och indikerar modellens goda passform.
När du får erfarenhet av prognostisering ger Prognosmodulen dig mer kontroll över varje parameter när du bygger din datamodell. Du kan använda expertmodelleraren i modulen Prognos för att rekommendera startpunkter eller för att kontrollera beräkningar du har gjort för hand.
Dessutom försöker en algoritm som kallas Temporal Causal Modeling (TCM) upptäcka viktiga orsakssamband i tidsseriedata genom att endast inkludera indata som har ett orsakssamband med målet. Detta skiljer sig från traditionell tidsseriemodellering, där du uttryckligen måste specificera prediktorerna för en målserie.
Modulen Missing Values
Dataprepareringsmodulen verkar ha saknade värden täckta, men Missing Values-modulen och Dataprepareringsmodulen är helt olika. Dataförberedelsemodulen handlar om att hitta datafel; dess valideringsregler kommer att tala om för dig om en datapunkt helt enkelt inte är rätt. Modulen Missing Values, å andra sidan, fokuserar på när det inte finns något datavärde. Den försöker uppskatta den saknade informationen med hjälp av annan data du har. Denna process kallas imputation, eller att ersätta värden med en välgrundad gissning. Alla typer av dataminerare, statistiker och forskare – särskilt undersökningsforskare – kan dra nytta av modulen Missing Values.
Bootstrapping-modulen
Håll ut, för vi kommer bli lite tekniska. Bootstrapping är en teknik som innebär omsampling med ersättning. Bootstrapping-modulen väljer ett fall slumpmässigt, gör anteckningar om det, ersätter det och väljer ett annat. På så sätt är det möjligt att välja ett ärende mer än en gång eller inte alls. Nettoresultatet är en annan version av din data som är liknande men inte identisk. Om du gör detta 1 000 gånger (standardinställningen) kan du verkligen göra några kraftfulla saker.
Bootstrapping-modulen låter dig bygga mer stabila modeller genom att övervinna effekten av extremvärden och andra problem i din data. Traditionell statistik förutsätter att din data har en viss fördelning, men den här tekniken undviker det antagandet. Resultatet är en mer exakt uppfattning om vad som händer i befolkningen. Bootstrapping, på sätt och vis, är en enkel idé, men eftersom bootstrapping tar mycket datorhästkrafter är det mer populärt nu än när datorerna var långsammare.
Bootstrapping är en populär teknik även utanför SPSS, så du kan hitta artiklar på webben om konceptet. Bootstrapping-modulen låter dig tillämpa detta kraftfulla koncept på dina data i SPSS Statistics.
Modulen Complex Samples
Urval är en stor del av statistiken. Ett enkelt slumpmässigt urval är vad vi vanligtvis tänker på som ett urval - som att välja namn ur en hatt. Hatten är din befolkning, och papperslapparna du väljer tillhör ditt prov. Varje papperslapp har lika stor chans att bli utvald. Forskning är ofta mer komplicerad än så. Modulen Complex Sample handlar om mer komplicerade former av sampling: tvåstegs, stratifierad och så vidare.
Oftast behöver undersökningsforskare denna modul, även om många typer av experimentella forskare också kan ha nytta av den. Modulerna Complex Samples hjälper dig att utforma datainsamlingen och tar sedan hänsyn till designen när du beräknar din statistik. Nästan all statistik i SPSS är beräknad med antagandet att uppgifterna är ett enkelt slumpmässigt urval. Dina beräkningar kan förvrängas när detta antagande inte uppfylls.
Conjoint-modulen
Conjoint-modulen ger dig ett sätt att avgöra hur var och en av din produkts attribut påverkar konsumenternas preferenser. När du kombinerar samanalys med konkurrenskraftig marknadsproduktundersökning är det lättare att ta reda på produktegenskaper som är viktiga för dina kunder.
Med den här forskningen kan du avgöra vilka produktattribut dina kunder bryr sig om, vilka de bryr sig mest om och hur du kan göra användbara studier av prissättning och varumärkeskapital. Och du kan göra allt detta innan du ådrar dig kostnaden för att lansera nya produkter på marknaden.
Direktmarknadsföringsmodulen
Direktmarknadsföringsmodulen skiljer sig lite från de andra. Det är en bunt relaterade funktioner i en trollkarlsmiljö. Modulen är utformad för att vara one-stop shopping för marknadsförare. Huvudfunktionerna är analys av aktualitet, frekvens och monetär (RFM), klusteranalys och profilering:
- RFM-analys: RFM-analys rapporterar tillbaka till dig om hur nyligen, hur ofta och hur mycket dina kunder spenderade på ditt företag. Uppenbarligen är kunder som för närvarande är aktiva, spenderar mycket och spenderar ofta dina bästa kunder.
- Klusteranalys: Klusteranalys är ett sätt att segmentera dina kunder i olika kundsegment. Vanligtvis använder du denna metod för att matcha olika marknadsföringskampanjer till olika kunder. Till exempel kan ett kryssningsrederi prova olika omslag på resekatalogen som går ut till kunder, med de äventyrliga typerna som får Alaska eller Norge på omslaget, och paraplydrinkarna får bilder av Karibien.
- Profilering: Profilering hjälper dig att se vilka kundegenskaper som är förknippade med specifika resultat. På så sätt kan du beräkna benägenheten som en viss kund kommer att svara på en specifik kampanj. Praktiskt taget alla dessa funktioner kan hittas i andra områden av SPSS, men den trollformiga miljön i modulen Direct Marketing gör det enkelt för marknadsanalytiker att kunna producera användbara resultat när de inte har omfattande utbildning i statistiken bakom teknikerna.
Modulen Exakta tester
Modulen Exakta tester gör det möjligt att vara mer exakt i din analys av små datamängder och dataset som innehåller sällsynta förekomster. Det ger dig de verktyg du behöver för att analysera sådana dataförhållanden med större noggrannhet än vad som annars skulle vara möjligt.
När endast ett litet urval är tillgängligt kan du använda modulen Exakta tester för att analysera det mindre urvalet och ha mer förtroende för resultaten. Här är tanken att göra fler analyser på kortare tid. Den här modulen låter dig genomföra olika undersökningar istället för att lägga tid på att samla in prover för att utöka din bas av undersökningar.
Processerna du använder, och formerna för resultaten, är desamma som i SPSS-bassystemet, men de interna algoritmerna är inställda för att fungera med mindre datamängder. Exakta testmodulen tillhandahåller mer än 30 tester som täcker alla icke-parametriska och kategoriska tester som du normalt använder för större datamängder. Inkluderade är ett-prov, två-prov och k-prov med oberoende eller relaterade prover, goodness-of-fit-tester, test av oberoende och mått på association.
Modulen Neural Networks
Ett neuralt nät är ett gitterliknande nätverk av neuronliknande noder, inrättat inom SPSS för att fungera ungefär som neuronerna i en levande hjärna. Kopplingarna mellan dessa noder har tillhörande vikter (grader av relativ effekt), som är justerbara. När du justerar vikten på en anslutning sägs nätverket lära sig.
I modulen Neural Network justerar en träningsalgoritm iterativt vikterna för att nära överensstämma med de faktiska relationerna mellan data. Tanken är att minimera fel och maximera exakta förutsägelser. Det beräkningsneurala nätverket har ett lager av neuroner för ingångar och ett annat för utgångar, med ett eller flera dolda lager mellan dem. Det neurala nätverket kan användas med andra statistiska procedurer för att ge tydligare insikt.
Genom att använda det välbekanta SPSS-gränssnittet kan du bryta dina data för relationer. Efter att ha valt en procedur anger du de beroende variablerna, som kan vara valfri kombination av kontinuerliga och kategoriska typer. För att förbereda för bearbetning lägger du upp den neurala nätverksarkitekturen, inklusive de beräkningsresurser du vill använda. För att slutföra förberedelserna väljer du vad du ska göra med utdata:
- Lista resultaten i tabeller.
- Visa resultaten grafiskt i diagram.
- Placera resultaten i temporära variabler i datamängden.
- Exportera modeller i XML-formaterade filer.

")
 Google Meet-mikrofonen fungerar inte, Avstängd på grund av samtalets storlek")
")


-chip på Windows 10")


