Våra 10 gotchas fungerar som en checklista över potentiella orsaker till dina SPSS Statistics- problem. Vissa slösar bara bort din tid, men andra kan både slösa bort din tid och förstöra din analys. Den här listan förstärker vikten av att undvika dessa vanliga problem så att du effektivt kan använda SPSS.
Några av dessa 10 gotchas kan vara förvirrande till en början. Andra är enkla, men nya användare kanske inte tillskriver dem den vikt de förtjänar. Vad de alla har gemensamt är att okunnighet om dem kan få dig i varmt vatten. Närhelst något verkar vara fel i SPSS, dubbelkolla den här listan. För att komma in på den här listan måste dessa gotchas ha genererat hundratals verkliga problem som vi bevittnat i vår kundinteraktion.
Misslyckas med att deklarera mätnivå
För många nya användare av SPSS verkar det som en olägenhet att deklarera måttenhetsnivå. Du kan lugnt ignorera det ett tag, men vårt råd är att inte vänta tills den dagen det börjar orsaka problem. Här är bara några anmärkningsvärda situationer där du kommer att ångra ett beslut att skjuta upp att få dina datauppsättningar korrekt inställda:
- En variabel som du behöver kanske inte visas i en dialogruta.
- Funktioner som förlitar sig på metadata, som Codebook, kommer att ge dåliga resultat.
- Diagramdialogerna kommer inte att erbjuda dig de alternativ du behöver för en viss variabel.
- Tilläggsmodulen Custom Tables kommer att bete sig konstigt.
Rätt metadata är ett måste för en effektiv användning av SPSS. De som försöker spara tid genom att hoppa över steget att ställa in sina datauppsättningar på rätt sätt kommer aldrig att lyckas eftersom de i det långa loppet kommer att slösa tid på att försöka ta reda på varför SPSS inte beter sig som det ska.
Sammanställning av strängvärden med etiketter
Undvik att använda strängvariabeltypen. Använd istället en kombination av värden och värdeetiketter. På 60- och 70-talet var RAM- och hårddiskutrymme dyrt och begränsat. Strängar använder många fler tecken och byte än siffror, och då kunde SPSS inte utföra beräkningar med enbart RAM-minne, så det behövde använda hårddisken eftersom vi kan använda en skraplotter. Nu kan det tyckas konstigt att oroa sig för sådana saker, men att undvika strängar är fortfarande kärnan i SPSS designfilosofi.
Så vilka typer av variabler ska lagras som strängar? Adresser, öppna kommentarer i enkätdata och namn på personer och företag är bra exempel på strängvariabler. Det finns inte många fler. Namnen på de 50 staterna, namnen på produkter, produktkategorier och SKU:er och de flesta andra nominella variabler bör ställas in som par av värden och värdeetiketter.
Tidigare utgjorde inledande nollor i data som postnummer ett problem, så data skulle deklareras som strängar. Nu lägger dock den begränsade numeriska variabeltypen till inledande nollor utfyllda till variabelns maximala bredd, så en postnummervariabel behöver inte längre deklareras som en sträng. Autorecode gör också konverteringar från sträng till numerisk enkel. Håll strängvariabler till ett minimum.
Excel-filer tillåter inte metadata, så Excel stöder inte värde- och värdeetikettpar. När du ofta importerar strängdata från Excel bör du överväga att lära dig syntaxkommandon samt autorecode-transformation eftersom dessa tekniker kan vara till hjälp.
Misslyckas med att deklarera saknad data
För flera år sedan upplevde en SPSS-användare i en av våra klasser följande situation. Han hade en skala från 1 till 10, med 10 som högsta nöjdhetsbetyg och 1 som lägst nöjdhetsbetyg. Han behövde en kod för att representera "vägrade att svara" och valde 11. När han fick reda på att data saknades i klassen undrade han om det skulle vara okej att bara lämna 11:orna i datan eftersom han redan hade slutfört analysen och antalet avslag var ganska låg.
Du slår vad om att det orsakade ett stort problem! Det skulle kunna flytta den genomsnittliga nöjdheten ganska långt mot 11 även med ett bortfall på 1 till 2 procent. Det som var slående med det här exemplet var att det vanligaste svaret, 1, låg väldigt långt ifrån det kodade värdet för bortfall. Det faktum borde ha gjort analysen uppenbart felaktig och lätt att upptäcka. Vad värre är, det är väl förstått i enkätforskningen att avslag ofta speglar respondenter som är mycket missnöjda men ovilliga att dela sin åsikt. Valet av 11 fick deras åsikter att se mycket nöjda ut, inte särskilt missnöjda, vilket förvrängde resultaten ännu mer.
Tyvärr glömmer folk att deklarera saknade ganska ofta, och felet kvarstår ofta genom de sista stegen i analysen och upptäcks aldrig. I exemplet kunde problemet ha åtgärdats med ett enkelt steg: Ange 11 som användardefinierad saknad. Var uppmärksam på att deklarera saknade datavärden i din metadata.
Det gick inte att hitta tilläggsmoduler och plugin-program
Vad kan gå fel med tilläggsmoduler? Problemet som vi ofta ser hos kunder är att de läser om funktioner i tilläggsmoduler och sedan inte kan hitta modulerna. Det här kan tyckas konstigt. Skulle inte alla veta vilka SPSS-funktioner de äger? Men du kan också bli förvirrad av flera anledningar:
- Någon annan har betalat för ditt exemplar av SPSS, ofta en kopia som du kommer åt i skolan eller på jobbet
- Papperet för ditt exemplar av SPSS säger Standard eller Premium, men det är inte klart vad detta betyder.
- Du försöker hitta modulen i menyerna, med hänvisning till en bild i en bok eller blogginlägg, och din skärm ser inte ut som bilden.
- Du lånar lite fungerande SPSS-syntax av en kollega eller bok, men det fungerar inte på ditt exemplar av SPSS.
SPSS implementerar tilläggsmoduler genom att lägga till dem i dina menyer, vanligtvis i huvudmenyn Analysera. I följande figur kan du se Analysera-menyn från skärmen för en testversion av SPSS-prenumeration. Provversionen har alltid alla moduler. Så, om din meny är kortare än den du ser på bilden, vet du att du inte har hela uppsättningen av tilläggsmoduler.
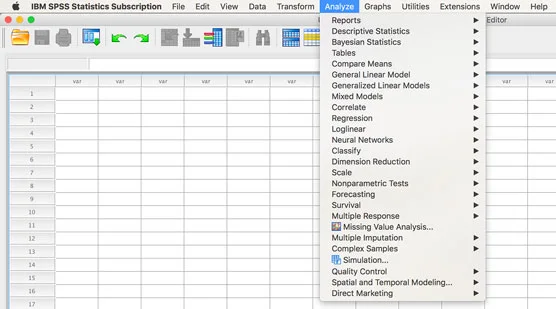
Analysera-menyn med alla tillgängliga moduler.
Inget är fel med din kopia av SPSS. Du har helt enkelt inte tillgång till alla funktioner, inklusive via SPSS Syntax. Vissa tror att om du kan den nödvändiga koden och kringgår det grafiska användargränssnittet kan du köra vilket kommando som helst, men det är inte sant. För att köra syntaxen för en tilläggsmodul måste du äga modulen. Vi betonar detta eftersom vi har sett människor låna Syntax från en källa, kollega eller bok, och försöker kopiera och klistra in koden i Syntax-fönstret. Syntaxkoden kommer inte att fungera om du saknar rätt licensiering.
En annan vanlig källa till förvirring är att många SPSS-användare inte inser att de har tillgång till tilläggsmoduler på jobbet eller i skolan. Detta är olyckligt eftersom modulerna kan vara extremt användbara. Vi rekommenderar alltid modulen Custom Tables till kunder för större effektivitet i deras analys. Otaliga gånger har kunder trott att de inte hade några moduler bara för att upptäcka att anpassade tabeller var synliga i menyerna och fungerade.
![10 SPSS Statistics Gotchas]()
Slutligen, "plugins" är lite annorlunda än tilläggsmoduler. Funktioner kan läggas till i SPSS genom att använda Python och R. Om du är en programmerare kan du överväga att göra den här uppgiften själv. Men många av dessa tillägg är redan tillgängliga. Allt du behöver göra är att ladda ner dem, så kommer de att visas som ytterligare menyalternativ, med en plussymbol bredvid menyposten (se marginalikonen). Den pensionerade SPSSer Jon Peck var avgörande för att lägga till denna programmerbarhetsfunktion till SPSS.
Misslyckas med att uppfylla statistiska antaganden och mjukvaruantaganden
SPSS är inte så smart. SPSS kommer att göra vad du än ber den att göra. Så, om du har en variabel som Civilstånd, med värdena: 1= Gift, 2=Skillnad, 3=Separerad, 4=Änka och 5=Singel, och du ber SPSS att ge dig ett medelvärde för civilstånd, SPSS kommer att ge dig ett medelvärde. Ett medelvärde på 2,33 för en nominell variabel som civilstånd är dock inte användbart. På samma sätt, om du analyserar dina uppgifter och upptäcker att 100 % av dina vänner som du undersökte tycker att mer ekonomiska resurser borde ägnas åt tenniscentret på din landsklubb, men du bara intervjuade tennisspelare, så kan du inte släppa ut dina resultat som ett slumpmässigt urval av country clubmedlemmar, och du kan inte heller bli förvånad över dina resultat.
Det är viktigt att du har tillförlitlig och giltig data. SPSS antar att din data kommer från ett slumpmässigt urval; om så inte är fallet kan du fortfarande få beskrivande information, men du kommer inte att kunna generalisera dina resultat till en population. Du måste också veta vilken information du kan hämta från dina data.
Dessutom är det viktigt att komma ihåg att varje statistiskt test har antaganden. Vissa statistiska tester i SPSS, som t-testet för oberoende sampel, bedömer automatiskt några av testantagandena, dock för det mesta; du måste köra ytterligare kontroller för att bedöma testantaganden. Kom ihåg att ju bättre du uppfyller testantaganden, desto mer kan du lita på resultatet av ett test.
Du kanske hör att ett test är känsligt för kränkningar av antaganden eller robust för kränkningar av antaganden. När ett test är känsligt måste du vara extra noga med att uppfylla antagandena. När ett test är robust finns det mer rörelseutrymme med antagandena.
Förvirrande fastesyntax med kopiera och klistra in
Så gott som alla SPSS-användare börjar med att lära sig SPSS via det grafiska användargränssnittet och många tycker att SPSS-syntaxen är lite svårbegriplig. Förvirringen uppstår när en kollega delar lite syntaxkod och erbjuder det som en genväg, men det hela kan se väldigt skrämmande ut. Rädslan är att du måste ha en stor bok öppen på ditt skrivbord och att du kommer att skriva kommandona bokstav för bokstav. Detta är helt enkelt inte sant.
Även om en välmenande kollega utbrister "Det är lätt, bara klistra in det", kanske det inte är tydligt vad de menar. "Klistra in" i SPSS, när det gäller SPSS-syntax, betyder att låta SPSS-dialogerna generera syntaxkoden åt dig genom att ge instruktionerna via peka och klicka. Syntaxen genereras sedan och skickas till syntaxfönstret. Du kan se det som att konvertera klick till kod. Det är inte kopiera, klistra in manövern (Control-C, Control-V i Windows) som vi gör i de flesta program.
Tänker att du skapar variabler i SPSS som du gör i Excel
Nästan alla som lär sig SPSS har tidigare exponering för Excel till inlärningsupplevelsen. Det finns en kritisk funktion i båda som hanteras helt olika i de två gränssnitten. När du i Excel vill implementera en formel arbetar du direkt i en cell i kalkylarket och formeln sparas på samma plats när du sparar kalkylarket. I SPSS måste du använda dialogrutan Beräkna variabel (eller motsvarande i SPSS-syntax) och din formel sparas inte i datasetet @@md bara resultatet sparas i datamängden.
Till en början kan det verka mycket önskvärt för alla att spara formler i datamängden, men det kanske inte är tydligt det höga priset som betalas för denna funktion i Excel. SPSS är byggd för att vara skalbar till stora datamängder, ibland 100-tals miljoner rader med data. I Excel måste kalkylarket ständigt skannas för att uppdatera formlervärdena. Den skanningen, passivt och automatiskt i bakgrunden, förbrukar resurser och gör Excel mindre skalbart till mycket stora datamängder. Excel blir märkbart trögt när datauppsättningar är mycket stora av denna anledning, men Excel designades aldrig för stora datauppsättningar. I SPSS förblir data konstant om inte en åtgärd uppmanar till en ändring. För att tvinga beräkningar att uppdateras måste antingen menyerna användas igen eller så måste SPSS Syntax köras igen. Varje system är designat med sin primära målgrupp i åtanke.
Om du är mer bekant med hur Excel automatiskt uppdaterar beräkningar, hur ska du vänja dig till SPSS? Om de flesta av dina data läses in från en fil och du går direkt till analys kommer du förmodligen att vara ganska nöjd med det grafiska användargränssnittet. Om du har mycket stora filer eller om du har ett stort antal beräkningar som görs efter att data har lästs in från en fil, måste du lära dig SPSS Syntax för att vara produktiv. Genom att spara dessa beräkningar, kanske dussintals eller hundratals av dem, i form av SPSS Syntax kan du köra dem alla igen ganska enkelt.
Excel har för närvarande en gräns på 1 000 000 rader med data, men för bara några år sedan var gränsen mycket mindre. Detta är sällan ett problem för Excel-användare eftersom det vanligtvis räcker med många rader. Excel-experter kan ofta hitta en väg runt denna gräns, men det är sällan nödvändigt. Den tekniska orsaken till denna begränsning är att hela kalkylbladet måste vara tillgängligt för en dators minne. SPSS kräver inte att hela datasetet får plats i datorns minne. Detta är viktigt för många SPSS-användare eftersom tusentals företag med datauppsättningar större än gränsen för miljonrader behöver analysera sina stora datauppsättningar i SPSS. IRS är ett anmärkningsvärt exempel på en organisation som använder SPSS som har datauppsättningar mycket större än gränsen för miljonrader.
Blir förvirrad av listvis radering
Saknade data har ofta behandlats som ett kapitellångt (eller till och med boklångt) ämne, men en diskussion om den längden är inte möjlig i den här artikeln. Du kan hantera saknad data på många sätt, varav ett är att använda listvis radering. Och att vara bekant med termen listvis radering kan göra dig uppmärksam på vad som annars skulle tyckas vara konstigt beteende i SPSS. Föreställ dig att du har en stor datamängd med tusentals rader. Men när du kör en multivariat analys beter sig SPSS som om du inte har någon data alls. Du kontrollerar stegen flera gånger, men allt du ser i resultaten är meddelanden som indikerar att du har "inga giltiga fall." Vad kan hända?
Listvis radering är en metod för att bestämma vilka fall i datamängden som används av SPSS för multivariat analys. När denna metod tillämpas används endast fall som är giltiga för alla variabler i analysen. Om bara en enda cell med information saknas i ärenderaden kommer hela ärendet att tas bort. Varför är detta vanligt? Föreställ dig att du samlar in data om flygpassagerare. En kolumn registrerar om en passagerare valde att köpa en måltid ombord, vilket endast gäller busspassagerare. En annan kolumn registrerar vilket av två måltidsval personen valde under förstaklassmåltiden, vilket endast gäller förstaklasspassagerare. Varje rad i datasetet kommer att sakna den ena eller den andra, vilket resulterar i att nollrader med data presenteras för den multivariata analysen. Denna situation är vanlig.
Denna korta diskussion är inte tillräcklig för att väga för- och nackdelar med att använda listvis radering. Men du kommer nu att vara medveten om det när du stöter på problemet med noll fall som analyseras. Håll också utkik efter tillfällen då många färre fall än du förväntade dig analyseras. I dialogrutan Alternativ i dialogrutan Linjär regression är listvis radering standard. Var noga med att inte slumpmässigt välja bland de andra valen tills regressionen fungerar. Förstå istället de andra alternativen innan du provar dem.
Tappar koll på din aktiva datamängd
Dina SPSS-kunskaper utvecklas bra och du bestämmer dig för att det är dags att prova SPSS Syntax. Du dubbelkollar ditt arbete, kör syntaxen och stöter på varningen som visas här. Du bekräftar att du har den nödvändiga datamängden och den nödvändiga variabeln. Vad har hänt?
![10 SPSS Statistics Gotchas]()
Varning: Nödvändiga variabler saknas.
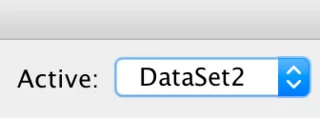
Nästan säkert har du två (eller flera) datauppsättningar öppna och du har tappat koll på vilken som är aktiv. När du arbetar i det grafiska användargränssnittet är det praktiskt taget omöjligt att bli förvirrad, för när du kommer åt menyerna och dialogrutorna gör du det vanligtvis från Data Editor-fönstret. När du använder SPSS Syntax, däremot, kör du kod och det finns ingen garanti för att de nödvändiga dataelementen finns. Så här behöver du göra: Kontrollera om du har mer än en datauppsättning öppen och se till att datauppsättningen du behöver är den aktiva datauppsättningen. Syntaxfönstret har följande indikator:
![10 SPSS Statistics Gotchas]()
DataSet1 är helt enkelt den datauppsättning du öppnade först. För att byta till DataSet2, klicka bara på pilarna och välj det. Du kan även tilldela den datauppsättning som du behöver genom att använda följande syntaxbit: DATASET ACTIVATE DataSet1.
Glömde stänga av Select och Split och Weight
Ett vanligt misstag uppstår när du har att göra med ett kommando som förblir i kraft tills du uttryckligen instruerar SPSS att stänga av det. Tre av dessa kommandon är Select, Split och Weight, som är något ovanliga i SPSS eftersom de vanligtvis är förknippade med en tillfällig justering av en analys, inte med en permanent förändring av data. Vikten är mer teknisk och förknippas oftare med undersökningsanalys. Här är en snabb förklaring av var och en:
- Välj: Indikerar vilka fall du vill inkludera eller exkludera från din analys
- Dela upp : Separerar datasetet med en grupperingsvariabel och analyserar varje grupp separat
- Vikt: Justerar underrepresenterade grupper som om de vore fullt representerade och tillämpar den omvända justeringen på överrepresenterade grupper.
Effektiv användning av alla tre kräver mer än bara en snabb definition. Det är dock lätt att kontrollera om de fortfarande är på, på grund av en indikator i det nedre högra hörnet av Data Editor-fönstret. Filterindikatorn refererar till operationer i dialogrutan Välj fall. Indikatorerna Vikt och Split By hänvisar till dialogerna Vikt respektive Split. (Unicode hänvisar till kodningssystemet som används av SPSS, vilket vanligtvis inte är tillfälligt, även om du kan ändra detta i menyn Redigera → Alternativ.)
![10 SPSS Statistics Gotchas]()
Indikatorerna för filter, vägning och dela.
Om SPSS beter sig konstigt och du inte får de resultat du förväntar dig, kontrollera dessa indikatorer. För att stänga av en indikator, gå tillbaka till dialogrutan där du gav den ursprungliga instruktionen.
Ett vanligt misstag är att av misstag använda Välj och Split samtidigt. (Poweranvändare av SPSS kan göra detta avsiktligt, men bara sällan.) I synnerhet är det aldrig en bra idé att använda Select och Split på samma variabel samtidigt. Om du gör det kommer många varningar att visas i SPSS Output Viewer-fönstret.




")
 Google Meet-mikrofonen fungerar inte, Avstängd på grund av samtalets storlek")
")


-chip på Windows 10")


