Slik finner du servicekoden på en bærbar Windows 10

Hvis du er på markedet for en bærbar Windows 10, vil du gå gjennom mange og mange forskjellige produsenter. De samme produsentene vil ha nok
IBM SPSS Statistics kommer i form av et basissystem, men du kan anskaffe flere moduler for å legge til det systemet. SPSS er tilgjengelig i ulike lisensieringsutgaver : campusutgavene, abonnementsplaner og kommersielle utgaver. Selv om prisene og de forskjellige pakkene er forskjellige for hver, lar de deg alle inkludere de samme tilleggsmodulene.
Hvis du bruker en kopi av SPSS på jobben eller i en universitetssetting som noen andre har installert, kan det hende du har noen av disse tilleggene uten å være klar over det fordi de fleste er så fullstendig integrert i menyene at de ser ut som integrerte deler av basissystem. Hvis du merker at menyene dine er kortere eller lengre enn andres kopi av SPSS, skyldes dette sannsynligvis tilleggsmoduler.
Noen tillegg er kanskje ikke av interesse for deg; mens andre kan bli uunnværlige. Merk at hvis du har en prøvekopi av SPSS, har den sannsynligvis alle modulene, inkludert de du kan miste tilgangen til når du skaffer deg din egen kopi. Denne artikkelen introduserer deg til modulene som kan legges til SPSS og hva de gjør; Se dokumentasjonen som følger med hver modul for en fullstendig opplæring.
Du vil sannsynligvis komme over navnene IBM SPSS Amos og IBM SPSS Modeler . Selv om SPSS vises i navnene, kjøper du disse programmene separat, ikke som tillegg. Amos brukes til Structural Equation Modeling (SEM) og SPSS Modeler er en arbeidsbenk for prediktiv analyse og maskinlæring.
Følgende er en liste over de statistiske teknikkene som er en del av Advanced Statistics-modulen:
Selv om disse prosedyrene er blant de mest avanserte i SPSS, er noen ganske populære. For eksempel er hierarkisk lineær modellering (HLM), en del av lineære blandede modeller, vanlig i utdanningsforskning. HLM-modeller er statistiske modeller der parametere varierer på mer enn ett nivå. For eksempel kan du ha data som inkluderer informasjon for både elever og skoler, og i en HLM-modell kan du samtidig inkludere informasjon fra begge nivåer.
Nøkkelpunktet er at denne avanserte statistiske modulen inneholder spesialiserte teknikker som du må bruke hvis du ikke oppfyller forutsetningene om vanlig vanilje-regresjon og variansanalyse (ANOVA). Disse teknikkene er mer en ANOVA-smak. Overlevelsesanalyse er såkalt tid-til-hendelse-modellering, for eksempel å estimere tid til død etter diagnose.
Custom Tables-modulen har vært den mest populære modulen i årevis, og med god grunn. Hvis du trenger å presse mye informasjon inn i en rapport, trenger du denne modulen. For eksempel, hvis du foretar undersøkelser og ønsker å rapportere om hele undersøkelsen i tabellform, kan Custom Tables-modulen komme deg til unnsetning fordi den lar deg enkelt presentere omfattende informasjon.
Få en gratis prøveversjon av SPSS Statistics med alle modulene, og tving deg selv til å bruke en solid dag med modulene du ikke har. Se om noen aspekter ved rapportering du allerede gjør kan gjøres raskere med egendefinerte tabeller-modulen. Gjengi en nylig rapport, og se hvor mye tid du kan spare.
I den følgende figuren ser du en enkel Frekvenstabell som viser to variabler. Merk at kategoriene for begge variablene er de samme.
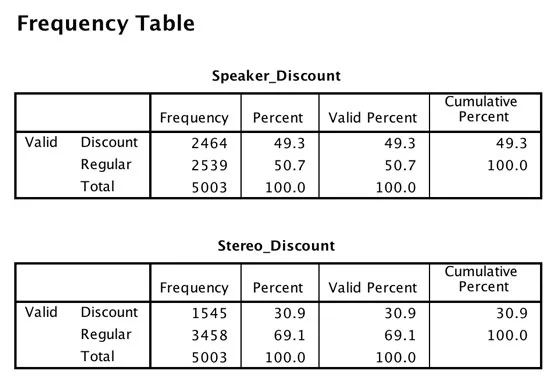
Frekvenstabell for rabattvariablene.
Følgende tabell er de samme dataene, men her ble tabellen opprettet ved hjelp av SPSS Custom Tables-modulen og er en mye bedre tabell.
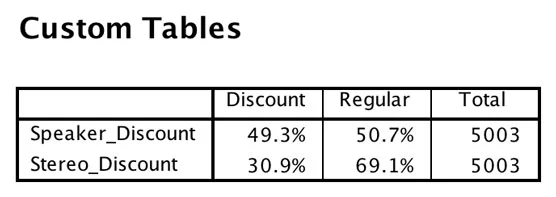
Egendefinert tabell over rabattvariablene.
Hvis du produserer bordet for deg selv, kan presentasjonen ikke ha betydning. Men hvis du legger tabellen i en rapport som skal sendes til andre, trenger du SPSS Custom Tables-modulen. Forresten, med øvelse tar det bare noen få sekunder å lage den tilpassede versjonen, og du kan bruke Syntax for å tilpasse tabellen ytterligere!
Fra og med versjon 27 er Custom Tables-modulen en del av standardutgaven.
Følgende er en liste over de statistiske teknikkene som er en del av regresjonsmodulen:
På noen måter er regresjonsmodulen som Advanced Statistics-modulen - du bruker disse teknikkene når du ikke oppfyller standardforutsetningene. Men med regresjonsmodulen er teknikkene fancy varianter av regresjon når du ikke kan gjøre vanlig minste kvadraters regresjon. Binær logistisk regresjon er populær og brukes når den avhengige variabelen har to kategorier - for eksempel bli eller gå (frafall), kjøpe eller ikke kjøpe, eller få en sykdom eller ikke få en sykdom.
Kategorier-modulen lar deg avsløre relasjoner mellom dine kategoriske data. For å hjelpe deg med å forstå dataene dine bruker Kategorier-modulen perseptuell kartlegging, optimal skalering, preferanseskalering og dimensjonsreduksjon. Ved å bruke disse teknikkene kan du visuelt tolke relasjonene mellom radene og kolonnene dine.
Kategorier-modulen utfører sin analyse på ordinære og nominelle data. Den bruker prosedyrer som ligner på konvensjonell regresjon, hovedkomponenter og kanonisk korrelasjon. Den utfører regresjon ved å bruke nominelle eller ordinære kategoriske prediktorer eller utfallsvariabler.
Prosedyrene i kategorimodulen gjør det mulig å utføre statistiske operasjoner på kategoriske data:
Du kan bruke denne modulen til å lage et par nyttige verktøy:
La oss innse det: Dataforberedelse er ikke noe moro. Vi tar all hjelp vi kan få. Ingen modul vil eliminere alt arbeidet for mennesket i dette menneske-datamaskin-partnerskapet, men Dataforberedelsesmodulen vil eliminere noen rutinemessige, forutsigbare aspekter.
Denne modulen hjelper deg med å behandle rader og kolonner med data. For rader med data hjelper det deg med å identifisere avvikere som kan forvrenge dataene dine. Når det gjelder variabler, hjelper det deg med å identifisere de beste, og gir deg beskjed om at du kan forbedre noen ved å transformere dem. Det lar deg også lage spesielle valideringsregler for å øke hastigheten på datasjekkene dine og unngå mye manuelt arbeid. Til slutt hjelper det deg med å identifisere mønstre i de manglende dataene dine.
Fra og med versjon 27 er dataforberedelse og oppstartsmodulene en del av basisutgaven.
Beslutningstrær er uten tvil den mest populære og kjente datautvinningsteknikken. Faktisk er hele programvareprodukter dedikert til denne tilnærmingen. Hvis du ikke er sikker på om du trenger å gjøre data mining, men du vil prøve det ut, vil bruk av Decision Trees-modulen være en av de beste måtene å prøve data mining fordi du allerede kjenner deg rundt SPSS Statistics. Decision Trees-modulen har ikke alle funksjonene til beslutningstrærene i SPSS Modeler (en hel programvarepakke dedikert til data mining), men det er mye her for å gi deg en god start.
Hva er beslutningstrær? Vel, tanken er at du har noe du vil forutsi (målvariabelen) og mange variabler som muligens kan hjelpe deg med det, men du vet ikke hvilke som er viktigst. SPSS indikerer hvilke variabler som er viktigst og hvordan variablene samhandler, og hjelper deg med å forutsi målvariabelen i fremtiden.
SPSS støtter fire av de mest populære beslutningstrealgoritmene: CHAID, Exhaustive CHAID, C&RT og QUEST.
Du kan bruke prognosemodulen til raskt å lage eksperttidsserieprognoser. Denne modulen inkluderer statistiske algoritmer for å analysere historiske data og forutsi trender. Du kan sette den opp til å analysere hundrevis av forskjellige tidsserier samtidig i stedet for å kjøre en egen prosedyre for hver enkelt.
Programvaren er utviklet for å håndtere de spesielle situasjonene som oppstår i trendanalyse. Den bestemmer automatisk den best passende autoregressive integrerte glidende gjennomsnittet (ARIMA) eller eksponentiell utjevningsmodell. Den tester automatisk data for sesongvariasjoner, intermittens og manglende verdier. Programvaren oppdager uteliggere og hindrer dem i å påvirke resultatene unødig. De genererte grafene inkluderer konfidensintervaller og indikerer modellens god passform.
Etter hvert som du får erfaring med prognoser, gir prognosemodulen deg mer kontroll over hver parameter når du bygger datamodellen. Du kan bruke ekspertmodelleringsverktøyet i Prognosemodulen til å anbefale startpunkter eller sjekke beregninger du har gjort for hånd.
I tillegg forsøker en algoritme kalt Temporal Causal Modeling (TCM) å oppdage viktige årsakssammenhenger i tidsseriedata ved å inkludere kun innganger som har en årsakssammenheng med målet. Dette skiller seg fra tradisjonell tidsseriemodellering, hvor du eksplisitt må spesifisere prediktorene for en målserie.
Dataforberedelsesmodulen ser ut til å ha dekket manglende verdier, men modulen Manglende verdier og modulen for dataforberedelse er ganske forskjellige. Dataforberedelsesmodulen handler om å finne datafeil; valideringsreglene vil fortelle deg om et datapunkt bare ikke er riktig. Manglende verdier-modulen er derimot fokusert på når det ikke er noen dataverdi. Den prøver å estimere den manglende informasjonen ved å bruke andre data du har. Denne prosessen kalles imputasjon, eller å erstatte verdier med en utdannet gjetning. Alle typer dataminere, statistikere og forskere - spesielt undersøkelsesforskere - kan dra nytte av Missing Values-modulen.
Hold ut, for vi kommer til å bli litt tekniske. Bootstrapping er en teknikk som involverer resampling med erstatning. Bootstrapping-modulen velger en sak tilfeldig, gjør notater om den, erstatter den og velger en annen. På denne måten er det mulig å velge en sak mer enn én gang eller ikke i det hele tatt. Nettoresultatet er en annen versjon av dataene dine som er like, men ikke identiske. Hvis du gjør dette 1000 ganger (standard), kan du virkelig gjøre noen kraftige ting.
Bootstrapping-modulen lar deg bygge mer stabile modeller ved å overvinne effekten av uteliggere og andre problemer i dataene dine. Tradisjonell statistikk forutsetter at dataene dine har en bestemt distribusjon, men denne teknikken unngår den antagelsen. Resultatet er en mer nøyaktig følelse av hva som foregår i befolkningen. Bootstrapping er på en måte en enkel idé, men fordi bootstrapping tar mye datamaskinhestekrefter, er det mer populært nå enn da datamaskiner var tregere.
Bootstrapping er en populær teknikk også utenfor SPSS, så du kan finne artikler på nettet om konseptet. Bootstrapping-modulen lar deg bruke dette kraftige konseptet på dataene dine i SPSS Statistics.
Sampling er en stor del av statistikken. Et enkelt tilfeldig utvalg er det vi vanligvis tenker på som et utvalg - som å velge navn fra en hatt. Hatten er din befolkning, og papirlappene du velger tilhører prøven din. Hvert papirark har like stor sjanse til å bli valgt. Forskning er ofte mer komplisert enn som så. Modulen Complex Sample handler om mer kompliserte former for prøvetaking: to-trinns, stratifisert, og så videre.
Oftest trenger undersøkelsesforskere denne modulen, selv om mange typer eksperimentelle forskere også kan ha nytte av den. Complex Samples-modulene hjelper deg med å designe datainnsamlingen, og tar deretter hensyn til designet når du beregner statistikken din. Nesten all statistikk i SPSS er beregnet med antagelsen om at dataene er et enkelt tilfeldig utvalg. Dine beregninger kan bli forvrengt når denne forutsetningen ikke er oppfylt.
Conjoint-modulen gir deg en måte å finne ut hvordan hvert av produktets attributter påvirker forbrukernes preferanser. Når du kombinerer felles analyse med konkurransedyktig markedsproduktundersøkelse, er det lettere å se på produktegenskaper som er viktige for kundene dine.
Med denne undersøkelsen kan du finne ut hvilke produktegenskaper kundene dine bryr seg om, hvilke de bryr seg mest om, og hvordan du kan gjøre nyttige studier av priser og merkevareverdi. Og du kan gjøre alt dette før du pådrar deg kostnadene ved å bringe nye produkter til markedet.
Direktemarkedsføringsmodulen er litt annerledes enn de andre. Det er en bunt med relaterte funksjoner i et trollmannsmiljø. Modulen er designet for å være one-stop shopping for markedsførere. Hovedfunksjonene er nylig, frekvens og monetær (RFM) analyse, klyngeanalyse og profilering:
Exact Tests-modulen gjør det mulig å være mer nøyaktig i din analyse av små datasett og datasett som inneholder sjeldne forekomster. Den gir deg verktøyene du trenger for å analysere slike dataforhold med mer nøyaktighet enn det ellers ville vært mulig.
Når bare en liten prøvestørrelse er tilgjengelig, kan du bruke Exact Tests-modulen til å analysere den mindre prøven og ha mer tillit til resultatene. Her er tanken å utføre flere analyser på kortere tid. Denne modulen lar deg gjennomføre forskjellige undersøkelser i stedet for å bruke tid på å samle prøver for å utvide undersøkelsesbasen din.
Prosessene du bruker, og formene for resultatene, er de samme som i basis SPSS-systemet, men de interne algoritmene er innstilt for å fungere med mindre datasett. Exact Tests-modulen gir mer enn 30 tester som dekker alle de ikke-parametriske og kategoriske testene du vanligvis bruker for større datasett. Inkludert er ett-utvalg, to-utvalg og k-utvalg tester med uavhengige eller relaterte prøver, godhet-of-fit tester, tester av uavhengighet og mål for assosiasjon.
Et nevralt nett er et gitterlignende nettverk av nevronlignende noder, satt opp i SPSS for å virke noe som nevronene i en levende hjerne. Forbindelsene mellom disse nodene har tilhørende vekter (grader av relativ effekt), som er justerbare. Når du justerer vekten på en forbindelse, sies det at nettverket lærer.
I Neural Network-modulen justerer en treningsalgoritme iterativt vektene for å matche de faktiske forholdene mellom dataene. Tanken er å minimere feil og maksimere nøyaktige spådommer. Det beregningsnevrale nettverket har ett lag med nevroner for innganger og et annet for utganger, med ett eller flere skjulte lag mellom dem. Det nevrale nettverket kan brukes sammen med andre statistiske prosedyrer for å gi klarere innsikt.
Ved å bruke det kjente SPSS-grensesnittet kan du mine data for relasjoner. Etter å ha valgt en prosedyre, spesifiserer du de avhengige variablene, som kan være en hvilken som helst kombinasjon av kontinuerlige og kategoriske typer. For å forberede deg til behandling legger du ut den nevrale nettverksarkitekturen, inkludert beregningsressursene du vil bruke. For å fullføre forberedelsen velger du hva du skal gjøre med utdataene:
Hvis du er på markedet for en bærbar Windows 10, vil du gå gjennom mange og mange forskjellige produsenter. De samme produsentene vil ha nok
Hvis du har oppdaget at du bruker Microsoft Teams, men ikke klarer å få det til å gjenkjenne webkameraet ditt, er dette en artikkel du må lese. I denne veiledningen har vi
En av begrensningene ved nettmøter er båndbredde. Ikke alle nettmøteverktøy kan håndtere flere lyd- og/eller videostrømmer samtidig. Apper må
Zoom har blitt det populære valget det siste året, med så mange nye mennesker som jobber hjemmefra for første gang. Den er spesielt flott hvis du må bruke den
Chat-applikasjoner som brukes for produktivitet trenger en måte å forhindre at viktige meldinger går tapt i større, lengre samtaler. Kanaler er én
Microsoft Teams er ment å brukes i en organisasjon. Vanligvis er brukere satt opp over en aktiv katalog og normalt fra samme nettverk eller
Slik ser du etter Trusted Platform Module TPM-brikke på Windows 10
Microsoft Office har for lenge siden flyttet til en abonnementsbasert modell, men eldre versjoner av Office, dvs. Office 2017 (eller eldre) fungerer fortsatt, og de
Microsoft Teams er en av mange apper som har sett en jevn økning i brukere siden arbeidet har flyttet på nettet for mange mennesker. Appen er et ganske robust verktøy for
Hvordan installere Zoom videokonferanse-appen på Linux
")
 Google Meet-mikrofon fungerer ikke, Av på grunn av størrelsen på samtalen")
")


-brikke på Windows 10")


