Slik finner du servicekoden på en bærbar Windows 10

Hvis du er på markedet for en bærbar Windows 10, vil du gå gjennom mange og mange forskjellige produsenter. De samme produsentene vil ha nok
Våre 10 gotchas fungerer som en sjekkliste over potensielle årsaker til dine SPSS-statistikkproblemer . Noen kaster bare bort tiden din, men andre kan både kaste bort tiden din og ødelegge analysen din. Denne listen forsterker viktigheten av å unngå disse vanlige problemene slik at du effektivt kan bruke SPSS.
Noen av disse 10 gotchaene kan være forvirrende i begynnelsen. Andre er enkle, men nye brukere tilskriver dem kanskje ikke den betydningen de fortjener. Felles for dem alle er at uvitenhet om dem kan få deg til varmt vann. Når noe ser ut til å være galt i SPSS, dobbeltsjekk denne listen. For å komme seg inn på denne listen, må disse godchasene ha generert hundrevis av problemer i den virkelige verden, slik vi har sett i kontakt med klientene våre.
For mange nye brukere av SPSS virker det å erklære målenivå som en plage. Du kan trygt ignorere det en stund, men vårt råd er å ikke vente til den dagen det begynner å forårsake problemer. Her er bare noen få bemerkelsesverdige situasjoner der du vil angre på en beslutning om å utsette å sette opp datasettene dine riktig:
Riktig metadata er et must for effektiv bruk av SPSS. De som prøver å spare tid ved å hoppe over trinnet med å sette opp datasettene sine riktig, vil aldri lykkes fordi de i det lange løp vil kaste bort tid på å finne ut hvorfor SPSS ikke oppfører seg som den skal.
Unngå å bruke strengvariabeltypen. Bruk i stedet en kombinasjon av verdier og verdietiketter. Tilbake på 60- og 70-tallet var RAM- og harddiskplass dyrt og begrenset. Strenger bruker mange flere tegn og byte enn numeriske, og den gang kunne ikke SPSS utføre beregninger ved å bruke RAM alene, så den trengte å bruke harddisken da vi kanskje brukte en skrapelodd. Nå kan det virke underlig å bekymre seg for slike ting, men å unngå strenger er fortsatt kjernen i designfilosofien til SPSS.
Så hva slags variabler bør lagres som strenger? Adresser, åpne kommentarer i undersøkelsesdata og navn på personer og selskaper er gode eksempler på strengvariabler. Det er ikke mange flere. Navnene på de 50 statene, navnene på produkter, produktkategorier og SKU-er, og de fleste andre nominelle variabler bør settes opp som par med verdier og verdietiketter.
Tidligere utgjorde innledende nuller i data som postnummer et problem, så dataene ville bli erklært som streng. Nå legger imidlertid den begrensede numeriske variabeltypen til innledende nuller polstret til den maksimale bredden på variabelen, slik at en postkodevariabel ikke lenger trenger å deklareres som en streng. Autorecode gjør også konverteringer fra streng til numerisk enkel. Hold strengvariabler på et minimum.
Excel-filer tillater ikke metadata, så Excel støtter ikke verdi- og verdietikettpar. Når du ofte importerer strengdata fra Excel, bør du vurdere å lære syntakskommandoer i tillegg til autorecode-transformasjon fordi disse teknikkene kan være nyttige.
For mange år siden opplevde en SPSS-bruker i en av våre klasser følgende situasjon. Han hadde en skala fra 1 til 10, med 10 som høyeste tilfredshetsvurdering og 1 som laveste tilfredshetsvurdering. Han trengte en kode for å representere «nektet å svare» og valgte 11. Da han fikk vite om manglende data i klassen, lurte han på om det ville være greit å bare la 11-tallet i dataene, fordi han allerede hadde fullført analysen og antallet avslag var ganske lavt.
Du vedder på at det forårsaket et stort problem! Det kan flytte gjennomsnittlig tilfredshet ganske langt mot 11 selv med 1 til 2 prosent frafall. Det som var slående med dette eksemplet var at det vanligste svaret, 1, var veldig langt fra den kodede verdien for frafall. Det faktum burde ha gjort analysen åpenbart feil og lett å få øye på. Enda verre, det er godt forstått i undersøkelsesundersøkelser at avslag ofte gjenspeiler respondenter som er svært misfornøyde, men motvillige til å dele sin mening. Valget av 11 fikk deres mening til å se svært fornøyd ut, ikke svært misfornøyd, noe som forvrengte resultatene enda mer.
Dessverre glemmer folk å erklære savnet ganske ofte, og feilen vedvarer ofte gjennom de siste trinnene i analysen og blir aldri avdekket. I eksemplet kunne problemet vært løst med ett enkelt trinn: Erklær 11 som brukerdefinert mangler. Vær på vakt med å deklarere manglende dataverdier i metadataene dine.
Hva kan gå galt med tilleggsmoduler? Problemet som vi ofte observerer hos klienter er at de leser om funksjoner i tilleggsmoduler og deretter ikke finner modulene. Dette kan virke rart. Ville ikke alle vite hvilke SPSS-funksjoner de eier? Men du kan også bli forvirret av flere grunner:
SPSS implementerer tilleggsmoduler ved å legge dem til menyene dine, vanligvis i hovedmenyen Analyser. I den følgende figuren kan du se Analyser-menyen fra skjermen til en prøveversjon av et SPSS-abonnement. Prøveversjonen har alltid alle moduler. Så hvis menyen din er kortere enn den du ser på bildet, vet du at du ikke har hele utvalget av tilleggsmoduler.
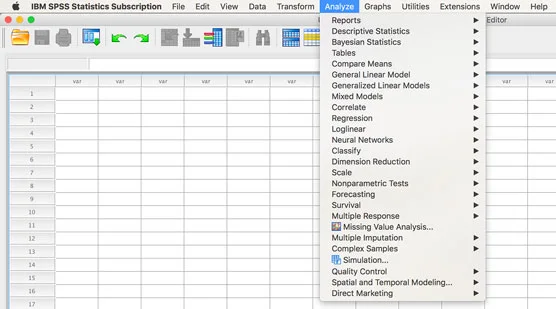
Analyser-menyen med alle moduler tilgjengelig.
Ingenting er galt med din kopi av SPSS. Du har bare ikke tilgang til alle funksjoner, inkludert via SPSS Syntax. Noen mener at hvis du kjenner den nødvendige koden og omgår det grafiske brukergrensesnittet, kan du kjøre hvilken som helst kommando, men det er ikke sant. For å kjøre syntaksen for en tilleggsmodul, må du eie modulen. Vi understreker dette punktet fordi vi har sett folk låne Syntax fra en kilde, kollega eller bok, og prøver å kopiere og lime inn koden i Syntax-vinduet. Syntakskoden vil ikke fungere hvis du mangler riktig lisensiering.
En annen vanlig kilde til forvirring er at mange SPSS-brukere ikke skjønner at de har tilgang til tilleggsmoduler på jobb eller skole. Dette er uheldig fordi modulene kan være ekstremt nyttige. Vi anbefaler alltid Custom Tables-modulen til kunder for større effektivitet i analysen. Utallige ganger har klienter trodd at de ikke hadde noen moduler bare for å oppdage at tilpassede tabeller var synlige i menyene og fungerte.

Til slutt, "plugins" er litt annerledes enn tilleggsmoduler. Funksjoner kan legges til SPSS ved å bruke Python og R. Hvis du er en programmerer, kan du vurdere å gjøre denne oppgaven selv. Imidlertid er mange av disse utvidelsene allerede tilgjengelige. Alt du trenger å gjøre er å laste dem ned, så vises de som ekstra menyelementer, med et plusssymbol ved siden av menyoppføringen (se margikonet). Den pensjonerte SPSSer Jon Peck var medvirkende til å legge denne programmerbarhetsfunksjonen til SPSS.
SPSS er ikke så smart. SPSS vil gjøre hva du ber den om å gjøre. Så hvis du har en variabel som Sivilstatus, med verdiene: 1= Gift, 2=Skilt, 3=Separert, 4=Enke og 5=Singel, og du ber SPSS om å gi deg et gjennomsnitt for Sivilstatus, SPSS vil gi deg et middel. Imidlertid er et gjennomsnitt på 2,33 for en nominell variabel som sivilstatus ikke nyttig. Tilsvarende, hvis du analyserer dataene dine og finner ut at 100 % av vennene dine som du undersøkte, mener at mer økonomiske ressurser bør vies til tennissenteret på landsklubben din, men du bare har intervjuet tennisspillere, kan du ikke gi resultater fra deg som et tilfeldig utvalg av country club-medlemmer, og du kan heller ikke bli overrasket over funnene dine.
Det er viktig at du har pålitelige og gyldige data. SPSS antar at dataene dine kommer fra et tilfeldig utvalg; hvis dette ikke er tilfelle, kan du fortsatt få beskrivende informasjon, men du vil ikke kunne generalisere resultatene dine til en populasjon. Du må også vite hvilken informasjon du kan hente fra dataene dine.
I tillegg er det viktig å huske at hver statistisk test har forutsetninger. Noen statistiske tester i SPSS, som den uavhengige samples t-testen, vurderer automatisk noen av testforutsetningene, men mesteparten av tiden; du må kjøre ytterligere kontroller for å vurdere testforutsetninger. Husk at jo bedre du oppfyller testforutsetningene, jo mer kan du stole på resultatene av en test.
Du kan høre at en test er sensitiv for brudd på forutsetninger eller robust for brudd på forutsetninger. Når en test er sensitiv , må du være spesielt forsiktig med å oppfylle forutsetningene. Når en test er robust , er det mer slingringsmonn med forutsetningene.
Så godt som alle SPSS-brukere starter med å lære SPSS via det grafiske brukergrensesnittet, og mange synes SPSS Syntax er litt mystisk. Forvirringen oppstår når en kollega deler litt syntakskode og tilbyr det som en snarvei, men det hele kan se veldig skremmende ut. Frykten er at du må ha en stor bok åpen på skrivebordet ditt og at du skal skrive kommandoene bokstav for bokstav. Dette er rett og slett ikke sant.
Selv om en velmenende kollega utbryter «Det er enkelt, bare lim det inn», er det kanskje ikke klart hva de mener. Å lime inn i SPSS, med tanke på SPSS-syntaks, betyr å la SPSS-dialogene generere syntakskoden for deg ved å gi instruksjonene via pek og klikk. Syntaksen genereres deretter og sendes til syntaksvinduet. Du kan tenke på det som å konvertere klikk til kode. Det er ikke kopier, lim-manøveren (Control-C, Control-V i Windows) som vi gjør i de fleste programvare.
Nesten alle som lærer SPSS, bringer tidligere eksponering for Excel til læringsopplevelsen. Det er en kritisk funksjon i begge som håndteres ganske forskjellig i de to grensesnittene. I Excel, når du vil implementere en formel, jobber du direkte i en celle i regnearket, og formelen lagres på samme sted når du lagrer regnearket. I SPSS må du bruke dialogboksen Compute Variable (eller tilsvarende i SPSS Syntax) og formelen din lagres ikke i datasettet @@md, bare resultatet lagres i datasettet.
Til å begynne med kan det virke svært ønskelig for alle å lagre formler i datasettet, men det er kanskje ikke klart den høye prisen som betales for denne funksjonen i Excel. SPSS er bygget for å være skalerbar til store datasett, noen ganger 100-vis av millioner av rader med data. I Excel må regnearket kontinuerlig skannes for å oppdatere verdiene til formler. Denne skanningen, passivt og automatisk i bakgrunnen, bruker ressurser og gjør Excel mindre skalerbar til veldig store datasett. Excel blir merkbart treg når datasett er veldig store av denne grunn, men Excel ble aldri designet for store datasett. I SPSS forblir dataene konstante med mindre en handling ber om en endring. For å tvinge beregninger til å oppdatere, må enten menyene brukes på nytt eller SPSS Syntax må kjøres på nytt. Hvert system er utformet med dens primære målgruppe i tankene.
Hvis du er mer kjent med hvordan Excel automatisk oppdaterer beregninger, hvordan bør du akklimatisere deg til SPSS? Hvis mesteparten av dataene dine leses inn fra en fil og du går direkte til analyse, vil du sannsynligvis være ganske fornøyd med det grafiske brukergrensesnittet. Hvis du har veldig store filer eller hvis du har et stort antall beregninger som gjøres etter at dataene er lest inn fra en fil, må du lære SPSS Syntax for å være produktiv. Ved å lagre disse beregningene, kanskje dusinvis eller hundrevis av dem, i form av SPSS Syntax kan du kjøre dem alle på nytt ganske enkelt.
Excel har for tiden en grense på 1 000 000 rader med data, men for bare noen få år siden var grensen mye mindre. Dette er sjelden et problem for Excel-brukere, da mange rader vanligvis er tilstrekkelig. Excel-eksperter kan ofte finne en vei rundt denne grensen, men det er sjelden nødvendig. Den tekniske årsaken til denne grensen er at hele regnearket må være tilgjengelig for datamaskinens minne. SPSS krever ikke at hele datasettet får plass i datamaskinens minne. Dette er viktig for mange SPSS-brukere fordi tusenvis av selskaper med datasett som er større enn grensen for millioner rader, må analysere sine store datasett i SPSS. IRS er et bemerkelsesverdig eksempel på en organisasjon som bruker SPSS som har datasett som er mye større enn grensen for millioner rader.
Manglende data har ofte blitt behandlet som et emne i kapittellengde (eller til og med boklengde), men en diskusjon av den lengden er ikke mulig i denne artikkelen. Du kan håndtere manglende data på mange måter, en av dem er å bruke listevis sletting. Og å være kjent med begrepet listevis sletting kan varsle deg om det som ellers ville virke som merkelig oppførsel i SPSS. Tenk deg at du har et stort datasett, med tusenvis av rader. Men når du kjører en multivariat analyse, oppfører SPSS seg som om du ikke har noen data i det hele tatt. Du sjekker trinnene flere ganger, men alt du ser i resultatene er meldinger som indikerer at du ikke har «ingen gyldige tilfeller». Hva kan skje?
Listevis sletting er en metode for å bestemme hvilke tilfeller i datasettet som brukes av SPSS for multivariat analyse. Når denne metoden brukes, brukes kun tilfeller som er gyldige for alle variabler i analysen. Manglende bare én enkelt celle med informasjon i saksraden vil føre til at hele saken fjernes. Hvorfor er dette vanlig? Tenk deg at du samler data om flypassasjerer. En kolonne registrerer om en passasjer valgte å kjøpe et måltid ombord, som kun gjelder busspassasjerer. En annen kolonne registrerer hvilket av to måltidsvalg personen valgte under førsteklasses måltid, som kun gjelder førsteklasses passasjerer. Hver rad i datasettet vil mangle den ene eller den andre, noe som resulterer i at null rader med data blir presentert for den multivariate analysen. Denne situasjonen er vanlig.
Denne korte diskusjonen er ikke tilstrekkelig til å veie fordeler og ulemper ved å bruke listevis sletting. Du vil imidlertid nå være klar over det når du støter på problemet med null tilfeller som blir analysert. Vær også på utkikk etter tidspunkter hvor mange færre saker enn du forventet blir analysert. I dialogboksen Alternativer i dialogboksen Lineær regresjon er listevis sletting standard. Vær forsiktig så du ikke tilfeldig velger blant de andre valgene før regresjonen fungerer. I stedet må du forstå de andre alternativene før du prøver dem.
SPSS-ferdighetene dine utvikler seg godt, og du bestemmer deg for at det er på tide å prøve SPSS Syntax. Du dobbeltsjekker arbeidet ditt, kjører syntaksen og møter advarselen som vises her. Du bekrefter at du har det nødvendige datasettet og den nødvendige variabelen. Hva som har skjedd?

Advarsel: Nødvendige variabler mangler.
Nesten sikkert, du har to (eller flere) datasett åpne og du har mistet oversikten over hvilken som er aktiv. Når du jobber i det grafiske brukergrensesnittet, er det praktisk talt umulig å bli forvirret fordi når du åpner menyene og dialogboksene, gjør du det vanligvis fra Data Editor-vinduet. Når du bruker SPSS-syntaks, kjører du imidlertid kode og det er ingen garanti for at de nødvendige dataelementene er tilstede. Her er hva du trenger å gjøre: Sjekk for å se om du har mer enn ett datasett åpent, og sørg for at datasettet du trenger er det aktive datasettet. Syntaksvinduet har følgende indikator:
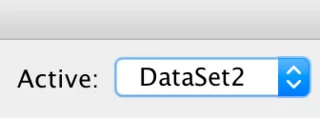
DataSet1 er ganske enkelt datasettet du åpnet først. For å bytte til DataSet2 klikker du bare på pilene og velger det. Du kan også tilordne datasettet du trenger ved å bruke følgende syntaksbit: DATASET ACTIVATE DataSet1.
En vanlig feil oppstår når du har å gjøre med en kommando som forblir i kraft til du eksplisitt ber SPSS om å slå den av. Tre av disse kommandoene er Select, Split og Weight, som er noe uvanlig i SPSS fordi de vanligvis er forbundet med en midlertidig justering av en analyse, ikke med en permanent endring av dataene. Vekt er mer teknisk og er oftere forbundet med undersøkelsesanalyse. Her er en rask forklaring av hver:
Effektiv bruk av alle tre krever mer enn bare en rask definisjon. Det er imidlertid enkelt å sjekke om de fortsatt er på, på grunn av en indikator i nedre høyre hjørne av Data Editor-vinduet. Filterindikatoren refererer til operasjoner i dialogboksen Velg saker. Indikatorene Weight og Split By refererer til henholdsvis Weight og Split dialogene. (Unicode refererer til kodingssystemet som brukes av SPSS, som vanligvis ikke er midlertidig, selv om du kan endre dette i Rediger → Alternativer-menyen.)

Filter-, veie- og splittindikatorene.
Hvis SPSS oppfører seg merkelig og du ikke får de resultatene du forventer, sjekk disse indikatorene. For å slå av en indikator, gå tilbake til dialogboksen der du ga den opprinnelige instruksjonen.
En vanlig feil er å ved et uhell bruke Select og Split samtidig. (Power-brukere av SPSS kan gjøre dette med vilje, men bare sjelden.) Spesielt er det aldri en god idé å bruke Select og Split på samme variabel samtidig. Hvis du gjør det, vil en rekke advarsler vises i SPSS Output Viewer-vinduet.
Hvis du er på markedet for en bærbar Windows 10, vil du gå gjennom mange og mange forskjellige produsenter. De samme produsentene vil ha nok
Hvis du har oppdaget at du bruker Microsoft Teams, men ikke klarer å få det til å gjenkjenne webkameraet ditt, er dette en artikkel du må lese. I denne veiledningen har vi
En av begrensningene ved nettmøter er båndbredde. Ikke alle nettmøteverktøy kan håndtere flere lyd- og/eller videostrømmer samtidig. Apper må
Zoom har blitt det populære valget det siste året, med så mange nye mennesker som jobber hjemmefra for første gang. Den er spesielt flott hvis du må bruke den
Chat-applikasjoner som brukes for produktivitet trenger en måte å forhindre at viktige meldinger går tapt i større, lengre samtaler. Kanaler er én
Microsoft Teams er ment å brukes i en organisasjon. Vanligvis er brukere satt opp over en aktiv katalog og normalt fra samme nettverk eller
Slik ser du etter Trusted Platform Module TPM-brikke på Windows 10
Microsoft Office har for lenge siden flyttet til en abonnementsbasert modell, men eldre versjoner av Office, dvs. Office 2017 (eller eldre) fungerer fortsatt, og de
Microsoft Teams er en av mange apper som har sett en jevn økning i brukere siden arbeidet har flyttet på nettet for mange mennesker. Appen er et ganske robust verktøy for
Hvordan installere Zoom videokonferanse-appen på Linux
")
 Google Meet-mikrofon fungerer ikke, Av på grunn av størrelsen på samtalen")
")


-brikke på Windows 10")


