Sådan finder du servicemærket på en bærbar Windows 10

Hvis du er på markedet efter en bærbar Windows 10, vil du gå igennem mange og mange forskellige producenter. De samme producenter vil have rigeligt
IBM SPSS Statistics kommer i form af et basissystem, men du kan anskaffe yderligere moduler for at tilføje til det system. SPSS er tilgængelig i forskellige licensudgaver : campusudgaver, abonnementsplaner og kommercielle udgaver. Selvom priserne og de forskellige bundter er forskellige for hver, giver de dig alle mulighed for at inkludere de samme tilføjelsesmoduler.
Hvis du bruger en kopi af SPSS på arbejdet eller i et universitetsmiljø, som en anden har installeret, har du måske nogle af disse tilføjelser uden at være klar over det, fordi de fleste er så fuldt integrerede i menuerne, at de ligner integrerede dele af basissystem. Hvis du bemærker, at dine menuer er kortere eller længere end en andens kopi af SPSS, skyldes det sandsynligvis tilføjelsesmoduler.
Nogle tilføjelser har måske ingen interesse for dig; mens andre kunne blive uundværlige. Bemærk, at hvis du har en prøvekopi af SPSS, har den sandsynligvis alle modulerne, inklusive dem, som du muligvis mister adgang til, når du erhverver din egen kopi. Denne artikel introducerer dig til de moduler, der kan føjes til SPSS, og hvad de gør; Se dokumentationen, der følger med hvert modul, for en komplet vejledning.
Du vil sandsynligvis støde på navnene IBM SPSS Amos og IBM SPSS Modeler . Selvom SPSS optræder i navnene, køber du disse programmer separat, ikke som tilføjelser. Amos bruges til Structural Equation Modeling (SEM) og SPSS Modeler er en forudsigende analyse- og maskinlæringsarbejdsbord.
Følgende er en liste over de statistiske teknikker, der er en del af modulet Advanced Statistics:
Selvom disse procedurer er blandt de mest avancerede i SPSS, er nogle ret populære. For eksempel er hierarkisk lineær modellering (HLM), en del af lineære blandede modeller, almindelig i uddannelsesforskning. HLM-modeller er statistiske modeller, hvor parametre varierer på mere end ét niveau. For eksempel kan du have data, der inkluderer informationer for både elever og skoler, og i en HLM-model kan du samtidig inkorporere information fra begge niveauer.
Nøglepunktet er, at dette avancerede statistiske modul indeholder specialiserede teknikker, som du skal bruge, hvis du ikke opfylder antagelserne om almindelig vanilje-regression og variansanalyse (ANOVA). Disse teknikker er mere en ANOVA-smag. Overlevelsesanalyse er såkaldt tid-til-hændelse-modellering, såsom estimering af tid til død efter diagnose.
Custom Tables-modulet har været det mest populære modul i årevis og med god grund. Hvis du skal presse en masse information ind i en rapport, har du brug for dette modul. For eksempel, hvis du laver undersøgelsesundersøgelser og ønsker at rapportere om hele undersøgelsen i tabelform, kan Custom Tables-modulet komme dig til undsætning, fordi det giver dig mulighed for nemt at præsentere omfattende information.
Få en gratis prøveversion af SPSS Statistics med alle modulerne, og tving dig selv til at bruge en solid dag på de moduler, du ikke har. Se, om ethvert aspekt af rapportering, du allerede laver, kunne udføres hurtigere med modulet Custom Tables. Gengiv en nylig rapport, og se, hvor meget tid du kan spare.
I den følgende figur ser du en simpel frekvenstabel, der viser to variable. Bemærk, at kategorierne for begge variabler er de samme.
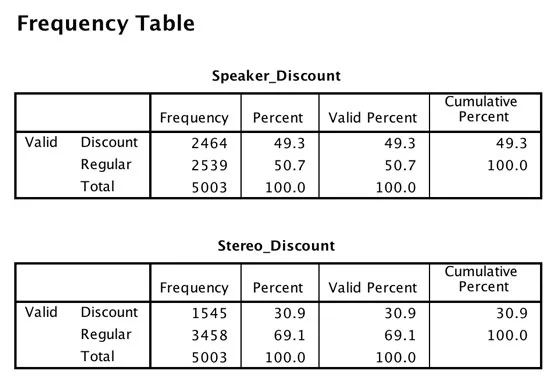
Hyppighedstabel over rabatvariablerne.
Følgende tabel er de samme data, men her blev tabellen oprettet ved hjælp af SPSS Custom Tables-modulet og er en meget bedre tabel.
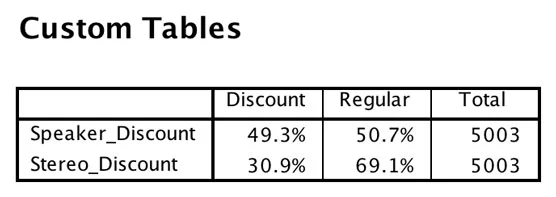
Brugerdefineret tabel over rabatvariablerne.
Hvis du laver bordet til dig selv, er præsentationen måske ligegyldig. Men hvis du sætter tabellen i en rapport, der vil blive sendt til andre, har du brug for SPSS Custom Tables-modulet. Forresten, med øvelse tager det kun et par sekunder at lave den brugerdefinerede version, og du kan bruge Syntax til at tilpasse tabellen yderligere!
Fra version 27 er modulet Custom Tables en del af standardudgaven.
Følgende er en liste over de statistiske teknikker, der er en del af regressionsmodulet:
På nogle måder er regressionsmodulet ligesom modulet Advanced Statistics - du bruger disse teknikker, når du ikke opfylder standardantagelserne. Men med regressionsmodulet er teknikkerne smarte varianter af regression, når du ikke kan lave almindelig mindste kvadraters regression. Binær logistisk regression er populær og bruges, når den afhængige variabel har to kategorier - for eksempel blive eller gå (frafald), købe eller ikke købe, eller få en sygdom eller ikke få en sygdom.
Kategorier-modulet giver dig mulighed for at afsløre relationer mellem dine kategoriske data. For at hjælpe dig med at forstå dine data bruger Kategorier-modulet perceptuel kortlægning, optimal skalering, præferenceskalering og dimensionsreduktion. Ved at bruge disse teknikker kan du visuelt fortolke relationerne mellem dine rækker og kolonner.
Kategorier-modulet udfører sin analyse på ordinære og nominelle data. Den bruger procedurer svarende til konventionel regression, hovedkomponenter og kanonisk korrelation. Den udfører regression ved hjælp af nominelle eller ordinære kategoriske prædiktorer eller udfaldsvariable.
Procedurerne i kategorimodulet gør det muligt at udføre statistiske operationer på kategoriske data:
Du kan bruge dette modul til at fremstille et par nyttige værktøjer:
Lad os se det i øjnene: Dataforberedelse er ikke sjovt. Vi tager al den hjælp vi kan få. Intet modul vil eliminere alt arbejdet for mennesket i dette menneske-computer-partnerskab, men dataforberedelsesmodulet vil fjerne nogle rutinemæssige, forudsigelige aspekter.
Dette modul hjælper dig med at behandle rækker og kolonner med data. For rækker af data hjælper det dig med at identificere outliers, der kan forvrænge dine data. Hvad angår variabler, hjælper det dig med at identificere de bedste og fortæller dig, at du kan forbedre nogle ved at transformere dem. Det giver dig også mulighed for at oprette særlige valideringsregler for at fremskynde dine datatjek og undgå en masse manuelt arbejde. Endelig hjælper det dig med at identificere mønstre i dine manglende data.
Fra og med version 27 er dataforberedelse og bootstrapping-modulerne en del af basisudgaven.
Beslutningstræer er langt den mest populære og velkendte data mining-teknik. Faktisk er hele softwareprodukter dedikeret til denne tilgang. Hvis du ikke er sikker på, om du skal lave datamining, men du gerne vil prøve det, ville brug af Decision Trees-modulet være en af de bedste måder at forsøge datamining på, fordi du allerede kender dig til SPSS-statistik. Decision Trees-modulet har ikke alle funktionerne i beslutningstræerne i SPSS Modeler (en hel softwarepakke dedikeret til data mining), men der er masser her til at give dig en god start.
Hvad er beslutningstræer? Nå, tanken er, at du har noget, du vil forudsige (målvariablen) og masser af variabler, der muligvis kan hjælpe dig med at gøre det, men du ved ikke, hvilke der er vigtigst. SPSS angiver, hvilke variabler der er vigtigst, og hvordan variablerne interagerer, og hjælper dig med at forudsige målvariablen i fremtiden.
SPSS understøtter fire af de mest populære beslutningstræalgoritmer: CHAID, Exhaustive CHAID, C&RT og QUEST.
Du kan bruge prognosemodulet til hurtigt at konstruere eksperttidsserieprognoser. Dette modul indeholder statistiske algoritmer til at analysere historiske data og forudsige tendenser. Du kan indstille det til at analysere hundredvis af forskellige tidsserier på én gang i stedet for at køre en separat procedure for hver enkelt.
Softwaren er designet til at håndtere de særlige situationer, der opstår i trendanalyse. Den bestemmer automatisk den bedst passende autoregressive integrerede glidende gennemsnit (ARIMA) eller eksponentiel udjævningsmodel. Den tester automatisk data for sæsonbestemte, intermitterende og manglende værdier. Softwaren registrerer outliers og forhindrer dem i at påvirke resultaterne unødigt. De genererede grafer inkluderer konfidensintervaller og angiver modellens gode pasform.
Efterhånden som du får erfaring med prognoser, giver prognosemodulet dig mere kontrol over hver parameter, når du bygger din datamodel. Du kan bruge ekspertmodelleren i prognosemodulet til at anbefale udgangspunkter eller til at kontrollere beregninger, du har lavet i hånden.
Derudover forsøger en algoritme kaldet Temporal Causal Modeling (TCM) at opdage nøgleårsagssammenhænge i tidsseriedata ved kun at inkludere input, der har en årsagssammenhæng med målet. Dette adskiller sig fra traditionel tidsseriemodellering, hvor du eksplicit skal angive prædiktorerne for en målserie.
Dataforberedelsesmodulet ser ud til at have manglende værdier dækket, men modulet Manglende værdier og modulet Dataforberedelse er ret forskellige. Dataforberedelsesmodulet handler om at finde datafejl; dens valideringsregler vil fortælle dig, om et datapunkt bare ikke er rigtigt. Manglende værdier-modulet er derimod fokuseret på, når der ikke er nogen dataværdi. Den forsøger at estimere den manglende information ved hjælp af andre data, du har. Denne proces kaldes imputation, eller at erstatte værdier med et kvalificeret gæt. Alle former for dataminere, statistikere og forskere - især undersøgelsesforskere - kan drage fordel af Missing Values-modulet.
Hold nu fast, for vi bliver lidt tekniske. Bootstrapping er en teknik, der involverer resampling med udskiftning. Bootstrapping-modulet vælger en sag tilfældigt, laver noter om den, erstatter den og vælger en anden. På denne måde er det muligt at vælge en sag mere end én gang eller slet ikke. Nettoresultatet er en anden version af dine data, der er ens, men ikke identisk. Hvis du gør dette 1.000 gange (standardindstillingen), kan du virkelig gøre nogle kraftfulde ting.
Bootstrapping-modulet giver dig mulighed for at bygge mere stabile modeller ved at overvinde effekten af outliers og andre problemer i dine data. Traditionel statistik antager, at dine data har en bestemt fordeling, men denne teknik undgår denne antagelse. Resultatet er en mere præcis fornemmelse af, hvad der foregår i befolkningen. Bootstrapping er på en måde en simpel idé, men fordi bootstrapping tager mange computerhestekræfter, er det mere populært nu, end da computere var langsommere.
Bootstrapping er også en populær teknik uden for SPSS, så du kan finde artikler på nettet om konceptet. Bootstrapping-modulet lader dig anvende dette kraftfulde koncept på dine data i SPSS Statistics.
Sampling er en stor del af statistikken. En simpel tilfældig prøve er, hvad vi normalt tænker på som en prøve - som at vælge navne ud af en hat. Hatten er din befolkning, og de papirstumper, du vælger, tilhører din prøve. Hvert stykke papir har lige stor chance for at blive valgt. Forskning er ofte mere kompliceret end som så. Modulet Complex Sample handler om mere komplicerede former for sampling: to-trins, stratificeret og så videre.
Oftest har undersøgelsesforskere brug for dette modul, selvom mange slags eksperimentelle forskere også kan drage fordel af det. Complex Samples-modulerne hjælper dig med at designe dataindsamlingen og tager derefter designet i betragtning, når du beregner din statistik. Næsten al statistik i SPSS er beregnet ud fra den antagelse, at dataene er en simpel stikprøve. Dine beregninger kan blive forvrænget, når denne antagelse ikke er opfyldt.
Conjoint-modulet giver dig mulighed for at bestemme, hvordan hver af dit produkts egenskaber påvirker forbrugernes præferencer. Når du kombinerer analyse med konkurrerende markedsproduktundersøgelser, er det nemmere at sætte fokus på produktegenskaber, der er vigtige for dine kunder.
Med denne undersøgelse kan du bestemme, hvilke produktegenskaber dine kunder interesserer sig for, hvilke de holder mest af, og hvordan du kan lave nyttige undersøgelser af prissætning og brand equity. Og du kan gøre alt dette, før du pådrager dig udgifterne til at bringe nye produkter på markedet.
Direct Marketing-modulet er lidt anderledes end de andre. Det er et bundt af relaterede funktioner i et troldmandslignende miljø. Modulet er designet til at være one-stop shopping for marketingfolk. Hovedfunktionerne er aktualitets-, frekvens- og pengeanalyse (RFM), klyngeanalyse og profilering:
Exact Tests-modulet gør det muligt at være mere præcis i din analyse af små datasæt og datasæt, der indeholder sjældne forekomster. Det giver dig de værktøjer, du skal bruge til at analysere sådanne dataforhold med mere nøjagtighed, end det ellers ville være muligt.
Når kun en lille prøvestørrelse er tilgængelig, kan du bruge Exact Tests-modulet til at analysere den mindre prøve og have mere tillid til resultaterne. Her er tanken at udføre flere analyser på kortere tid. Dette modul giver dig mulighed for at udføre forskellige undersøgelser i stedet for at bruge tid på at indsamle prøver for at udvide din base af undersøgelser.
De processer, du bruger, og formerne for resultaterne, er de samme som dem i basis SPSS-systemet, men de interne algoritmer er indstillet til at fungere med mindre datasæt. Exact Tests-modulet giver mere end 30 tests, der dækker alle de ikke-parametriske og kategoriske tests, du normalt bruger til større datasæt. Inkluderet er et-stikprøve-, to-udvalgs- og k-stikprøve-test med uafhængige eller relaterede prøver, goodness-of-fit-test, uafhængighedstest og mål for association.
Et neuralt net er et gitterlignende netværk af neuronlignende noder, der er sat op i SPSS til at virke noget som neuronerne i en levende hjerne. Forbindelserne mellem disse noder har tilhørende vægte (grader af relativ effekt), som er justerbare. Når du justerer vægten af en forbindelse, siges netværket at lære.
I modulet Neural Network justerer en træningsalgoritme iterativt vægtene, så de stemmer nøje overens med de faktiske forhold mellem dataene. Idéen er at minimere fejl og maksimere nøjagtige forudsigelser. Det computational neurale netværk har et lag af neuroner til input og et andet til output, med et eller flere skjulte lag mellem dem. Det neurale netværk kan bruges sammen med andre statistiske procedurer for at give klarere indsigt.
Ved at bruge den velkendte SPSS-grænseflade kan du mine data til relationer. Når du har valgt en procedure, specificerer du de afhængige variable, som kan være en hvilken som helst kombination af kontinuerte og kategoriske typer. For at forberede dig til behandling lægger du den neurale netværksarkitektur, inklusive de beregningsressourcer, du vil anvende. For at fuldføre forberedelsen vælger du, hvad du vil gøre med outputtet:
Hvis du er på markedet efter en bærbar Windows 10, vil du gå igennem mange og mange forskellige producenter. De samme producenter vil have rigeligt
Hvis du har opdaget, at du bruger Microsoft Teams, men ikke kan få det til at genkende dit webcam, er dette en artikel, du skal læse. I denne guide har vi
En af begrænsningerne ved onlinemøder er båndbredde. Ikke alle onlinemødeværktøjer kan håndtere flere lyd- og/eller videostreams på én gang. Apps skal
Zoom er blevet det populære valg det seneste år, hvor så mange nye mennesker arbejder hjemmefra for første gang. Den er især god, hvis du skal bruge den
Chatapplikationer, der bruges til produktivitet, har brug for en måde at forhindre, at vigtige beskeder går tabt i større, længere samtaler. Kanaler er én
Microsoft Teams er beregnet til at blive brugt i en organisation. Generelt er brugere sat op over en aktiv mappe og normalt fra det samme netværk eller
Sådan tjekker du for Trusted Platform Module TPM-chip på Windows 10
Microsoft Office er for længst flyttet til en abonnementsbaseret model, men ældre versioner af Office, dvs. Office 2017 (eller ældre) virker stadig, og de
Microsoft Teams er en af mange apps, der har oplevet en støt stigning i antallet af brugere, siden arbejdet er flyttet online for mange mennesker. Appen er et ret robust værktøj til
Sådan installeres Zoom-videokonference-appen på Linux
")
 Google Meet-mikrofon virker ikke, Fra på grund af opkaldets størrelse")
")


-chip på Windows 10")


