Sådan finder du servicemærket på en bærbar Windows 10

Hvis du er på markedet efter en bærbar Windows 10, vil du gå igennem mange og mange forskellige producenter. De samme producenter vil have rigeligt
Vores 10 gotchas fungerer som en tjekliste over potentielle årsager til dine SPSS-statistikker . Nogle spilder bare din tid, men andre kan både spilde din tid og ødelægge din analyse. Denne liste understreger vigtigheden af at undgå disse almindelige problemer, så du effektivt kan bruge SPSS.
Nogle af disse 10 gotchas kan være forvirrende i starten. Andre er ligetil, men nye brugere tillægger dem måske ikke den betydning, de fortjener. Fælles for dem alle er, at uvidenhed om dem kan få dig i varmt vand. Når noget ser ud til at være galt i SPSS, skal du dobbelttjekke denne liste. For at komme ind på denne liste skal disse gotchas have genereret hundredvis af problemer i den virkelige verden, som vi har set i vores kundeinteraktioner.
For mange nye brugere af SPSS virker det at erklære måleniveau som en plage. Du kan roligt ignorere det i et stykke tid, men vores råd er ikke at vente til den dag, hvor det begynder at give problemer. Her er blot et par bemærkelsesværdige situationer, hvor du vil fortryde en beslutning om at udsætte at få dine datasæt sat ordentligt op:
Korrekt metadata er et must for effektiv brug af SPSS. De, der forsøger at spare tid ved at springe over trinnet med at opsætte deres datasæt korrekt, vil aldrig lykkes, fordi de i det lange løb vil spilde tid på at finde ud af, hvorfor SPSS ikke opfører sig, som det skal.
Undgå at bruge strengvariabeltypen. Brug i stedet en kombination af værdier og værdietiketter. Tilbage i 60'erne og 70'erne var RAM og harddiskplads dyre og begrænset. Strenge bruger mange flere tegn og bytes end numeriske, og dengang kunne SPSS ikke udføre beregninger ved at bruge RAM alene, så det var nødvendigt at bruge harddisken, da vi kunne bruge en skrabeblokk. Nu kan det virke underligt at bekymre sig om sådanne ting, men at undgå strenge er stadig kernen i SPSS's designfilosofi.
Så hvilke typer variabler skal gemmes som strenge? Adresser, åbne kommentarer i undersøgelsesdata og navne på personer og virksomheder er gode eksempler på strengvariable. Der er ikke mange flere. Navnene på de 50 stater, navnene på produkter, produktkategorier og SKU'er og de fleste andre nominelle variabler bør sættes op som par af værdier og værdietiketter.
Tidligere udgjorde foranstillede nuller i data såsom postnumre et problem, så dataene ville blive erklæret som strenge. Nu tilføjer den begrænsede numeriske variabeltype imidlertid indledende nuller udfyldt til den maksimale bredde af variablen, så en postnummervariabel ikke længere skal erklæres som en streng. Autorecode gør også konverteringer fra streng til numerisk nem. Hold strengvariabler på et minimum.
Excel-filer tillader ikke metadata, så Excel understøtter ikke værdi- og værdietiketpar. Når du ofte importerer strengdata fra Excel, bør du overveje at lære syntakskommandoer samt autorecode-transformation, fordi disse teknikker kan være nyttige.
For år siden oplevede en SPSS-bruger i en af vores klasser følgende situation. Han havde en skala fra 1 til 10, med 10 som den højeste tilfredshedsvurdering og 1 som den laveste tilfredshedsvurdering. Han havde brug for en kode til at repræsentere "nægtede at svare" og valgte 11. Da han lærte om manglende data i klassen, spekulerede han på, om det ville være okay at lade 11'erne stå i dataene, fordi han allerede havde gennemført analysen, og antallet af afvisninger var ret lavt.
Du satser på, at det forårsagede et stort problem! Det kunne flytte den gennemsnitlige tilfredshed ret langt mod 11, selv med et frafald på 1 til 2 procent. Det slående ved dette eksempel var, at det mest almindelige svar, 1, var meget langt fra den kodede værdi for ikke-svar. Det faktum burde have gjort analysen åbenlyst forkert og let at få øje på. Hvad værre er, er det velforstået i undersøgelsesforskning, at afslag ofte afspejler respondenter, der er meget utilfredse, men tilbageholdende med at dele deres mening. Valget af 11 fik deres mening til at se meget tilfreds ud, ikke meget utilfreds, hvilket forvrængede resultaterne endnu mere.
Desværre glemmer folk at erklære savnet ret ofte, og fejlen fortsætter ofte gennem de sidste trin af analysen og bliver aldrig afsløret. I eksemplet kunne problemet være løst med et enkelt trin: Erklær 11 som brugerdefineret manglende. Vær opmærksom på at angive manglende dataværdier i dine metadata.
Hvad kan gå galt med tilføjelsesmoduler? Det problem, som vi ofte observerer hos kunder, er, at de læser om funktioner i tilføjelsesmoduler og derefter ikke kan finde modulerne. Det kan virke underligt. Ville alle ikke vide, hvilke SPSS-funktioner de ejer? Men du kan også blive forvirret af flere grunde:
SPSS implementerer tilføjelsesmoduler ved at tilføje dem til dine menuer, typisk i hovedmenuen Analyser. I den følgende figur kan du se menuen Analyser fra skærmen for en prøveversion af et SPSS-abonnement. Prøveversionen har altid alle moduler. Så hvis din menu er kortere end den, du ser på billedet, ved du, at du ikke har det fulde supplement af tilføjelsesmoduler.
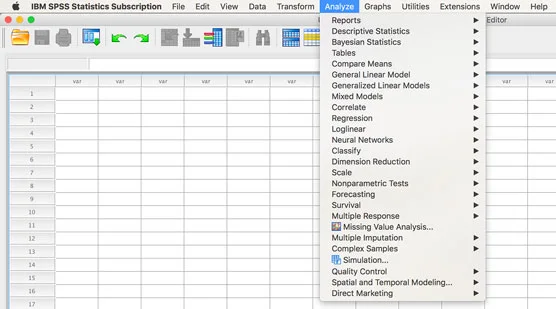
Menuen Analyser med alle tilgængelige moduler.
Der er ikke noget galt med din kopi af SPSS. Du har bare ikke adgang til alle funktioner, inklusive via SPSS Syntax. Nogle mener, at hvis du kender den nødvendige kode og omgår den grafiske brugergrænseflade, kan du køre enhver kommando, men det er ikke sandt. For at køre syntaksen for et tilføjelsesmodul skal du eje modulet. Vi understreger dette, fordi vi har set folk låne Syntax fra en kilde, kollega eller bog og forsøge at kopiere og indsætte koden i Syntax-vinduet. Syntakskoden virker ikke, hvis du mangler den rigtige licens.
En anden almindelig kilde til forvirring er, at mange SPSS-brugere ikke er klar over, at de har adgang til tilføjelsesmoduler på arbejdet eller i skolen. Dette er uheldigt, fordi modulerne kan være yderst nyttige. Vi anbefaler altid Custom Tables-modulet til kunder for større effektivitet i deres analyse. Utallige gange har kunder troet, at de ikke havde nogen moduler, kun for at opdage, at brugerdefinerede tabeller var synlige i menuerne og funktion.

Endelig er "plug-ins" lidt anderledes end tilføjelsesmoduler. Funktioner kan tilføjes til SPSS ved at bruge Python og R. Hvis du er programmør, kan du overveje at udføre denne opgave selv. Mange af disse udvidelser er dog allerede tilgængelige. Det eneste du skal gøre er at downloade dem, og de vises som ekstra menupunkter med et plussymbol ved siden af menupunktet (se margenikonet). Den pensionerede SPSSer Jon Peck var medvirkende til at tilføje denne programmerbarhedsfunktion til SPSS.
SPSS er ikke så smart. SPSS vil gøre, hvad du beder den om at gøre. Så hvis du har en variabel som ægteskabelig status, med værdierne: 1= Gift, 2=Fraskilt, 3=Separeret, 4=Enke og 5=Single, og du beder SPSS om at give dig et gennemsnit for ægteskabelig status, SPSS vil give dig en middelværdi. Et gennemsnit på 2,33 for en nominel variabel som ægteskabelig status er dog ikke nyttig. På samme måde, hvis du analyserer dine data og finder ud af, at 100 % af dine venner, som du har undersøgt, mener, at flere pengeressourcer bør afsættes til tenniscentret i din landsklub, men du kun har interviewet tennisspillere, så kan du ikke udsende dine resultater som et tilfældigt udvalg af country club-medlemmer, og du kan heller ikke blive overrasket over dine resultater.
Det er vigtigt, at du har pålidelige og valide data. SPSS antager, at dine data kommer fra en tilfældig stikprøve; hvis dette ikke er tilfældet, kan du stadig få beskrivende information, men du vil ikke være i stand til at generalisere dine resultater til en population. Du skal også vide, hvilke oplysninger du kan hente fra dine data.
Derudover er det vigtigt at huske, at enhver statistisk test har antagelser. Nogle statistiske test i SPSS, som den uafhængige samples t-test, vurderer automatisk nogle af testantagelserne, dog det meste af tiden; du bliver nødt til at køre yderligere kontroller for at vurdere testantagelser. Husk, at jo bedre du opfylder testantagelserne, jo mere kan du stole på resultaterne af en test.
Du kan høre, at en test er følsom over for brud på antagelser eller robust over for brud på antagelser. Når en test er følsom , skal du være særlig opmærksom på at opfylde antagelserne. Når en test er robust , er der mere slingreplads med antagelserne.
Stort set alle SPSS-brugere starter med at lære SPSS via den grafiske brugergrænseflade, og mange synes, at SPSS Syntax er lidt mystisk. Forvirringen opstår, når en kollega deler lidt syntakskode og tilbyder det som en genvej, men det hele kan se meget skræmmende ud. Frygten er, at du bliver nødt til at have en stor bog åben på dit skrivebord, og at du skriver kommandoerne bogstav for bogstav. Dette er simpelthen ikke sandt.
Selvom en velmenende kollega udbryder "Det er nemt, bare indsæt det", er det måske ikke klart, hvad de mener. "Indsæt" i SPSS, med hensyn til SPSS-syntaks, betyder at lade SPSS-dialogerne generere syntakskoden for dig ved at give instruktionerne via peg og klik. Syntaksen genereres derefter og sendes til syntaksvinduet. Du kan tænke på det som at konvertere klik til kode. Det er ikke kopi- og indsæt-manøvren (Control-C, Control-V i Windows), som vi gør i det meste software.
Næsten alle, der lærer SPSS, bringer forudgående eksponering til Excel til læringsoplevelsen. Der er en kritisk funktion i begge, som håndteres helt forskelligt i de to grænseflader. I Excel, når du vil implementere en formel, arbejder du direkte i en celle i regnearket, og formlen gemmes på samme sted, når du gemmer regnearket. I SPSS skal du bruge dialogboksen Compute Variable (eller tilsvarende i SPSS Syntax), og din formel gemmes ikke i datasættet @@md, kun resultatet gemmes i datasættet.
I første omgang kan det virke meget ønskværdigt for alle at gemme formler i datasættet, men det er måske ikke klart den høje pris, der betales for denne funktion i Excel. SPSS er bygget til at kunne skaleres til store datasæt, nogle gange 100-vis af millioner af rækker af data. I Excel skal regnearket konstant scannes for at opdatere formlers værdier. Denne scanning, passivt og automatisk i baggrunden, bruger ressourcer og gør Excel mindre skalerbar til meget store datasæt. Excel bliver mærkbart trægt, når datasæt er meget store af denne grund, men Excel blev aldrig designet til store datasæt. I SPSS forbliver dataene konstante, medmindre en handling beder om en ændring. For at tvinge beregninger til at opdatere, skal enten menuerne bruges igen, eller SPSS Syntax skal køres igen. Hvert system er designet med dets primære målgruppe i tankerne.
Hvis du er mere fortrolig med, hvordan Excel automatisk opdaterer beregninger, hvordan skal du så vænne dig til SPSS? Hvis de fleste af dine data læses ind fra en fil, og du går direkte til analyse, vil du sandsynligvis være ret tilfreds med at bruge den grafiske brugergrænseflade. Hvis du har meget store filer, eller hvis du har et stort antal beregninger, der er lavet efter at data er læst ind fra en fil, skal du lære SPSS Syntax for at være produktiv. Ved at gemme disse beregninger, måske snesevis eller hundredvis af dem, i form af SPSS Syntax kan du køre dem alle igen ganske nemt.
Excel har i øjeblikket en grænse på 1.000.000 rækker med data, men for blot et par år siden var grænsen meget mindre. Dette er sjældent et problem for Excel-brugere, da mange rækker normalt er tilstrækkelige. Excel-eksperter kan ofte finde en vej rundt om denne grænse, men det er sjældent nødvendigt. Den tekniske årsag til denne grænse er, at hele regnearket skal være tilgængeligt for en computers hukommelse. SPSS kræver ikke, at hele datasættet passer i computerens hukommelse. Dette er vigtigt for mange SPSS-brugere, fordi tusindvis af virksomheder med datasæt større end millionrækkegrænsen skal analysere deres store datasæt i SPSS. IRS er et bemærkelsesværdigt eksempel på en organisation, der bruger SPSS, der har datasæt, der er meget større end grænsen for millionrækker.
Manglende data er ofte blevet behandlet som et emne i kapitellængde (eller endda boglængde), men en diskussion af den længde er ikke mulig i denne artikel. Du kan håndtere manglende data på mange måder, hvoraf den ene er at bruge listevis sletning. Og at være bekendt med udtrykket listevis sletning kan advare dig om, hvad der ellers ville virke som mærkelig adfærd i SPSS. Forestil dig, at du har et stort datasæt med tusindvis af rækker. Men når du kører en multivariat analyse, opfører SPSS sig, som om du slet ikke har nogen data. Du tjekker trinene flere gange, men alt du ser i resultaterne er meddelelser, der indikerer, at du har "ingen gyldige sager." Hvad kunne der ske?
Listemæssig sletning er en metode til at bestemme, hvilke tilfælde i datasættet, der bruges af SPSS til multivariat analyse. Når denne metode anvendes, anvendes kun tilfælde, der er gyldige for alle variabler i analysen. Manglende blot en enkelt celle med oplysninger i sagsrækken vil medføre, at hele sagen bliver fjernet. Hvorfor er dette almindeligt? Forestil dig, at du samler data om flypassagerer. En kolonne registrerer, om en passager valgte at købe et måltid ombord, hvilket kun gælder for buspassagerer. En anden kolonne registrerer, hvilket af to måltidsvalg personen valgte under førsteklasses måltid, som kun gælder førsteklasses passagerer. Hver række i datasættet vil mangle den ene eller den anden, hvilket resulterer i, at nul rækker af data præsenteres for den multivariate analyse. Denne situation er almindelig.
Denne korte diskussion er ikke tilstrækkelig til at afveje fordele og ulemper ved at bruge listevis sletning. Du vil dog nu være opmærksom på det, når du løber ind i problemet med nul tilfælde, der bliver analyseret. Vær også på udkig efter tidspunkter, hvor mange færre sager, end du havde forventet, bliver analyseret. I dialogboksen Indstillinger i dialogboksen Lineær regression er listevis sletning standarden. Pas på ikke at vælge tilfældigt blandt de andre valg, indtil regression virker. Forstå i stedet de andre muligheder, før du prøver dem.
Dine SPSS-færdigheder udvikler sig pænt, og du beslutter dig for, at det er tid til at prøve SPSS Syntax. Du dobbelttjekker dit arbejde, kører syntaksen og støder på advarslen vist her. Du bekræfter, at du har det nødvendige datasæt og den nødvendige variabel. Hvad der er sket?

Advarsel: Nødvendige variabler mangler.
Næsten helt sikkert har du to (eller flere) datasæt åbne, og du har mistet overblikket over, hvilken der er aktiv. Når du arbejder i den grafiske brugergrænseflade, er det praktisk talt umuligt at blive forvirret, for når du åbner menuerne og dialogerne, gør du det generelt fra vinduet Data Editor. Når du bruger SPSS Syntax, kører du dog kode, og der er ingen garanti for, at de nødvendige dataelementer er til stede. Her er, hvad du skal gøre: Kontroller, om du har mere end ét datasæt åbent, og sørg for, at det datasæt, du skal bruge, er det aktive datasæt. Syntaksvinduet har følgende indikator:
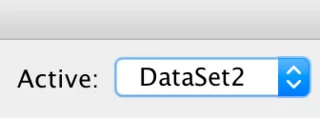
DataSet1 er simpelthen det datasæt, du åbnede først. For at skifte til DataSet2 skal du blot klikke på pilene og vælge det. Du kan også tildele det datasæt, du har brug for, ved at bruge følgende syntaksbit: DATASET ACTIVATE DataSet1.
En almindelig fejl opstår, når du har at gøre med en kommando, der forbliver i kraft, indtil du udtrykkeligt instruerer SPSS om at slå den fra. Tre af disse kommandoer er Select, Split og Weight, som er noget usædvanlige i SPSS, fordi de typisk er forbundet med en midlertidig justering af en analyse, ikke med en permanent ændring af dataene. Vægt er mere teknisk og er oftere forbundet med undersøgelsesanalyse. Her er en hurtig forklaring af hver:
Effektiv brug af alle tre kræver mere end blot en hurtig definition. Det er dog let at kontrollere, om de stadig er tændt, på grund af en indikator i nederste højre hjørne af Data Editor-vinduet. Filterindikatoren henviser til handlinger i dialogboksen Vælg sager. Vægt- og Split-by-indikatorerne henviser til henholdsvis Vægt- og Split-dialogboksene. (Unicode refererer til det kodningssystem, der bruges af SPSS, som typisk ikke er midlertidigt, selvom du kan ændre dette i menuen Rediger → Indstillinger.)

Filter-, Vej- og Split-indikatorerne.
Hvis SPSS opfører sig mærkeligt, og du ikke får de resultater, du forventer, så tjek disse indikatorer. For at slukke for en indikator skal du vende tilbage til dialogboksen, hvor du gav den oprindelige instruktion.
En almindelig fejl er ved et uheld at bruge Select og Split på samme tid. (Power-brugere af SPSS kan gøre dette med vilje, men kun sjældent.) Især er det aldrig en god idé at bruge Select og Split på den samme variabel på samme tid. Hvis du gør det, vises adskillige advarsler i SPSS Output Viewer-vinduet.
Hvis du er på markedet efter en bærbar Windows 10, vil du gå igennem mange og mange forskellige producenter. De samme producenter vil have rigeligt
Hvis du har opdaget, at du bruger Microsoft Teams, men ikke kan få det til at genkende dit webcam, er dette en artikel, du skal læse. I denne guide har vi
En af begrænsningerne ved onlinemøder er båndbredde. Ikke alle onlinemødeværktøjer kan håndtere flere lyd- og/eller videostreams på én gang. Apps skal
Zoom er blevet det populære valg det seneste år, hvor så mange nye mennesker arbejder hjemmefra for første gang. Den er især god, hvis du skal bruge den
Chatapplikationer, der bruges til produktivitet, har brug for en måde at forhindre, at vigtige beskeder går tabt i større, længere samtaler. Kanaler er én
Microsoft Teams er beregnet til at blive brugt i en organisation. Generelt er brugere sat op over en aktiv mappe og normalt fra det samme netværk eller
Sådan tjekker du for Trusted Platform Module TPM-chip på Windows 10
Microsoft Office er for længst flyttet til en abonnementsbaseret model, men ældre versioner af Office, dvs. Office 2017 (eller ældre) virker stadig, og de
Microsoft Teams er en af mange apps, der har oplevet en støt stigning i antallet af brugere, siden arbejdet er flyttet online for mange mennesker. Appen er et ret robust værktøj til
Sådan installeres Zoom-videokonference-appen på Linux
")
 Google Meet-mikrofon virker ikke, Fra på grund af opkaldets størrelse")
")


-chip på Windows 10")


