Sdílení kalendáře v cloudu služeb Salesforce.com

Naučte se, jak efektivně sdílet svůj kalendář na Salesforce.com s uživateli, skupinami a dalšími rolemi pro optimalizaci spolupráce a plánování.
Našich 10 bodů slouží jako kontrolní seznam možných příčin vašich potíží se statistikou SPSS . Někteří jen plýtvají vaším časem, ale jiní mohou plýtvat vaším časem a zničit vaši analýzu. Tento seznam zdůrazňuje důležitost vyhnout se těmto běžným problémům, abyste mohli efektivně používat SPSS.
Některé z těchto 10 gotchů mohou být zpočátku matoucí. Jiné jsou přímočaré, ale noví uživatelé jim nemusí přisuzovat takovou důležitost, jakou si zaslouží. Všechny mají společné to, že jejich neznalost vás může dostat do horké vody. Kdykoli se zdá, že v SPSS není něco v pořádku, zkontrolujte tento seznam. Aby se dostaly na tento seznam, musely tyto šmejdy vygenerovat stovky skutečných problémů, jak jsme byli svědky v našich klientských interakcích.
Mnoha novým uživatelům SPSS připadá deklarování úrovně měření jako nepříjemnost. Můžete to klidně chvíli ignorovat, ale naše rada je nečekat na den, kdy to začne způsobovat problémy. Zde je jen několik pozoruhodných situací, kdy budete litovat rozhodnutí otálet se správným nastavením datových sad:
Správná metadata jsou nutností pro efektivní využití SPSS. Ti, kteří se snaží ušetřit čas přeskočením kroku správného nastavení svých datových sad, nikdy neuspějí, protože budou ztrácet čas v dlouhodobém horizontu snahou zjistit, proč se SPSS nechová tak, jak by měl.
Vyhněte se použití typu proměnné typu řetězec. Místo toho použijte kombinaci hodnot a popisků hodnot. V 60. a 70. letech byly RAM a místo na pevném disku drahé a omezené. Řetězce používají mnohem více znaků a bajtů než číslice a tehdy SPSS nemohl provádět výpočty pouze s RAM, takže potřeboval použít pevný disk, jako bychom mohli používat zápisník. Nyní se může zdát zvláštní dělat si starosti s takovými věcmi, ale vyhýbání se řetězcům je stále jádrem filozofie designu SPSS.
Jaké druhy proměnných by tedy měly být uloženy jako řetězce? Dobrými příklady řetězcových proměnných jsou adresy, otevřené komentáře v datech průzkumu a jména lidí a společností. Více jich není. Názvy 50 stavů, názvy produktů, kategorie produktů a SKU a většina dalších nominálních proměnných by měly být nastaveny jako dvojice hodnot a hodnotových štítků.
V minulosti představovaly úvodní nuly v datech, jako jsou PSČ, problém, takže data byla deklarována jako řetězec. Nyní však omezený typ číselné proměnné přidává úvodní nuly doplněné do maximální šířky proměnné, takže proměnná PSČ již nemusí být deklarována jako řetězec. Autorecode také usnadňuje převody z řetězců na čísla. Udržujte proměnné řetězce na minimu.
Soubory Excel neumožňují metadata, takže Excel nepodporuje dvojice hodnot a hodnotových štítků. Při častém importu řetězcových dat z Excelu zvažte naučení se příkazů syntaxe a také transformace automatického kódování, protože tyto techniky mohou být užitečné.
Před lety zažil uživatel SPSS v jedné z našich tříd následující situaci. Měl stupnici od 1 do 10, přičemž 10 jako nejvyšší hodnocení spokojenosti a 1 jako nejnižší hodnocení spokojenosti. Potřeboval kód, který by představoval „odmítl odpovědět“, a vybral si 11. Když se dozvěděl o chybějících údajích ve třídě, přemýšlel, zda by bylo v pořádku nechat v datech pouze 11, protože již dokončil analýzu a počet odmítnutí byl poměrně nízké.
Vsadíte se, že to způsobilo velký problém! Mohlo by to posunout průměrnou spokojenost docela daleko k 11 i při 1 až 2 procentech neodpovědi. Na tomto příkladu bylo zarážející, že nejběžnější odpověď, 1, byla velmi vzdálená od kódované hodnoty pro neodpovědi. Tato skutečnost měla způsobit, že analýza byla zjevně špatná a snadno zjistitelná. Ještě horší je, že v průzkumu je dobře známo, že odmítnutí často odrážejí respondenty, kteří jsou velmi nespokojení, ale zdráhají se sdílet svůj názor. Výběr 11 způsobil, že jejich názor vypadal velmi spokojeně, nikoli velmi nespokojeně, což ještě více zkreslilo výsledky.
Je smutné, že lidé poměrně často zapomínají prohlásit za chybějící a chyba často přetrvává i v posledních krocích analýzy a nikdy není odhalena. V příkladu mohl být problém vyřešen jedním jednoduchým krokem: deklarovat 11 jako uživatelem definované chybí. Buďte opatrní při deklarování chybějících datových hodnot ve vašich metadatech.
Co se může pokazit na přídavných modulech? Problém, který u klientů často pozorujeme, je ten, že čtou o funkcích v přídavných modulech a pak nemohou moduly najít. To se může zdát divné. Copak by každý nevěděl, které funkce SPSS vlastní? Ale i vy můžete být zmateni z několika důvodů:
SPSS implementuje přídavné moduly tak, že je přidá do vašich nabídek, obvykle v hlavní nabídce Analyzovat. Na následujícím obrázku můžete vidět nabídku Analyzovat z obrazovky zkušební verze SPSS Subscription. Zkušební verze má vždy všechny moduly. Pokud je tedy vaše menu kratší než to, které vidíte na obrázku, víte, že nemáte plný počet přídavných modulů.
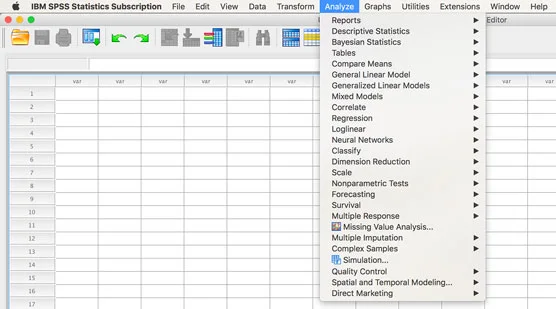
Nabídka Analyzovat se všemi dostupnými moduly.
S vaší kopií SPSS není nic špatného. Jen nemáte přístup ke všem funkcím, včetně syntaxe SPSS. Někteří věří, že pokud znáte potřebný kód a obejdete grafické uživatelské rozhraní, můžete spustit jakýkoli příkaz, ale to není pravda. Chcete-li spustit syntaxi přídavného modulu, musíte modul vlastnit. Tento bod zdůrazňujeme, protože jsme viděli, jak si lidé půjčují syntaxi od zdroje, kolegy nebo knihy a pokoušejí se zkopírovat a vložit kód do okna Syntaxe. Syntaktický kód nebude fungovat, pokud vám chybí správná licence.
Dalším častým zdrojem zmatků je, že mnoho uživatelů SPSS si neuvědomuje, že mají přístup k přídavným modulům v práci nebo ve škole. To je nešťastné, protože moduly mohou být velmi užitečné. Klientům vždy doporučujeme modul Vlastní tabulky pro větší efektivitu při jejich analýze. Nesčetněkrát si klienti mysleli, že nemají žádné moduly, jen aby zjistili, že vlastní tabulky jsou viditelné v nabídkách a fungují.

A konečně, „pluginy“ jsou trochu jiné než přídavné moduly. Funkce mohou být přidány do SPSS pomocí Pythonu a R. Pokud jste programátor, můžete zvážit provedení tohoto úkolu sami. Mnoho z těchto rozšíření je však již k dispozici. Stačí si je stáhnout a zobrazí se jako další položky nabídky se symbolem plus vedle položky nabídky (viz ikona okraje). Vysloužilý SPSSer Jon Peck byl nápomocný při přidávání této programovatelné funkce do SPSS.
SPSS není tak chytrý. SPSS udělá vše, o co ho požádáte. Pokud tedy máte proměnnou jako Rodinný stav, s hodnotami: 1= Ženatý, 2=Rozvedený, 3=Odloučený, 4=Vdova a 5=Svobodný, a požádáte SPSS, aby vám poskytla průměr pro Rodinný stav, SPSS vám dá prostředek. Průměr 2,33 pro nominální proměnnou, jako je rodinný stav, však není užitečný. Podobně, pokud analyzujete svá data a zjistíte, že 100 % vašich přátel, které jste provedli v průzkumu, si myslí, že by se více finančních prostředků mělo věnovat tenisovému centru ve vašem venkovském klubu, ale vy jste dělali rozhovory pouze s tenisty, pak nemůžete své výsledky vydávat za náhodný vzorek členů country klubu, ani se nemůžete svým zjištěním divit.
Je důležité, abyste měli spolehlivá a platná data. SPSS předpokládá, že vaše data pocházejí z náhodného vzorku; pokud tomu tak není, stále můžete získat popisné informace, ale nebudete moci zobecnit své výsledky na populaci. Budete také potřebovat vědět, jaké informace můžete ze svých dat získat.
Kromě toho je důležité mít na paměti, že každý statistický test má určité předpoklady. Některé statistické testy v SPSS, jako je t-test nezávislých vzorků, automaticky vyhodnocují některé předpoklady testu, většinou však; budete muset provést další kontroly k posouzení předpokladů testu. Pamatujte, že čím lépe splníte předpoklady testu, tím více můžete důvěřovat výsledkům testu.
Můžete slyšet, že test je citlivý na porušení předpokladů nebo odolný vůči porušení předpokladů. Když je test citlivý , musíte být obzvláště opatrní, abyste splnili předpoklady. Když je test robustní , existuje větší prostor pro kolísání s předpoklady.
Prakticky všichni uživatelé SPSS začínají učením SPSS přes grafické uživatelské rozhraní a mnozí považují syntaxi SPSS za trochu tajemnou. Zmatek nastává, když kolega sdílí trochu syntaktického kódu a nabízí jej jako zkratku, ale vše může vypadat velmi zastrašující. Obáváte se, že budete muset mít na stole otevřenou velkou knihu a že budete psát příkazy písmeno po písmenu. To prostě není pravda.
I když kolega, který to myslí dobře, zvolá „Je to snadné, stačí to vložit“, nemusí být jasné, co tím myslí. „Vkládání“ v SPSS, pokud jde o SPSS Syntax, znamená nechat dialogy SPSS generovat syntaktický kód za vás tím, že zadáte pokyny přes point and click. Poté je vygenerována syntaxe a odeslána do okna syntaxe. Můžete si to představit jako převod kliknutí na kód. Ve většině softwaru to není manévr kopírování a vkládání (Control-C, Control-V ve Windows).
Téměř každý, kdo se učí SPSS, přináší předchozí zkušenost s Excelem. V obou je kritická funkce, která je v obou rozhraních řešena zcela odlišně. V Excelu, když chcete implementovat vzorec, pracujete přímo v buňce tabulky a vzorec se uloží na stejné místo, když tabulku uložíte. V SPSS musíte použít dialog Compute Variable (nebo ekvivalent v SPSS Syntaxi) a váš vzorec se neuloží do datové sady @@md, do datové sady se uloží pouze výsledek.
Zpočátku se může zdát velmi žádoucí, aby každý ukládal vzorce do datové sady, ale nemusí být jasné, jak vysoká cena je za tuto funkci v Excelu zaplacena. SPSS je navržen tak, aby byl škálovatelný na velké datové sady, někdy 100 s miliony řádků dat. V Excelu se musí tabulka neustále skenovat, aby se aktualizovaly hodnoty vzorců. Toto skenování, pasivně a automaticky na pozadí, spotřebovává zdroje a činí Excel méně škálovatelný na velmi velké datové sady. Excel se stává znatelně pomalým, když jsou datové sady z tohoto důvodu velmi velké, ale Excel nikdy nebyl navržen pro velké datové sady. V SPSS zůstávají data konstantní, pokud akce nevyzve ke změně. Chcete-li vynutit aktualizaci výpočtů, musíte znovu použít nabídky nebo znovu spustit syntaxi SPSS. Každý systém je navržen s ohledem na své primární publikum.
Pokud jste více obeznámeni s tím, jak Excel automaticky aktualizuje výpočty, jak byste se měli aklimatizovat na SPSS? Pokud je většina vašich dat načtena ze souboru a přejdete přímo k analýze, pravděpodobně budete s používáním grafického uživatelského rozhraní docela spokojeni. Pokud máte velmi velké soubory nebo pokud máte velký počet výpočtů, které se provádějí po načtení dat ze souboru, budete se muset naučit syntaxi SPSS, abyste byli produktivní. Uložením těchto výpočtů, možná desítek nebo stovek z nich, ve formě syntaxe SPSS je můžete všechny poměrně snadno znovu spustit.
Excel má aktuálně limit 1 000 000 řádků dat, ale ještě před pár lety byl limit mnohem menší. To je zřídka problém pro uživatele aplikace Excel, protože tolik řádků je obvykle dostačujících. Odborníci na Excel často dokážou najít způsob, jak tento limit obejít, ale jen zřídka je to nutné. Technickým důvodem tohoto omezení je, že celá tabulka musí být přístupná paměti počítače. SPSS nevyžaduje, aby se celá datová sada vešla do paměti počítače. To je důležité pro mnoho uživatelů SPSS, protože tisíce společností s datovými sadami většími než milion řádků potřebují analyzovat své velké datové sady v SPSS. IRS je pozoruhodným příkladem organizace, která používá SPSS, která má datové sady mnohem větší, než je limit milionu řádků.
Chybějící data byla často považována za téma dlouhé kapitoly (nebo dokonce knihy), ale diskuse o této délce není v tomto článku možná. Chybějící data můžete řešit mnoha způsoby, jedním z nich je použití seznamového mazání. A znalost termínu listwise deletion vás může upozornit na to, co by jinak vypadalo jako podivné chování v SPSS. Představte si, že máte velkou datovou sadu s tisíci řádky. Ale když spustíte multivariační analýzu, SPSS se chová, jako byste neměli vůbec žádná data. Kroky kontrolujete několikrát, ale ve výsledcích vidíte pouze zprávy, které naznačují, že nemáte „žádné platné případy“. Co by se mohlo stát?
Listwise delece je jednou z metod pro určení, které případy v datové sadě používá SPSS pro multivariační analýzu. Při použití této metody se použijí pouze případy, které jsou platné pro všechny proměnné v analýze. Chybějící pouze jedna buňka informací v řádku případu způsobí odstranění celého případu. Proč je to běžné? Představte si, že shromažďujete data o cestujících v letecké společnosti. Jeden sloupec zaznamenává, zda se cestující rozhodl zakoupit palubní jídlo, což platí pouze pro cestující autokarem. Další sloupec zaznamenává, které ze dvou jídel si osoba zvolila během jídla první třídy, což platí pouze pro cestující první třídy. Na každém řádku v datové sadě bude jeden nebo druhý chybět, což povede k tomu, že do analýzy s více proměnnými bude předloženo nula řádků dat. Tato situace je běžná.
Tato krátká diskuse nestačí ke zvážení pro a proti používání seznamového mazání. Nyní si to však uvědomíte, když narazíte na problém s nulovým počtem analyzovaných případů. Buďte také ve střehu, kdy se analyzuje mnohem méně případů, než jste očekávali. V dialogu Možnosti dialogu Lineární regrese je výchozím nastavením mazání po seznamu. Dávejte pozor, abyste si náhodně nevybírali mezi ostatními možnostmi, dokud regrese nefunguje. Místo toho pochopte ostatní možnosti, než je vyzkoušíte.
Vaše SPSS dovednosti se pěkně rozvíjejí a vy se rozhodnete, že je čas vyzkoušet SPSS Syntax. Znovu zkontrolujete svou práci, spustíte syntaxi a narazíte na zde zobrazené varování. Potvrzujete, že máte potřebnou datovou sadu a potřebnou proměnnou. Co se stalo?

Upozornění: Chybí potřebné proměnné.
Téměř jistě máte otevřené dvě (nebo více) datových sad a ztratili jste přehled o tom, která z nich je aktivní. Když pracujete v grafickém uživatelském rozhraní, je prakticky nemožné se zmást, protože když přistupujete k nabídkám a dialogům, obvykle tak činíte z okna Editoru dat. Když však používáte syntaxi SPSS, spouštíte kód a neexistuje žádná záruka, že jsou přítomny potřebné datové prvky. Zde je to, co musíte udělat: Zkontrolujte, zda nemáte otevřenou více než jednu datovou sadu, a ujistěte se, že datová sada, kterou potřebujete, je aktivní datová sada. Okno syntaxe má následující indikátor:
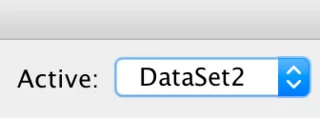
DataSet1 je jednoduše datová sada, kterou jste otevřeli jako první. Chcete-li přepnout na DataSet2, jednoduše klikněte na šipky a vyberte ji. Potřebnou datovou sadu můžete přiřadit také pomocí následujícího bitu syntaxe: DATASET ACTIVATE DataSet1.
Častá chyba nastává, když máte co do činění s příkazem, který zůstává v platnosti, dokud výslovně nedáte pokyn SPSS, aby jej vypnul. Tři z těchto příkazů jsou Select, Split a Weight, které jsou v SPSS poněkud neobvyklé, protože jsou obvykle spojeny s dočasnou úpravou analýzy, nikoli s trvalou změnou dat. Váha je techničtější a je častěji spojována s analýzou průzkumu. Zde je rychlé vysvětlení každého:
Efektivní použití všech tří vyžaduje více než jen rychlou definici. Kontrola, zda jsou stále zapnuté, je však snadná díky indikátoru v pravém dolním rohu okna Editor dat. Indikátor filtru odkazuje na operace v dialogu Vybrat případy. Indikátory Váha a Rozdělit podle odkazují na dialogy Váha a Rozdělit. (Unicode označuje kódovací systém používaný SPSS, který obvykle není dočasný, i když to můžete změnit v nabídce Úpravy→Možnosti.)

Indikátory Filter, Weigh a Split.
Pokud se SPSS chová divně a nedosahujete očekávaných výsledků, zkontrolujte tyto indikátory. Chcete-li indikátor vypnout, vraťte se do dialogu, kde jste zadali původní pokyn.
Častou chybou je náhodné použití výběru a rozdělení současně. (Pokročilí uživatelé SPSS to mohou dělat záměrně, ale jen výjimečně.) Zejména není nikdy dobrý nápad používat Select a Split na stejné proměnné současně. Pokud tak učiníte, v okně SPSS Output Viewer se objeví četná varování.
Naučte se, jak efektivně sdílet svůj kalendář na Salesforce.com s uživateli, skupinami a dalšími rolemi pro optimalizaci spolupráce a plánování.
DocuSign je cloudový software umožňující digitální podepisování dokumentů, dostupný pro různé platformy jako Windows, iOS a Android.
Ak hľadáte prenosný počítač so systémom Windows 10, prejdete mnohými a mnohými rôznymi výrobcami. Tí istí výrobcovia budú mať veľa
Ak ste zistili, že používate Microsoft Teams, ale nedokážete rozpoznať vašu webovú kameru, toto je článok, ktorý si musíte prečítať. V tejto príručke sme
Jedným z obmedzení online stretnutí je šírka pásma. Nie každý online nástroj na schôdze dokáže spracovať viacero audio a/alebo video streamov naraz. Aplikácie musia
Zoom sa minulý rok stal populárnou voľbou, pretože toľko nových ľudí po prvýkrát pracuje z domu. Je to obzvlášť skvelé, ak musíte použiť
Chatovacie aplikácie, ktoré sa používajú na zvýšenie produktivity, potrebujú spôsob, ako zabrániť strate dôležitých správ vo väčších a dlhších konverzáciách. Kanály sú jeden
Microsoft Teams je určený na použitie v rámci organizácie. Vo všeobecnosti sú používatelia nastavení cez aktívny adresár a normálne z rovnakej siete resp
Jak zkontrolovat čip Trusted Platform Module TPM v systému Windows 10
Microsoft Office už dávno prešiel na model založený na predplatnom, avšak staršie verzie Office, tj Office 2017 (alebo staršie), stále fungujú a


")
 Mikrofón Google Meet nefunguje, „vypnutý z dôvodu veľkosti hovoru“")
")


 v systému Windows 10")
