Si të krijoni një grup përdoruesish Slack

Slack është një mjet i shkëlqyer bashkëpunimi. Gati për të krijuar një grup përdoruesish? Ky udhëzues ju udhëzon gjatë procesit për këtë veçori të planit premium.
10 gocat tona shërbejnë si një listë kontrolli e shkaqeve të mundshme të problemeve tuaja të Statistikave SPSS . Disa thjesht humbasin kohën tuaj, por të tjerët mund të humbasin kohën tuaj dhe të prishin analizën tuaj. Kjo listë përforcon rëndësinë e shmangies së këtyre çështjeve të zakonshme në mënyrë që të mund të përdorni me efikasitet SPSS.
Disa nga këto 10 goca mund të jenë konfuze në fillim. Të tjerët janë të drejtpërdrejtë, por përdoruesit e rinj mund të mos u atribuojnë atyre rëndësinë që meritojnë. E përbashkëta e të gjithëve është se injoranca ndaj tyre mund t'ju çojë në ujë të nxehtë. Sa herë që diçka duket se nuk shkon në SPSS, kontrolloni dy herë këtë listë. Për të fituar rrugën e saj në këtë listë, këto goca duhet të kenë krijuar qindra probleme të botës reale siç dëshmojmë nga ne në ndërveprimet me klientët tanë.
Për shumë përdorues të rinj të SPSS, deklarimi i Nivelit të Matjes duket si një bezdi. Mund ta shpërfillni me siguri për një kohë, por këshilla jonë është të mos prisni ditën që të fillojë të shkaktojë probleme. Këtu janë vetëm disa situata të rëndësishme ku do të pendoheni për një vendim për të zvarritur vendosjen e duhur të grupeve të të dhënave tuaja:
Meta të dhënat e duhura janë një domosdoshmëri për përdorimin efikas të SPSS. Ata që përpiqen të kursejnë kohë duke anashkaluar hapin e konfigurimit të duhur të grupeve të të dhënave të tyre nuk do të kenë kurrë sukses sepse do të humbasin kohë në planin afatgjatë duke u përpjekur të kuptojnë pse SPSS nuk po sillet siç duhet.
Shmangni përdorimin e llojit të ndryshores së vargut. Në vend të kësaj, përdorni një kombinim vlerash dhe etiketash vlerash. Në vitet '60 dhe '70, RAM-i dhe hapësira e diskut ishin të shtrenjta dhe të kufizuara. Vargjet përdorin shumë më tepër karaktere dhe bajt sesa numerikë, dhe në atë kohë SPSS nuk mund të kryente llogaritjet duke përdorur vetëm RAM, kështu që duhej të përdorte hard diskun pasi mund të përdornim një bllok gërvishtjeje. Tani, mund të duket e çuditshme të shqetësohesh për gjëra të tilla, por shmangia e vargjeve është ende thelbësore për filozofinë e dizajnit të SPSS.
Pra, çfarë lloj variablash duhet të ruhen si vargje? Adresat, komentet e hapura në të dhënat e sondazhit dhe emrat e njerëzve dhe kompanive janë shembuj të mirë të variablave të vargut. Nuk ka shumë më tepër. Emrat e 50 shteteve, emrat e produkteve, kategoritë e produkteve dhe SKU, dhe shumica e variablave të tjerë nominalë duhet të vendosen si çifte vlerash dhe etiketash vlerash.
Në të kaluarën, zerat kryesore në të dhëna si kodet postare përbënin një problem, kështu që të dhënat do të deklaroheshin si varg. Tani, megjithatë, lloji i variablit numerik të kufizuar shton zerat kryesore të mbushura në gjerësinë maksimale të ndryshores, kështu që një variabël kodi postar nuk duhet më të deklarohet si varg. Gjithashtu, Autorecode e bën të lehtë konvertimin nga vargu në numerik. Mbani variablat e vargut në minimum.
Skedarët e Excel nuk lejojnë meta të dhëna, kështu që Excel nuk mbështet çiftet e etiketës së vlerës dhe vlerës. Kur importoni shpesh të dhëna të vargjeve nga Excel, merrni parasysh të mësoni komandat e sintaksës si dhe transformimin e kodifikimit automatik sepse këto teknika mund të jenë të dobishme.
Vite më parë, një përdorues i SPSS në një nga klasat tona përjetoi situatën e mëposhtme. Ai kishte një shkallë nga 1 deri në 10, me 10 si vlerësimin më të lartë të kënaqësisë dhe 1 si vlerësimin më të ulët të kënaqësisë. Atij i duhej një kod për të përfaqësuar "refuzoi të përgjigjej" dhe zgjodhi 11. Kur mësoi për të dhënat që mungojnë në klasë, ai mendoi nëse vetëm lënia e 11-ve në të dhëna do të ishte në rregull sepse ai kishte përfunduar tashmë analizën dhe numri i refuzimeve ishte mjaft e ulët.
Vë bast se shkaktoi një problem të madh! Mund ta çojë kënaqësinë mesatare shumë larg në 11, edhe me një mospërgjigje prej 1 deri në 2 për qind. Ajo që ishte e habitshme në këtë shembull ishte se përgjigja më e zakonshme, 1, ishte shumë larg nga vlera e koduar për mospërgjigje. Ky fakt duhet ta kishte bërë analizën dukshëm të gabuar dhe të lehtë për t'u dalluar. Më keq, në hulumtimet e anketave kuptohet mirë se refuzimet shpesh pasqyrojnë të anketuarit që janë shumë të pakënaqur, por hezitojnë të ndajnë mendimin e tyre. Zgjedhja e 11 e bëri opinionin e tyre të dukej shumë i kënaqur, jo shumë i pakënaqur, duke shtrembëruar edhe më shumë rezultatet.
Mjerisht, njerëzit harrojnë të deklarojnë të humbur mjaft shpesh, dhe gabimi shpesh vazhdon gjatë hapave përfundimtarë të analizës dhe nuk zbulohet kurrë. Në shembull, problemi mund të ishte rregulluar me një hap të thjeshtë: Deklaroni 11 si të humbur të përcaktuar nga përdoruesi. Jini vigjilentë në lidhje me deklarimin e vlerave të të dhënave që mungojnë në të dhënat tuaja meta.
Çfarë mund të shkojë keq me modulet shtesë? Problemi që vërejmë shpesh me klientët është se ata lexojnë për veçoritë në modulet shtesë dhe më pas nuk mund t'i gjejnë modulet. Kjo mund të duket e çuditshme. A nuk do ta dinin të gjithë se cilat funksione SPSS zotërojnë? Por edhe ju mund të jeni të hutuar për disa arsye:
SPSS implementon module shtesë duke i shtuar ato në menutë tuaja, zakonisht në menynë kryesore Analyze. Në figurën e mëposhtme, mund të shihni menynë Analize nga ekrani i një prove të Abonimit SPSS. Versioni i provës ka gjithmonë të gjitha modulet. Pra, nëse menyja juaj është më e shkurtër se ajo që shihni në imazh, ju e dini që nuk keni plotësimin e plotë të moduleve shtesë.
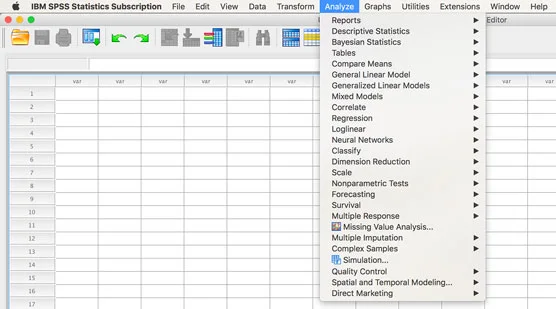
Menuja Analiza me të gjitha modulet e disponueshme.
Asgjë nuk është e gabuar me kopjen tuaj të SPSS. Thjesht nuk keni akses në të gjitha veçoritë, duke përfshirë përmes Sintaksës SPSS. Disa besojnë se nëse e dini kodin e nevojshëm dhe anashkaloni ndërfaqen grafike të përdoruesit, mund të ekzekutoni çdo komandë, por kjo nuk është e vërtetë. Për të ekzekutuar sintaksën për një modul shtesë, duhet të zotëroni modulin. Ne e theksojmë këtë pikë sepse kemi parë njerëz që huazojnë Sintaksë nga një burim, koleg ose libër dhe përpiqen të kopjojnë dhe ngjisin kodin në dritaren e Sintaksës. Kodi sintaksor nuk do të funksionojë nëse ju mungon licencimi i duhur.
Një burim tjetër i zakonshëm i konfuzionit është se shumë përdorues të SPSS nuk e kuptojnë se kanë akses në modulet shtesë në punë ose në shkollë. Kjo është për të ardhur keq, sepse modulet mund të jenë jashtëzakonisht të dobishme. Ne i rekomandojmë gjithmonë klientëve modulin Tabelat e personalizuara për efikasitet më të madh në analizën e tyre. Herë të panumërta, klientët kanë menduar se nuk kishin module vetëm për të zbuluar se Tabelat e personalizuara ishin të dukshme në meny dhe funksiononin.

Së fundi, "shtojcat" janë pak më ndryshe nga modulet shtesë. Veçoritë mund të shtohen në SPSS duke përdorur Python dhe R. Nëse jeni programues, mund ta konsideroni ta bëni vetë këtë detyrë. Megjithatë, shumë nga këto shtesa janë tashmë të disponueshme. Gjithçka që duhet të bëni është t'i shkarkoni ato dhe ato do të shfaqen si elementë shtesë të menysë, me një simbol plus pranë hyrjes së menysë (shih ikonën e margjinës). SPSSer në pension Jon Peck ishte i rëndësishëm në shtimin e kësaj veçorie programueshmërie në SPSS.
SPSS nuk është aq i zgjuar. SPSS do të bëjë gjithçka që ju kërkoni. Pra, nëse keni një variabël si Statusi Martesor, me vlerat: 1= I martuar, 2=I divorcuar, 3=I ndarë, 4=I ve dhe 5=Beqar, dhe ju kërkoni nga SPSS që t'ju japë një mesatare për statusin martesor, SPSS do t'ju japë një mjet. Megjithatë, një mesatare prej 2.33 për një ndryshore nominale si Statusi Martesor nuk është i dobishëm. Në mënyrë të ngjashme, nëse analizoni të dhënat tuaja dhe zbuloni se 100% e miqve tuaj që keni anketuar mendojnë se më shumë burime monetare duhet t'i kushtohen qendrës së tenisit në klubin tuaj të vendit, por ju keni intervistuar vetëm lojtarët e tenisit, atëherë nuk mund t'i kaloni rezultatet tuaja si një kampion i rastësishëm i anëtarëve të klubit të vendit dhe as nuk mund të habiteni me gjetjet tuaja.
Është e rëndësishme që të keni të dhëna të besueshme dhe të vlefshme. SPSS supozon se të dhënat tuaja vijnë nga një mostër e rastësishme; nëse nuk është kështu, ju mund të merrni ende informacion përshkrues, megjithatë nuk do të jeni në gjendje t'i përgjithësoni rezultatet tuaja në një popullsi. Ju gjithashtu do të duhet të dini se çfarë informacioni mund të grumbulloni nga të dhënat tuaja.
Për më tepër, është e rëndësishme të mbani mend se çdo test statistikor ka supozime. Disa teste statistikore në SPSS, si testi i mostrave të pavarura t-test, vlerësojnë automatikisht disa nga supozimet e testit, megjithatë shumicën e kohës; do t'ju duhet të kryeni kontrolle shtesë për të vlerësuar supozimet e testit. Mos harroni se sa më mirë të përmbushni supozimet e testit, aq më shumë mund t'i besoni rezultatet e një testi.
Ju mund të dëgjoni se një test është i ndjeshëm ndaj shkeljeve të supozimeve ose i fortë ndaj shkeljeve të supozimeve. Kur një test është i ndjeshëm , duhet të jeni veçanërisht të kujdesshëm për të përmbushur supozimet. Kur një test është i fortë , ka më shumë hapësirë për të lëvizur me supozimet.
Pothuajse të gjithë përdoruesit e SPSS-it fillojnë duke mësuar SPSS nëpërmjet Ndërfaqes Grafike të Përdoruesit dhe shumë e shohin Sintaksa SPSS si pak të fshehtë. Konfuzioni lind kur një koleg ndan pak kod sintaksor dhe e ofron atë si një shkurtore, por e gjithë kjo mund të duket shumë frikësuese. Frika është se do t'ju duhet të keni një libër të madh të hapur në tryezën tuaj dhe se do të shkruani komandat shkronja për shkronjë. Kjo thjesht nuk është e vërtetë.
Edhe nëse një koleg me qëllime të mira thërret "Është e lehtë, thjesht ngjiteni", mund të mos jetë e qartë se çfarë nënkuptojnë. “Ngjitja” në SPSS, në lidhje me Sintaksën SPSS, do të thotë të lini dialogët SPSS të gjenerojnë kodin sintaksor për ju duke dhënë udhëzimet me pikë dhe klikoni. Më pas, sintaksa gjenerohet dhe dërgohet në dritaren e sintaksës. Mund ta mendoni si konvertimin e klikimeve në kod. Nuk është manovra e kopjimit, ngjitjes (Control-C, Control-V në Windows) që bëjmë në shumicën e softuerëve.
Pothuajse të gjithë ata që mësojnë SPSS sjellin ekspozim paraprak në Excel për përvojën e të mësuarit. Ekziston një funksion kritik në të dyja, i cili trajtohet krejt ndryshe në të dy ndërfaqet. Në Excel, kur dëshironi të zbatoni një formulë, ju punoni drejtpërdrejt në një qelizë të fletëllogaritjes dhe formula ruhet në të njëjtin vend kur ruani tabelën. Në SPSS, duhet të përdorni dialogun Compute Variable (ose ekuivalentin në Sintaksën SPSS) dhe formula juaj nuk ruhet në grupin e të dhënave @@md vetëm rezultati ruhet në grupin e të dhënave.
Në fillim, mund të duket shumë e dëshirueshme që të gjithë të ruajnë formula në grupin e të dhënave, por mund të mos jetë e qartë çmimi i lartë që paguhet për këtë veçori në Excel. SPSS është ndërtuar që të jetë i shkallëzueshëm në grupe të dhënash të mëdha, ndonjëherë 100 dhjetëra miliona rreshta të dhënash. Në Excel, spreadsheet duhet të skanohen vazhdimisht për të përditësuar vlerat e formulave. Ky skanim, pasiv dhe automatikisht në sfond, konsumon burime dhe e bën Excel më pak të shkallëzueshëm në grupe të dhënash shumë të mëdha. Excel bëhet dukshëm i ngadaltë kur grupet e të dhënave janë shumë të mëdha për këtë arsye, por Excel nuk ishte krijuar kurrë për grupe të mëdha të dhënash. Në SPSS, të dhënat mbeten konstante nëse një veprim nuk kërkon një ndryshim. Për të detyruar llogaritjet të përditësohen, ose duhet të përdoren përsëri menutë ose duhet të ekzekutohet përsëri Sintaksa SPSS. Çdo sistem është projektuar duke pasur parasysh audiencën e tij kryesore.
Nëse jeni më të njohur me mënyrën se si Excel përditëson automatikisht llogaritjet, si duhet të përshtateni me SPSS? Nëse shumica e të dhënave tuaja lexohen nga një skedar dhe ju vazhdoni drejtpërdrejt në analizë, atëherë ndoshta do të jeni mjaft të kënaqur duke përdorur Ndërfaqen Grafike të Përdoruesit. Nëse keni skedarë shumë të mëdhenj ose nëse keni një numër të madh llogaritjesh që bëhen pasi të dhënat të lexohen nga një skedar, do t'ju duhet të mësoni sintaksën SPSS për të qenë produktiv. Duke i ruajtur ato përllogaritje, ndoshta dhjetëra ose qindra prej tyre, në formën e Sintaksës SPSS, mund t'i përsëritni të gjitha shumë lehtë.
Excel aktualisht ka një kufi prej 1,000,000 rreshtash të dhënash, por vetëm pak vite më parë kufiri ishte shumë më i vogël. Ky është një problem i rrallë për përdoruesit e Excel pasi që shumë rreshta zakonisht janë të mjaftueshëm. Ekspertët e Excel shpesh mund të gjejnë një mënyrë për ta kapërcyer këtë kufi, por rrallëherë është e nevojshme. Arsyeja teknike për këtë kufi është se e gjithë fletëllogaritja duhet të jetë e aksesueshme për memorien e kompjuterit. SPSS nuk kërkon që i gjithë grupi i të dhënave të futet në kujtesën e kompjuterit. Kjo është e rëndësishme për shumë përdorues të SPSS sepse mijëra kompani me grupe të dhënash më të mëdha se kufiri i milionave duhet të analizojnë grupet e tyre të mëdha të të dhënave në SPSS. IRS është një shembull i dukshëm i një organizate që përdor SPSS që ka grupe të dhënash shumë më të mëdha se kufiri i milionave.
Të dhënat që mungojnë shpesh janë trajtuar si një temë e gjatësisë së kapitullit (apo edhe e gjatësisë së librit), por një diskutim i asaj gjatësie nuk është i mundur në këtë artikull. Ju mund të trajtoni të dhënat që mungojnë në shumë mënyra, njëra prej të cilave është përdorimi i fshirjes në listë. Dhe njohja me termin fshirje në listë mund t'ju paralajmërojë për atë që përndryshe do të dukej si sjellje e çuditshme në SPSS. Imagjinoni që keni një grup të madh të dhënash, me mijëra rreshta. Por kur kryeni një analizë multivariate, SPSS sillet sikur nuk keni fare të dhëna. Ju i kontrolloni hapat disa herë, por gjithçka që shihni në rezultate janë mesazhe që tregojnë se nuk keni "asnjë rast të vlefshëm". Çfarë mund të ndodhë?
Fshirja sipas listës është një metodë për të përcaktuar se cilat raste në grupin e të dhënave përdoren nga SPSS për analiza shumëvariate. Kur aplikohet kjo metodë, përdoren vetëm rastet që janë të vlefshme për të gjitha variablat në analizë. Mungesa e vetëm një qelize të vetme informacioni në rreshtin e rastit do të bëjë që i gjithë rasti të hiqet. Pse është kjo e zakonshme? Imagjinoni që po grumbulloni të dhëna për pasagjerët e linjës ajrore. Një kolonë regjistron nëse një pasagjer ka zgjedhur të blejë një vakt gjatë fluturimit, i cili vlen vetëm për pasagjerët e autobusit. Një kolonë tjetër regjistron se cilën nga dy zgjedhjet e vakteve ka zgjedhur personi gjatë vaktit të klasit të parë, gjë që vlen vetëm për pasagjerët e klasit të parë. Çdo rreshti në grupin e të dhënave do t'i mungojë njëra ose tjetra, duke rezultuar në zero rreshta të dhënash që do të paraqiten në analizën multivariate. Kjo situatë është e zakonshme.
Ky diskutim i shkurtër nuk është i mjaftueshëm për të peshuar të mirat dhe të këqijat e përdorimit të fshirjes në listë. Megjithatë, tani do të jeni të vetëdijshëm kur të hasni problemin e analizës së zero rasteve. Jini gjithashtu në vëzhgim për momentet kur analizohen shumë më pak raste nga sa prisnit. Në dialogun Opsione të dialogut të Regresionit Linear, fshirja sipas listës është e paracaktuar. Kini kujdes që të mos zgjidhni rastësisht midis zgjedhjeve të tjera derisa regresioni të funksionojë. Në vend të kësaj, kuptoni opsionet e tjera përpara se t'i provoni.
Aftësitë tuaja SPSS po përparojnë mirë dhe ju vendosni se është koha të provoni Sintaksën SPSS. Ju kontrolloni dy herë punën tuaj, ekzekutoni sintaksën dhe ndesheni me paralajmërimin e treguar këtu. Ju konfirmoni që keni të dhënat e nevojshme dhe variablin e nevojshëm. Çfarë ka ndodhur?

Paralajmërim: Mungojnë variablat e nevojshëm.
Pothuajse me siguri, ju keni dy (ose më shumë) grupe të dhënash të hapura dhe keni humbur gjurmët se cili prej tyre është aktiv. Kur jeni duke punuar në ndërfaqen grafike të përdoruesit, është praktikisht e pamundur të ngatërroheni, sepse kur hyni te menytë dhe dialogët, në përgjithësi e bëni këtë nga dritarja e Redaktuesit të të Dhënave. Megjithatë, kur përdorni Sintaksë SPSS, po ekzekutoni kodin dhe nuk ka asnjë garanci që elementët e nevojshëm të të dhënave janë të pranishme. Ja çfarë duhet të bëni: Kontrolloni për të parë nëse keni më shumë se një grup të dhënash të hapur dhe sigurohuni që grupi i të dhënave që ju nevojitet është grupi i të dhënave aktive. Dritarja e sintaksës ka treguesin e mëposhtëm:
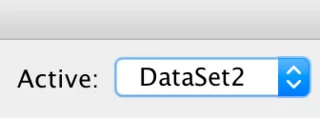
DataSet1 është thjesht grupi i të dhënave që hapët së pari. Për të kaluar në DataSet2, thjesht klikoni shigjetat dhe zgjidhni atë. Ju mund të caktoni grupin e të dhënave që ju nevojitet gjithashtu duke përdorur bitin e sintaksës së mëposhtme: TË DHËNAT AKTIVIZO grupin e të dhënave1.
Një gabim i zakonshëm ndodh kur keni të bëni me një komandë që qëndron në fuqi derisa të udhëzoni në mënyrë eksplicite SPSS për ta fikur atë. Tre nga këto komanda janë Select, Split dhe Weight, të cilat janë disi të pazakonta në SPSS, sepse ato zakonisht shoqërohen me një rregullim të përkohshëm të një analize, jo me një ndryshim të përhershëm të të dhënave. Pesha është më teknike dhe më shpesh lidhet me analizën e anketimit. Këtu është një shpjegim i shpejtë i secilit:
Përdorimi efektiv i të treve kërkon më shumë sesa thjesht një përkufizim të shpejtë. Megjithatë, kontrollimi për të parë nëse ato janë ende të ndezura është i lehtë, për shkak të një treguesi në këndin e poshtëm djathtas të dritares së Redaktuesit të të Dhënave. Treguesi i filtrit i referohet operacioneve në dialogun Zgjidh rastet. Treguesit Weight dhe Split By i referohen dialogëve Pesha dhe Ndarja, përkatësisht. (Unicode i referohet sistemit të kodimit të përdorur nga SPSS, i cili zakonisht nuk është i përkohshëm, megjithëse mund ta ndryshoni këtë në menynë Edit→Options.)

Treguesit e filtrit, peshimit dhe ndarjes.
Nëse SPSS po sillet çuditërisht dhe nuk po merrni rezultatet që prisni, kontrolloni këta tregues. Për të fikur një tregues, kthehuni te dialogu ku keni dhënë udhëzimin origjinal.
Një gabim i zakonshëm është përdorimi aksidental i Select dhe Split në të njëjtën kohë. (Përdoruesit e fuqishëm të SPSS mund ta bëjnë këtë qëllimisht, por vetëm rrallë.) Në veçanti, nuk është kurrë një ide e mirë të përdorni Select dhe Split në të njëjtën ndryshore në të njëjtën kohë. Nëse e bëni këtë, do të shfaqen shumë paralajmërime në dritaren e SPSS Output Viewer.
Slack është një mjet i shkëlqyer bashkëpunimi. Gati për të krijuar një grup përdoruesish? Ky udhëzues ju udhëzon gjatë procesit për këtë veçori të planit premium.
Në QuickBooks 2010, ju përdorni një listë të shitësve për të mbajtur shënime për shitësit tuaj. Lista e shitësve ju lejon të grumbulloni dhe regjistroni informacione, si adresa e shitësit, personi i kontaktit, etj. Mund të shtoni një shitës në listën tuaj të shitësve në disa hapa të thjeshtë.
QuickBooks 2010 e bën të lehtë për kontabilistët të punojnë me skedarët e të dhënave të klientit. Mund të përdorni veçorinë e Kopjimit të Kontabilistit në QuickBooks thjesht për t'i dërguar me e-mail (ose kërmilli) llogaritarit tuaj një kopje të skedarit të të dhënave QuickBooks. Ju krijoni kopjen e kontabilistit të skedarit të të dhënave QuickBooks duke përdorur versionin tuaj të QuickBooks dhe origjinalin […]
Për të futur një faturë që merrni nga një shitës, përdorni transaksionin e faturave të QuickBook Online. QBO gjurmon faturën si të pagueshme, e cila është një detyrim i biznesit tuaj – para që i detyroheni por nuk i keni paguar ende. Shumica e kompanive që hyjnë në transaksionet e faturave e bëjnë këtë sepse marrin një numër të drejtë faturash dhe […]
QuickBooks Online dhe QuickBooks Online Accountant përmbajnë një mjet të quajtur bashkëpunëtor i klientit që mund ta përdorni për të komunikuar me klientin tuaj në lidhje me transaksionet ekzistuese. Klienti bashkëpunëtor është një mjet i dyanshëm; ju ose klienti juaj mund të dërgoni një mesazh dhe marrësi i mesazhit mund të përgjigjet. Mendoni për bashkëpunëtorin e klientit si një mënyrë për të […]
Mësoni rreth Slack, i cili ju mundëson të komunikoni dhe të bashkëpunoni me kolegët brenda dhe jashtë organizatës suaj.
QuickBooks ofron më shumë se 100 pasqyra financiare dhe raporte kontabël. Ju arrini te këto raporte duke hapur menynë Raporte. Menyja e Raporteve rregullon raportet në afërsisht një duzinë kategorish, duke përfshirë kompanitë dhe financat, klientët dhe të arkëtueshmet, shitjet, punët dhe kohën dhe kilometrazhin. Për të prodhuar pothuajse çdo raport të disponueshëm përmes Raporteve […]
Kostoja e bazuar në aktivitet (shkurt ABC) mund të jetë ideja më e mirë e re e kontabilitetit në tre dekadat e fundit. Qasja është me të vërtetë e drejtpërdrejtë nëse tashmë keni përdorur QuickBooks. Me pak fjalë, gjithçka që bëni për të zbatuar një sistem të thjeshtë ABC në QuickBooks është ajo që po bëni tani. Me fjalë të tjera, thjesht vazhdoni të gjurmoni […]
QuickBooks ju lejon të shpenzoni më pak kohë në mbajtjen e kontabilitetit dhe më shumë kohë në biznesin tuaj. Duke përdorur shkurtore, do të kaloni nëpër kontabilitet edhe më shpejt dhe më lehtë.
Në kompanitë e mëdha me qindra ose mijëra punonjës, dy ose tre persona shpenzojnë pjesën më të madhe ose edhe të gjithë vitin e tyre duke punuar me të dhënat e buxhetuara. Për të modifikuar një buxhet ekzistues në QuickBooks, ndiqni këto hapa:







