Algoritmi in umetna inteligenca so spremenili podatkovno igro. Človeška rasa je zdaj na neverjetnem presečišču neverjetnih količin podatkov, ki jih ustvarja vedno manjša in zmogljiva strojna oprema. Podatke vse pogosteje obdelujejo in analizirajo isti računalniki, ki jih je proces pomagal širiti in razvijati. Ta izjava se morda zdi očitna, vendar so podatki postali tako vseprisotni, da njihova vrednost ni več le v informacijah, ki jih vsebujejo (kot je primer podatkov, shranjenih v bazi podatkov podjetja, ki omogoča njegovo vsakodnevno delovanje), temveč v njihovi uporabi kot pomeni ustvarjanje novih vrednot; takšni podatki so opisani kot »novo olje«. Te nove vrednosti večinoma obstajajo v tem, kako aplikacije manikurajo, shranjujejo in pridobivajo podatke ter v tem, kako jih dejansko uporabljate s pomočjo pametnih algoritmov.
Algoritmi umetne inteligence so na svoji poti preizkušali različne pristope, prehajali so od preprostih algoritmov do simbolnega sklepanja, ki temelji na logiki, in nato do ekspertnih sistemov. V zadnjih letih so postale nevronske mreže in v svoji najbolj zreli obliki globoko učenje. Ko se je ta metodološki odlomek zgodil, so se podatki iz informacij, ki jih obdelujejo vnaprej določeni algoritmi, spremenili v tisto, kar je algoritem oblikovalo v nekaj uporabnega za nalogo. Podatki so se spremenili iz le surovine, ki je poganjala rešitev, v ustvarjalca same rešitve, kot je prikazano tukaj.
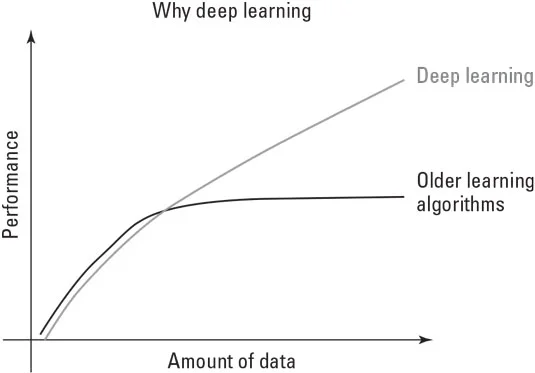
S sedanjimi rešitvami umetne inteligence več podatkov pomeni več inteligence.
Tako je postala fotografija nekaterih vaših mačk vse bolj uporabna ne le zaradi svoje afektivne vrednosti – ki prikazuje vaše ljubke male mačke – ampak zato, ker bi lahko postala del učnega procesa AI, ki odkriva splošnejše koncepte, na primer kakšne značilnosti označuje mačko ali razumevanje, kaj opredeljuje srčkan.
V širšem obsegu podjetje, kot je Google, hrani svoje algoritme iz prosto dostopnih podatkov, kot je vsebina spletnih mest ali besedilo v javno dostopnih besedilih in knjigah. Programska oprema Google spider išče po spletu, skače s spletnega mesta na spletno mesto in pridobi spletne strani z vsebino besedila in slik. Tudi če Google vrne del podatkov uporabnikom kot rezultate iskanja, iz podatkov izlušči druge vrste informacij s svojimi algoritmi umetne inteligence, ki se iz njih učijo, kako doseči druge cilje.
Algoritmi, ki obdelujejo besede, lahko pomagajo Googlovim sistemom AI razumeti in predvideti vaše potrebe, tudi če jih ne izrazite v nizu ključnih besed, ampak v preprostem, nejasnem naravnem jeziku, jeziku, ki ga govorimo vsak dan (in ja, vsakdanji jezik je pogosto nejasen) . Če trenutno poskušate Googlovemu iskalniku zastaviti vprašanja, ne le verige ključnih besed, boste opazili, da ponavadi odgovarja pravilno. Od leta 2012, z uvedbo posodobitve Hummingbird, je Google bolje razumel sopomenke in koncepte, nekaj, kar presega začetne podatke, ki jih je pridobil, in to je rezultat procesa umetne inteligence. V Googlu obstaja še naprednejši algoritem, imenovan RankBrain, ki se vsak dan uči neposredno iz milijonov poizvedb in lahko odgovori na dvoumne ali nejasne iskalne poizvedbe, celo izražene v slengu ali pogovornih izrazih ali preprosto prežete z napakami. RankBrain ne servisira vseh poizvedb, vendar se iz podatkov uči, kako bolje odgovoriti na poizvedbe. Obravnava že 15 odstotkov poizvedb motorja, v prihodnosti pa bi ta odstotek lahko postal 100-odstoten.



