Kaip naudoti antraštes ir poraštes „Microsoft Word“.

„Microsoft Word“ galite sukurti antraštes ir poraštes, kurios kiekvieno puslapio viršuje arba apačioje kartotų tą patį tekstą.
Algoritmai ir AI pakeitė duomenų žaidimą. Žmonių rasė dabar yra neįtikėtinoje precedento neturinčio duomenų kiekio sankirtoje, kurią generuoja vis mažesnė ir galingesnė aparatinė įranga. Duomenis taip pat vis dažniau apdoroja ir analizuoja tie patys kompiuteriai, kuriuos šis procesas padėjo skleisti ir vystyti. Šis teiginys gali atrodyti akivaizdus, tačiau duomenys tapo tokie visur paplitę, kad jų vertė slypi ne tik juose esančioje informacijoje (pavyzdžiui, duomenys, saugomi įmonės duomenų bazėje, leidžiančioje atlikti kasdienes operacijas), bet veikiau tai, kad jie naudojami kaip priemones kurti naujas vertybes; tokie duomenys apibūdinami kaip „nauja nafta“. Šios naujos reikšmės dažniausiai yra susijusios su tuo, kaip programos tvarko, saugo ir nuskaito duomenis, ir kaip jūs iš tikrųjų juos naudojate naudodami išmaniuosius algoritmus.
Dirbtinio intelekto algoritmai išbandė įvairius metodus, nuo paprastų algoritmų pereidami prie simbolinio samprotavimo, pagrįsto logika, o vėliau prie ekspertų sistemų. Pastaraisiais metais jie tapo neuroniniais tinklais, o brandžiausia forma – giluminiu mokymusi. Vykstant šiai metodologinei ištraukai, duomenys iš iš anksto nustatytų algoritmų apdorotos informacijos tapo tuo, kas algoritmą pavertė kažkuo naudingu užduočiai atlikti. Kaip parodyta čia, duomenys tapo tik žaliava, kuri paskatino sprendimą.
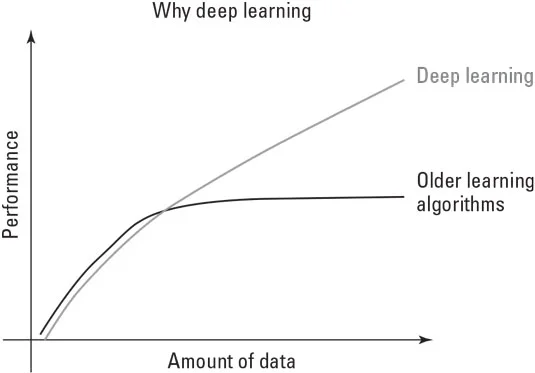
Naudojant dabartinius AI sprendimus, daugiau duomenų reiškia daugiau intelekto.
Taigi kai kurių jūsų kačiukų nuotrauka tapo vis naudingesnė ne tik dėl savo emocinės vertės – vaizduojančios jūsų mielas mažas kates, bet ir todėl, kad ji gali tapti AI mokymosi proceso dalimi, atrandant bendresnes sąvokas, pvz., kokias savybes. reiškia katę arba supratimą, kas apibrėžia mielą.
Didesniu mastu tokia įmonė kaip „Google“ savo algoritmus maitina iš laisvai prieinamų duomenų, pvz., svetainių turinio ar teksto, esančio viešai prieinamuose tekstuose ir knygose. „Google Spider“ programinė įranga tikrina žiniatinklį, peršokdama iš vienos svetainės į kitą, nuskaitydama tinklalapius su teksto ir vaizdų turiniu. Net jei „Google“ grąžina dalį duomenų naudotojams kaip paieškos rezultatus, ji iš duomenų ištraukia kitos rūšies informaciją naudodama savo AI algoritmus, kurie iš jų mokosi, kaip pasiekti kitus tikslus.
Algoritmai, kurie apdoroja žodžius, gali padėti Google AI sistemoms suprasti ir numatyti jūsų poreikius net tada, kai juos išreiškiate ne raktinių žodžių rinkiniu, o paprasta, neaiškia natūralia kalba – kalba, kuria kalbame kiekvieną dieną (ir taip, kasdienė kalba dažnai būna neaiški) . Jei šiuo metu bandysite „Google“ paieškos sistemai užduoti klausimus, o ne tik raktinių žodžių grandines, pastebėsite, kad ji paprastai atsako teisingai. Nuo 2012 m., kai buvo pristatytas Hummingbird atnaujinimas, „Google“ galėjo geriau suprasti sinonimus ir sąvokas – tai, kas viršija pradinius jos gautus duomenis, ir tai yra AI proceso rezultatas. Google egzistuoja dar pažangesnis algoritmas, pavadintas RankBrain, kuris kasdien mokosi tiesiogiai iš milijonų užklausų ir gali atsakyti į dviprasmiškas ar neaiškias paieškos užklausas, net išreikštas žargonu ar šnekamąja kalba arba tiesiog apimtas klaidų. RankBrain neaptarnauja visų užklausų, bet iš duomenų mokosi, kaip geriau atsakyti į užklausas. Jau dabar jis apdoroja 15 procentų variklio užklausų, o ateityje šis procentas gali tapti 100 procentų.
„Microsoft Word“ galite sukurti antraštes ir poraštes, kurios kiekvieno puslapio viršuje arba apačioje kartotų tą patį tekstą.
Sužinokite, kaip prisijungti prie „Discord“ serverio, kad galėtumėte prisijungti prie bendruomenių ir dalintis savo interesais.
Pirmasis jūsų darbas naudojant šią naują platformą – pirmiausia prisistatyti „Discord“. Sužinokite, kaip nustatyti „Discord“ serverio paskyrą.
Sužinokite, kaip bendrinti ekraną „Zoom“ platformoje su kitais, kaip leisti jiems valdyti jūsų ekraną ir kaip paprašyti valdyti pagrindinio kompiuterio ekraną.
Formulė yra matematinis skaičiavimas. Sužinokite, kaip rašyti Excel formules ir efektyviai jas naudoti.
Sužinokite, kaip išsiųsti kvietimus ir sukurti savo internetinę bendruomenę „Discord“ serveryje. Taip pat sužinokite, kaip srautinis perdavimas padeda skleisti informaciją jūsų „Discord“.
Sužinokite, kaip galima lengvai ir efektyviai reguliuoti tarpus tarp eilučių „Microsoft Word“ naudojant įvairias nustatymų parinktis.
Sužinokite, kaip lengvai sukurti kompiuterio failo ar aplanko nuorodą darbalaukyje. Šis procesas suteikia greitą prieigą prie dažniausiai naudojamų programų ir dokumentų.
Iliustracija yra iš anksto nupieštas bendras meno kūrinys, o „Microsoft“ su „Office“ produktais nemokamai teikia daug iliustracijų failų. Galite įterpti iliustraciją į savo „PowerPoint“ skaidrės maketą. Lengviausias būdas įterpti iliustraciją yra naudoti vieną iš vietos rezervavimo ženklų skaidrės makete: Rodyti skaidrę, kurioje yra iliustracija […]
Užpildymo spalva (dar vadinama šešėliavimu) yra spalva arba raštas, užpildantis vienos ar kelių „Excel“ darbalapio langelių foną. Tamsinimas gali padėti skaitytojo akims sekti informaciją visame puslapyje ir suteikti darbalapiui spalvų bei vizualinio susidomėjimo. Kai kurių tipų skaičiuoklėse, pavyzdžiui, čekių knygelės registre, […]








