Алгоритмите и AI промениха играта с данни. Човешката раса сега е на невероятно пресечна точка на безпрецедентни обеми данни, генерирани от все по-малък и мощен хардуер. Данните също се обработват и анализират все повече от същите компютри, на които процесът помогна за разпространението и развитието. Това твърдение може да изглежда очевидно, но данните са станали толкова повсеместни, че тяхната стойност вече не се крие само в информацията, която съдържа (като случая на данни, съхранявани в базата данни на фирмата, която позволява ежедневните й операции), а по-скоро в използването им като средства за създаване на нови ценности; такива данни се описват като „новото масло“. Тези нови стойности съществуват най-вече в това как приложенията маникюрират, съхраняват и извличат данни и в това как всъщност ги използвате с помощта на интелигентни алгоритми.
Алгоритмите на AI са изпробвали различни подходи по пътя, преминавайки от прости алгоритми към символни разсъждения, базирани на логика, и след това към експертни системи. През последните години те се превърнаха в невронни мрежи и, в най-зрялата си форма, дълбоко обучение. Когато се случи този методологически пасаж, данните се превърнаха от информация, обработена от предварително определени алгоритми, в това, което оформи алгоритъма в нещо полезно за задачата. Данните се превърнаха от просто суровината, която подхранваше решението, към майстора на самото решение, както е показано тук.
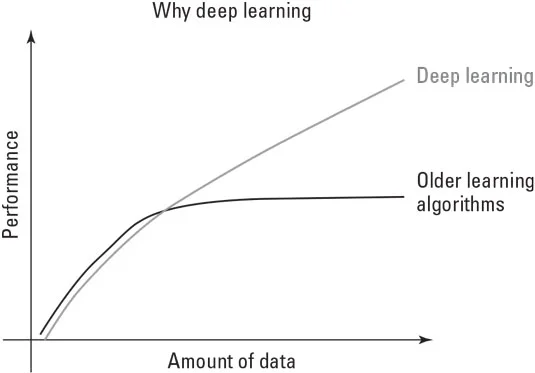
С настоящите AI решения, повече данни се равнява на повече интелигентност.
По този начин снимка на някои от вашите котенца става все по-полезна не просто поради своята емоционална стойност - изобразяваща вашите сладки малки котки - но защото може да стане част от процеса на обучение на AI, който открива по-общи концепции, като например какви характеристики обозначават котка или разбиране какво определя сладък.
В по-голям мащаб компания като Google захранва своите алгоритми от свободно достъпни данни, като съдържанието на уебсайтове или текста, намерен в публично достъпни текстове и книги. Софтуерът Google spider обхожда мрежата, скача от уебсайт на уебсайт, извлича уеб страници със съдържанието им от текст и изображения. Дори ако Google върне част от данните на потребителите като резултати от търсенето, той извлича други видове информация от данните, използвайки своите алгоритми за изкуствен интелект, които се учат от тях как да постигнат други цели.
Алгоритмите, които обработват думи, могат да помогнат на системите за изкуствен интелект на Google да разберат и предвидят вашите нужди, дори когато не ги изразявате с набор от ключови думи, а на обикновен, неясен естествен език, езикът, който говорим всеки ден (и да, ежедневният език често е неясен) . Ако в момента се опитвате да задавате въпроси, а не само вериги от ключови думи, на търсачката на Google, ще забележите, че тя има тенденция да отговаря правилно. От 2012 г., с въвеждането на актуализацията Hummingbird, Google стана по-способен да разбира синоними и понятия, нещо, което надхвърля първоначалните данни, които е придобил, и това е резултат от AI процес. В Google съществува още по-усъвършенстван алгоритъм, наречен RankBrain, който се учи директно от милиони заявки всеки ден и може да отговори на двусмислени или неясни заявки за търсене, дори изразени в жаргонни или разговорни термини или просто с грешки. RankBrain не обслужва всички заявки, но се учи от данните как да отговаря по-добре на запитвания. Той вече обработва 15 процента от заявките на двигателя, а в бъдеще този процент може да стане 100 процента.



