Algoritmi i AI promijenili su podatkovnu igru. Ljudska se rasa sada nalazi na nevjerojatnom sjecištu neviđenih količina podataka, generiranih sve manjim i snažnijim hardverom. Podatke također sve više obrađuju i analiziraju ista računala kojima je proces pomogao u širenju i razvoju. Ova izjava može se činiti očitom, ali podaci su postali toliko sveprisutni da njihova vrijednost više nije samo u informacijama koje sadrže (kao što je slučaj podataka pohranjenih u bazi podataka tvrtke koja omogućuje njezino svakodnevno poslovanje), već u njihovoj upotrebi kao znači stvoriti nove vrijednosti; takvi se podaci opisuju kao "nova nafta". Ove nove vrijednosti uglavnom postoje u načinu na koji aplikacije manikuraju, pohranjuju i dohvaćaju podatke te u tome kako ih zapravo koristite pomoću pametnih algoritama.
Algoritmi umjetne inteligencije isprobali su različite pristupe na putu, prelazeći od jednostavnih algoritama do simboličkog zaključivanja temeljenog na logici, a zatim do ekspertnih sustava. Posljednjih godina postali su neuronske mreže i, u svom najzrelijem obliku, duboko učenje. Kako se ovaj metodološki odlomak dogodio, podaci su se iz informacija koje obrađuju unaprijed određeni algoritmi pretvorili u ono što je oblikovalo algoritam u nešto korisno za zadatak. Podaci su se pretvorili od samo sirovine koja je potaknula rješenje u majstora samog rješenja, kao što je ovdje prikazano.
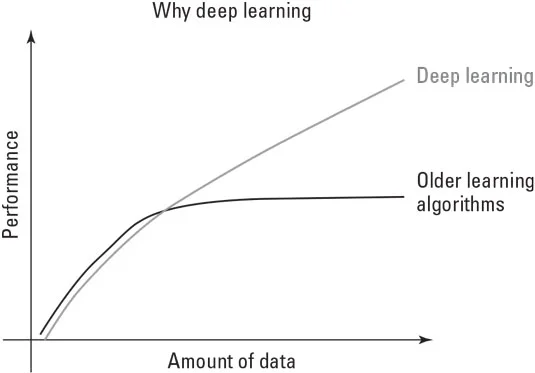
S sadašnjim AI rješenjima, više podataka jednako je više inteligencije.
Stoga je fotografija nekih vaših mačića postala sve korisnija ne samo zbog svoje afektivne vrijednosti – koja prikazuje vaše slatke male mačke – već zato što bi mogla postati dio procesa učenja umjetne inteligencije koja otkriva općenitije koncepte, kao što su karakteristike označavaju mačku, odnosno razumijevanje onoga što definira slatko.
U većoj mjeri, tvrtka poput Googlea hrani svoje algoritme iz slobodno dostupnih podataka, poput sadržaja web stranica ili teksta koji se nalazi u javno dostupnim tekstovima i knjigama. Softver Google spider indeksira web, skače s web-mjesta na web-mjesto, dohvaćajući web-stranice s njihovim sadržajem teksta i slika. Čak i ako Google vraća dio podataka korisnicima kao rezultate pretraživanja, iz podataka izvlači druge vrste informacija koristeći svoje AI algoritme, koji iz njih uče kako postići druge ciljeve.
Algoritmi koji obrađuju riječi mogu pomoći Googleovim AI sustavima razumjeti i predvidjeti vaše potrebe čak i kada ih ne izražavate skupom ključnih riječi, već jednostavnim, nejasnim prirodnim jezikom, jezikom kojim govorimo svaki dan (i da, svakodnevni jezik je često nejasan) . Ako trenutačno pokušavate postavljati pitanja, a ne samo niz ključnih riječi, Google tražilici, primijetit ćete da ona obično odgovara točno. Od 2012., s uvođenjem ažuriranja Hummingbird, Google je bolje razumio sinonime i pojmove, nešto što nadilazi početne podatke koje je prikupio, a to je rezultat AI procesa. Još napredniji algoritam postoji u Googleu, pod nazivom RankBrain, koji uči izravno iz milijuna upita svaki dan i može odgovoriti na dvosmislene ili nejasne upite za pretraživanje, čak izražene slengom ili kolokvijalnim izrazima ili jednostavno opterećene pogreškama. RankBrain ne servisira sve upite, ali uči iz podataka kako bolje odgovoriti na upite. Već obrađuje 15 posto upita motora, au budućnosti bi taj postotak mogao postati 100 posto.



