Algoritmet dhe AI ndryshuan lojën e të dhënave. Raca njerëzore është tani në një kryqëzim të jashtëzakonshëm të vëllimeve të paprecedentë të të dhënave, të krijuara nga një pajisje gjithnjë e më e vogël dhe e fuqishme. Të dhënat gjithashtu përpunohen dhe analizohen gjithnjë e më shumë nga të njëjtët kompjuterë që procesi ndihmoi në përhapjen dhe zhvillimin. Kjo deklaratë mund të duket e qartë, por të dhënat janë bërë kaq të kudondodhura saqë vlera e tyre nuk qëndron më vetëm në informacionin që përmban (siç është rasti i të dhënave të ruajtura në bazën e të dhënave të një firme që lejon operacionet e saj të përditshme), por më tepër në përdorimin e saj si do të thotë për të krijuar vlera të reja; të dhëna të tilla përshkruhen si "vaji i ri". Këto vlera të reja kryesisht ekzistojnë në mënyrën se si aplikacionet manikyrojnë, ruajnë dhe marrin të dhëna, dhe në mënyrën se si i përdorni ato me anë të algoritmeve inteligjente.
Algoritmet e AI kanë provuar qasje të ndryshme gjatë rrugës, duke kaluar nga algoritmet e thjeshta në arsyetimin simbolik të bazuar në logjikë dhe më pas në sistemet eksperte. Vitet e fundit, ato u bënë rrjete nervore dhe, në formën e tyre më të pjekur, mësim i thellë. Ndërsa ndodhi ky pasazh metodologjik, të dhënat u kthyen nga informacioni i përpunuar nga algoritme të paracaktuara në ato që e formuan algoritmin në diçka të dobishme për detyrën. Të dhënat u kthyen nga thjesht lënda e parë që ushqeu zgjidhjen në vetë artizanin e zgjidhjes, siç tregohet këtu.
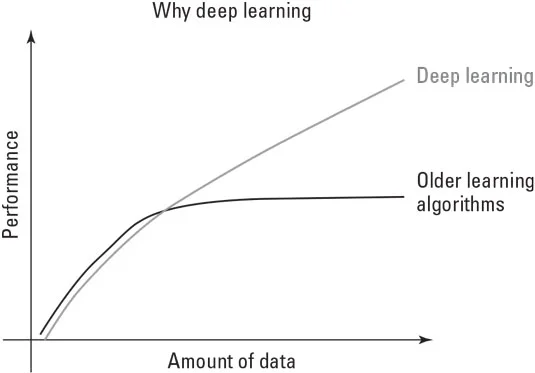
Me zgjidhjet aktuale të AI, më shumë të dhëna barazohen me më shumë inteligjencë.
Kështu, një foto e disa prej koteleve tuaja është bërë gjithnjë e më e dobishme jo thjesht për shkak të vlerës së saj afektive - duke përshkruar macet tuaja të vogla të lezetshme - por sepse mund të bëhet pjesë e procesit të të mësuarit të një AI që zbulon koncepte më të përgjithshme, si për shembull cilat karakteristika tregojnë një mace, ose të kuptuarit e asaj që përcakton bukurinë.
Në një shkallë më të madhe, një kompani si Google ushqen algoritmet e saj nga të dhënat e disponueshme lirisht, të tilla si përmbajtja e faqeve të internetit ose teksti që gjendet në tekste dhe libra të disponueshëm publikisht. Softueri Google spider zvarritet në ueb, duke u hedhur nga uebsajti në uebsajt, duke marrë faqet e internetit me përmbajtjen e tyre të tekstit dhe imazheve. Edhe nëse Google u kthen përdoruesve një pjesë të të dhënave si rezultate kërkimi, ai nxjerr lloje të tjera informacioni nga të dhënat duke përdorur algoritmet e tij të AI, të cilat mësojnë prej tyre se si të arrijnë objektiva të tjerë.
Algoritmet që përpunojnë fjalët mund të ndihmojnë sistemet e Google AI të kuptojnë dhe të parashikojnë nevojat tuaja edhe kur nuk po i shprehni ato me një sërë fjalësh kyçe, por në një gjuhë të thjeshtë, të paqartë natyrore, gjuhën që flasim çdo ditë (dhe po, gjuha e përditshme shpesh është e paqartë) . Nëse aktualisht përpiqeni t'i parashtroni pyetje, jo vetëm zinxhirë fjalësh kyçe, motorit të kërkimit Google, do të vini re se ai priret të përgjigjet saktë. Që nga viti 2012, me prezantimin e përditësimit Hummingbird, Google u bë më i aftë për të kuptuar sinonimet dhe konceptet, diçka që shkon përtej të dhënave fillestare që mori, dhe ky është rezultat i një procesi AI. Një algoritëm edhe më i avancuar ekziston në Google, i quajtur RankBrain, i cili mëson drejtpërdrejt nga miliona pyetje çdo ditë dhe mund t'u përgjigjet pyetjeve të paqarta ose të paqarta të kërkimit, madje të shprehura në terma zhargon ose bisedë ose thjesht të mbushur me gabime. RankBrain nuk i shërben të gjitha pyetjeve, por mëson nga të dhënat se si t'u përgjigjet më mirë pyetjeve. Ai tashmë trajton 15 për qind të pyetjeve të motorit dhe në të ardhmen, kjo përqindje mund të bëhet 100 për qind.



